 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit World Models for Reliable Human-Robot Collaboration
Jan 05, 2026This paper addresses the topic of robustness under sensing noise, ambiguous instructions, and human-robot interaction. We take a radically different tack to the issue of reliable embodied AI: instead of focusing on formal verification methods aimed at achieving model predictability and robustness, we emphasise the dynamic, ambiguous and subjective nature of human-robot interactions that requires embodied AI systems to perceive, interpret, and respond to human intentions in a manner that is consistent, comprehensible and aligned with human expectations. We argue that when embodied agents operate in human environments that are inherently social, multimodal, and fluid, reliability is contextually determined and only has meaning in relation to the goals and expectations of humans involved in the interaction. This calls for a fundamentally different approach to achieving reliable embodied AI that is centred on building and updating an accessible "explicit world model" representing the common ground between human and AI, that is used to align robot behaviours with human expectations.
VG-TVP: Multimodal Procedural Planning via Visually Grounded Text-Video Prompting
Dec 16, 2024



Large Language Model (LLM)-based agents have shown promise in procedural tasks, but the potential of multimodal instructions augmented by texts and videos to assist users remains under-explored. To address this gap, we propose the Visually Grounded Text-Video Prompting (VG-TVP) method which is a novel LLM-empowered Multimodal Procedural Planning (MPP) framework. It generates cohesive text and video procedural plans given a specified high-level objective. The main challenges are achieving textual and visual informativeness, temporal coherence, and accuracy in procedural plans. VG-TVP leverages the zero-shot reasoning capability of LLMs, the video-to-text generation ability of the video captioning models, and the text-to-video generation ability of diffusion models. VG-TVP improves the interaction between modalities by proposing a novel Fusion of Captioning (FoC) method and using Text-to-Video Bridge (T2V-B) and Video-to-Text Bridge (V2T-B). They allow LLMs to guide the generation of visually-grounded text plans and textual-grounded video plans. To address the scarcity of datasets suitable for MPP, we have curated a new dataset called Daily-Life Task Procedural Plans (Daily-PP). We conduct comprehensive experiments and benchmarks to evaluate human preferences (regarding textual and visual informativeness, temporal coherence, and plan accuracy). Our VG-TVP method outperforms unimodal baselines on the Daily-PP dataset.
DOTA: Distributional Test-Time Adaptation of Vision-Language Models
Sep 28, 2024



Vision-language foundation models (e.g., CLIP) have shown remarkable performance across a wide range of tasks. However, deploying these models may be unreliable when significant distribution gaps exist between the training and test data. The training-free test-time dynamic adapter (TDA) is a promising approach to address this issue by storing representative test samples to guide the classification of subsequent ones. However, TDA only naively maintains a limited number of reference samples in the cache, leading to severe test-time catastrophic forgetting when the cache is updated by dropping samples. In this paper, we propose a simple yet effective method for DistributiOnal Test-time Adaptation (Dota). Instead of naively memorizing representative test samples, Dota continually estimates the distributions of test samples, allowing the model to continually adapt to the deployment environment. The test-time posterior probabilities are then computed using the estimated distributions based on Bayes' theorem for adaptation purposes. To further enhance the adaptability on the uncertain samples, we introduce a new human-in-the-loop paradigm which identifies uncertain samples, collects human-feedback, and incorporates it into the Dota framework. Extensive experiments validate that Dota enables CLIP to continually learn, resulting in a significant improvement compared to current state-of-the-art methods.
VideoLLM-MoD: Efficient Video-Language Streaming with Mixture-of-Depths Vision Computation
Aug 29, 2024



A well-known dilemma in large vision-language models (e.g., GPT-4, LLaVA) is that while increasing the number of vision tokens generally enhances visual understanding, it also significantly raises memory and computational costs, especially in long-term, dense video frame streaming scenarios. Although learnable approaches like Q-Former and Perceiver Resampler have been developed to reduce the vision token burden, they overlook the context causally modeled by LLMs (i.e., key-value cache), potentially leading to missed visual cues when addressing user queries. In this paper, we introduce a novel approach to reduce vision compute by leveraging redundant vision tokens "skipping layers" rather than decreasing the number of vision tokens. Our method, VideoLLM-MoD, is inspired by mixture-of-depths LLMs and addresses the challenge of numerous vision tokens in long-term or streaming video. Specifically, for each transformer layer, we learn to skip the computation for a high proportion (e.g., 80\%) of vision tokens, passing them directly to the next layer. This approach significantly enhances model efficiency, achieving approximately \textasciitilde42\% time and \textasciitilde30\% memory savings for the entire training. Moreover, our method reduces the computation in the context and avoid decreasing the vision tokens, thus preserving or even improving performance compared to the vanilla model. We conduct extensive experiments to demonstrate the effectiveness of VideoLLM-MoD, showing its state-of-the-art results on multiple benchmarks, including narration, forecasting, and summarization tasks in COIN, Ego4D, and Ego-Exo4D datasets.
Skip : A Simple Method to Reduce Hallucination in Large Vision-Language Models
Feb 12, 2024Recent advancements in large vision-language models (LVLMs) have demonstrated impressive capability in visual information understanding with human language. Despite these advances, LVLMs still face challenges with multimodal hallucination, such as generating text descriptions of objects that are not present in the visual information. However, the underlying fundamental reasons of multimodal hallucinations remain poorly explored. In this paper, we propose a new perspective, suggesting that the inherent biases in LVLMs might be a key factor in hallucinations. Specifically, we systematically identify a semantic shift bias related to paragraph breaks (\n\n), where the content before and after '\n\n' in the training data frequently exhibit significant semantic changes. This pattern leads the model to infer that the contents following '\n\n' should be obviously different from the preceding contents with less hallucinatory descriptions, thereby increasing the probability of hallucinatory descriptions subsequent to the '\n\n'. We have validated this hypothesis on multiple publicly available LVLMs. Besides, we find that deliberately inserting '\n\n' at the generated description can induce more hallucinations. A simple method is proposed to effectively mitigate the hallucination of LVLMs by skipping the output of '\n'.
Team I2R-VI-FF Technical Report on EPIC-KITCHENS VISOR Hand Object Segmentation Challenge 2023
Oct 31, 2023In this report, we present our approach to the EPIC-KITCHENS VISOR Hand Object Segmentation Challenge, which focuses on the estimation of the relation between the hands and the objects given a single frame as input. The EPIC-KITCHENS VISOR dataset provides pixel-wise annotations and serves as a benchmark for hand and active object segmentation in egocentric video. Our approach combines the baseline method, i.e., Point-based Rendering (PointRend) and the Segment Anything Model (SAM), aiming to enhance the accuracy of hand and object segmentation outcomes, while also minimizing instances of missed detection. We leverage accurate hand segmentation maps obtained from the baseline method to extract more precise hand and in-contact object segments. We utilize the class-agnostic segmentation provided by SAM and apply specific hand-crafted constraints to enhance the results. In cases where the baseline model misses the detection of hands or objects, we re-train an object detector on the training set to enhance the detection accuracy. The detected hand and in-contact object bounding boxes are then used as prompts to extract their respective segments from the output of SAM. By effectively combining the strengths of existing methods and applying our refinements, our submission achieved the 1st place in terms of evaluation criteria in the VISOR HOS Challenge.
Masked Diffusion with Task-awareness for Procedure Planning in Instructional Videos
Sep 14, 2023



A key challenge with procedure planning in instructional videos lies in how to handle a large decision space consisting of a multitude of action types that belong to various tasks. To understand real-world video content, an AI agent must proficiently discern these action types (e.g., pour milk, pour water, open lid, close lid, etc.) based on brief visual observation. Moreover, it must adeptly capture the intricate semantic relation of the action types and task goals, along with the variable action sequences. Recently, notable progress has been made via the integration of diffusion models and visual representation learning to address the challenge. However, existing models employ rudimentary mechanisms to utilize task information to manage the decision space. To overcome this limitation, we introduce a simple yet effective enhancement - a masked diffusion model. The introduced mask acts akin to a task-oriented attention filter, enabling the diffusion/denoising process to concentrate on a subset of action types. Furthermore, to bolster the accuracy of task classification, we harness more potent visual representation learning techniques. In particular, we learn a joint visual-text embedding, where a text embedding is generated by prompting a pre-trained vision-language model to focus on human actions. We evaluate the method on three public datasets and achieve state-of-the-art performance on multiple metrics. Code is available at https://github.com/ffzzy840304/Masked-PDPP.
Team VI-I2R Technical Report on EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2022
Jan 29, 2023



In this report, we present the technical details of our submission to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation (UDA) Challenge for Action Recognition 2022. This task aims to adapt an action recognition model trained on a labeled source domain to an unlabeled target domain. To achieve this goal, we propose an action-aware domain adaptation framework that leverages the prior knowledge induced from the action recognition task during the adaptation. Specifically, we disentangle the source features into action-relevant features and action-irrelevant features using the learned action classifier and then align the target features with the action-relevant features. To further improve the action prediction performance, we exploit the verb-noun co-occurrence matrix to constrain and refine the action predictions. Our final submission achieved the first place in terms of top-1 action recognition accuracy.
Visuo-Tactile Manipulation Planning Using Reinforcement Learning with Affordance Representation
Jul 14, 2022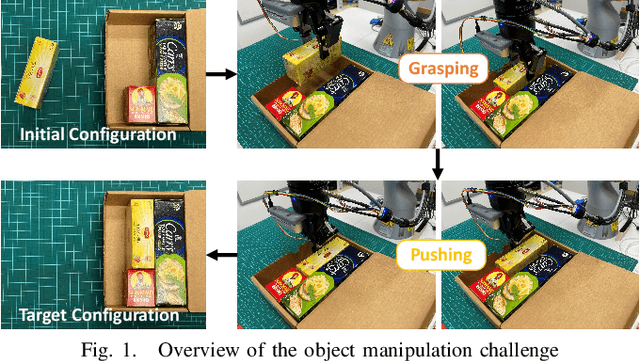
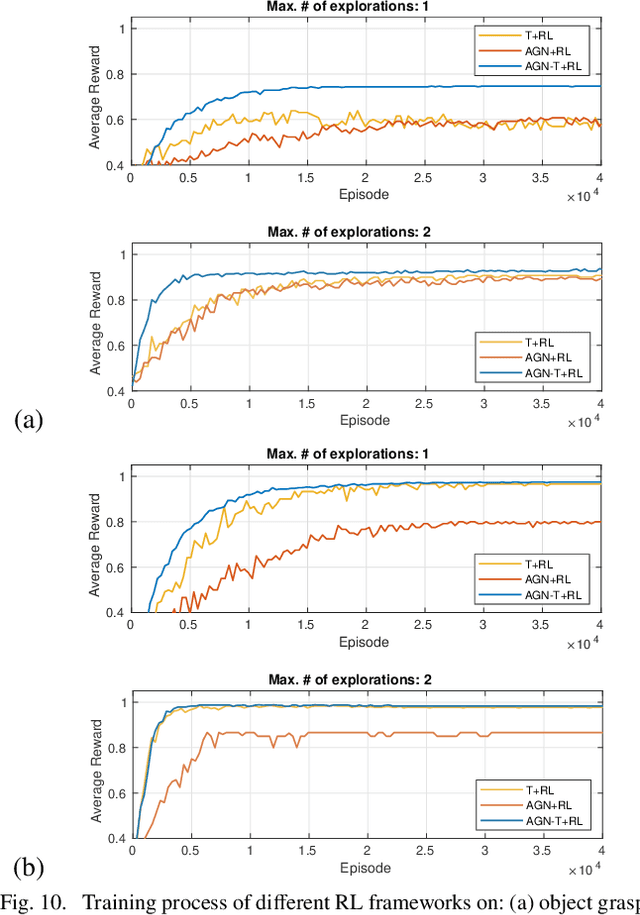
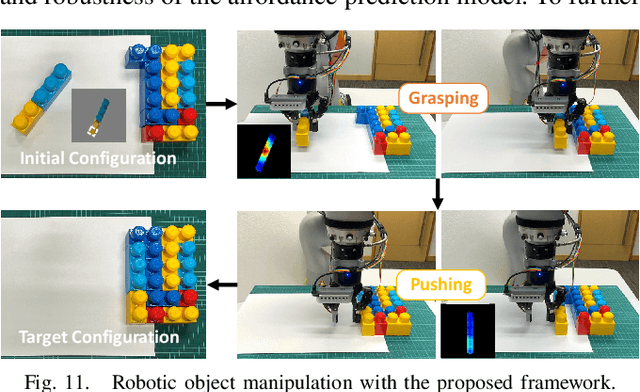
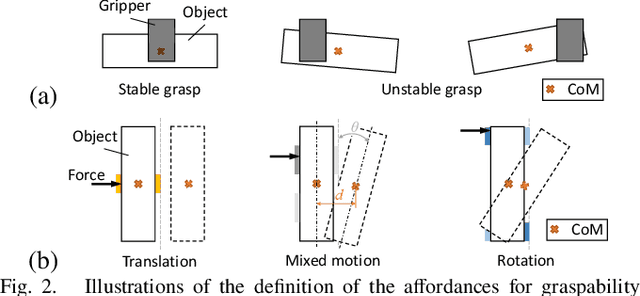
Robots are increasingly expected to manipulate objects in ever more unstructured environments where the object properties have high perceptual uncertainty from any single sensory modality. This directly impacts successful object manipulation. In this work, we propose a reinforcement learning-based motion planning framework for object manipulation which makes use of both on-the-fly multisensory feedback and a learned attention-guided deep affordance model as perceptual states. The affordance model is learned from multiple sensory modalities, including vision and touch (tactile and force/torque), which is designed to predict and indicate the manipulable regions of multiple affordances (i.e., graspability and pushability) for objects with similar appearances but different intrinsic properties (e.g., mass distribution). A DQN-based deep reinforcement learning algorithm is then trained to select the optimal action for successful object manipulation. To validate the performance of the proposed framework, our method is evaluated and benchmarked using both an open dataset and our collected dataset. The results show that the proposed method and overall framework outperform existing methods and achieve better accuracy and higher efficiency.
TAILOR: Teaching with Active and Incremental Learning for Object Registration
May 24, 2022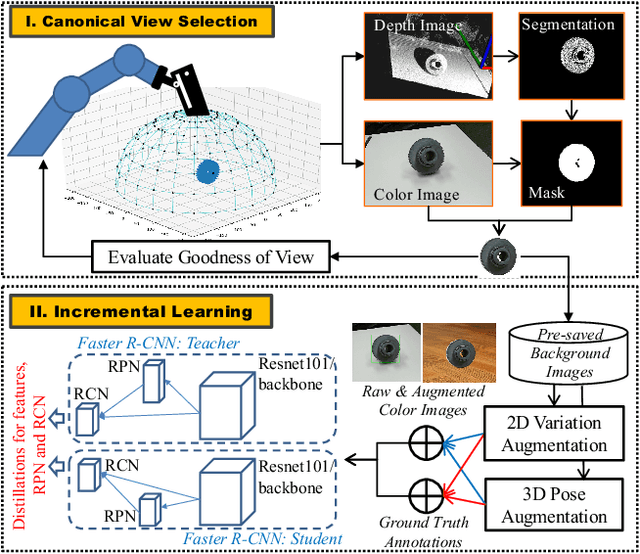
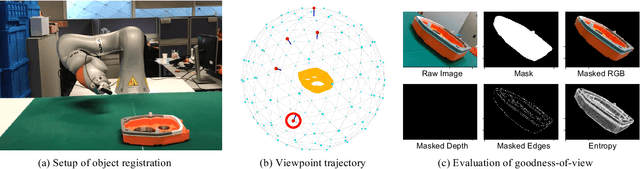

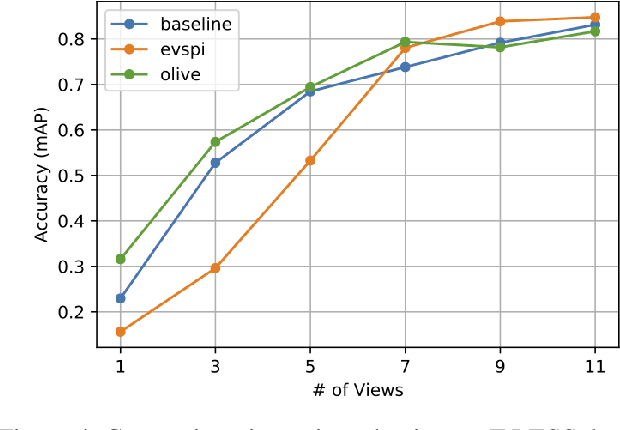
When deploying a robot to a new task, one often has to train it to detect novel objects, which is time-consuming and labor-intensive. We present TAILOR -- a method and system for object registration with active and incremental learning. When instructed by a human teacher to register an object, TAILOR is able to automatically select viewpoints to capture informative images by actively exploring viewpoints, and employs a fast incremental learning algorithm to learn new objects without potential forgetting of previously learned objects. We demonstrate the effectiveness of our method with a KUKA robot to learn novel objects used in a real-world gearbox assembly task through natural interactions.