 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour AI-Generated Image Detector Can Secretly Achieve SOTA Accuracy, If Calibrated
Feb 02, 2026Despite being trained on balanced datasets, existing AI-generated image detectors often exhibit systematic bias at test time, frequently misclassifying fake images as real. We hypothesize that this behavior stems from distributional shift in fake samples and implicit priors learned during training. Specifically, models tend to overfit to superficial artifacts that do not generalize well across different generation methods, leading to a misaligned decision threshold when faced with test-time distribution shift. To address this, we propose a theoretically grounded post-hoc calibration framework based on Bayesian decision theory. In particular, we introduce a learnable scalar correction to the model's logits, optimized on a small validation set from the target distribution while keeping the backbone frozen. This parametric adjustment compensates for distributional shift in model output, realigning the decision boundary even without requiring ground-truth labels. Experiments on challenging benchmarks show that our approach significantly improves robustness without retraining, offering a lightweight and principled solution for reliable and adaptive AI-generated image detection in the open world. Code is available at https://github.com/muliyangm/AIGI-Det-Calib.
Towards Interpretable Hallucination Analysis and Mitigation in LVLMs via Contrastive Neuron Steering
Jan 31, 2026LVLMs achieve remarkable multimodal understanding and generation but remain susceptible to hallucinations. Existing mitigation methods predominantly focus on output-level adjustments, leaving the internal mechanisms that give rise to these hallucinations largely unexplored. To gain a deeper understanding, we adopt a representation-level perspective by introducing sparse autoencoders (SAEs) to decompose dense visual embeddings into sparse, interpretable neurons. Through neuron-level analysis, we identify distinct neuron types, including always-on neurons and image-specific neurons. Our findings reveal that hallucinations often result from disruptions or spurious activations of image-specific neurons, while always-on neurons remain largely stable. Moreover, selectively enhancing or suppressing image-specific neurons enables controllable intervention in LVLM outputs, improving visual grounding and reducing hallucinations. Building on these insights, we propose Contrastive Neuron Steering (CNS), which identifies image-specific neurons via contrastive analysis between clean and noisy inputs. CNS selectively amplifies informative neurons while suppressing perturbation-induced activations, producing more robust and semantically grounded visual representations. This not only enhances visual understanding but also effectively mitigates hallucinations. By operating at the prefilling stage, CNS is fully compatible with existing decoding-stage methods. Extensive experiments on both hallucination-focused and general multimodal benchmarks demonstrate that CNS consistently reduces hallucinations while preserving overall multimodal understanding.
Tempo as the Stable Cue: Hierarchical Mixture of Tempo and Beat Experts for Music to 3D Dance Generation
Dec 21, 2025Music to 3D dance generation aims to synthesize realistic and rhythmically synchronized human dance from music. While existing methods often rely on additional genre labels to further improve dance generation, such labels are typically noisy, coarse, unavailable, or insufficient to capture the diversity of real-world music, which can result in rhythm misalignment or stylistic drift. In contrast, we observe that tempo, a core property reflecting musical rhythm and pace, remains relatively consistent across datasets and genres, typically ranging from 60 to 200 BPM. Based on this finding, we propose TempoMoE, a hierarchical tempo-aware Mixture-of-Experts module that enhances the diffusion model and its rhythm perception. TempoMoE organizes motion experts into tempo-structured groups for different tempo ranges, with multi-scale beat experts capturing fine- and long-range rhythmic dynamics. A Hierarchical Rhythm-Adaptive Routing dynamically selects and fuses experts from music features, enabling flexible, rhythm-aligned generation without manual genre labels. Extensive experiments demonstrate that TempoMoE achieves state-of-the-art results in dance quality and rhythm alignment.
Revealing Perception and Generation Dynamics in LVLMs: Mitigating Hallucinations via Validated Dominance Correction
Dec 21, 2025Large Vision-Language Models (LVLMs) have shown remarkable capabilities, yet hallucinations remain a persistent challenge. This work presents a systematic analysis of the internal evolution of visual perception and token generation in LVLMs, revealing two key patterns. First, perception follows a three-stage GATE process: early layers perform a Global scan, intermediate layers Approach and Tighten on core content, and later layers Explore supplementary regions. Second, generation exhibits an SAD (Subdominant Accumulation to Dominant) pattern, where hallucinated tokens arise from the repeated accumulation of subdominant tokens lacking support from attention (visual perception) or feed-forward network (internal knowledge). Guided by these findings, we devise the VDC (Validated Dominance Correction) strategy, which detects unsupported tokens and replaces them with validated dominant ones to improve output reliability. Extensive experiments across multiple models and benchmarks confirm that VDC substantially mitigates hallucinations.
Team I2R-VI-FF Technical Report on EPIC-KITCHENS VISOR Hand Object Segmentation Challenge 2023
Oct 31, 2023In this report, we present our approach to the EPIC-KITCHENS VISOR Hand Object Segmentation Challenge, which focuses on the estimation of the relation between the hands and the objects given a single frame as input. The EPIC-KITCHENS VISOR dataset provides pixel-wise annotations and serves as a benchmark for hand and active object segmentation in egocentric video. Our approach combines the baseline method, i.e., Point-based Rendering (PointRend) and the Segment Anything Model (SAM), aiming to enhance the accuracy of hand and object segmentation outcomes, while also minimizing instances of missed detection. We leverage accurate hand segmentation maps obtained from the baseline method to extract more precise hand and in-contact object segments. We utilize the class-agnostic segmentation provided by SAM and apply specific hand-crafted constraints to enhance the results. In cases where the baseline model misses the detection of hands or objects, we re-train an object detector on the training set to enhance the detection accuracy. The detected hand and in-contact object bounding boxes are then used as prompts to extract their respective segments from the output of SAM. By effectively combining the strengths of existing methods and applying our refinements, our submission achieved the 1st place in terms of evaluation criteria in the VISOR HOS Challenge.
Masked Diffusion with Task-awareness for Procedure Planning in Instructional Videos
Sep 14, 2023



A key challenge with procedure planning in instructional videos lies in how to handle a large decision space consisting of a multitude of action types that belong to various tasks. To understand real-world video content, an AI agent must proficiently discern these action types (e.g., pour milk, pour water, open lid, close lid, etc.) based on brief visual observation. Moreover, it must adeptly capture the intricate semantic relation of the action types and task goals, along with the variable action sequences. Recently, notable progress has been made via the integration of diffusion models and visual representation learning to address the challenge. However, existing models employ rudimentary mechanisms to utilize task information to manage the decision space. To overcome this limitation, we introduce a simple yet effective enhancement - a masked diffusion model. The introduced mask acts akin to a task-oriented attention filter, enabling the diffusion/denoising process to concentrate on a subset of action types. Furthermore, to bolster the accuracy of task classification, we harness more potent visual representation learning techniques. In particular, we learn a joint visual-text embedding, where a text embedding is generated by prompting a pre-trained vision-language model to focus on human actions. We evaluate the method on three public datasets and achieve state-of-the-art performance on multiple metrics. Code is available at https://github.com/ffzzy840304/Masked-PDPP.
A Study on Differentiable Logic and LLMs for EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2023
Jul 13, 2023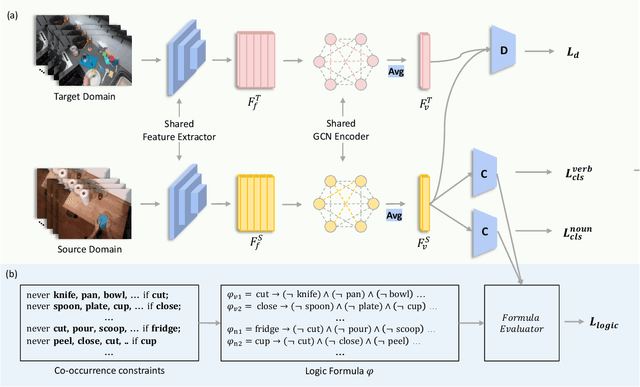
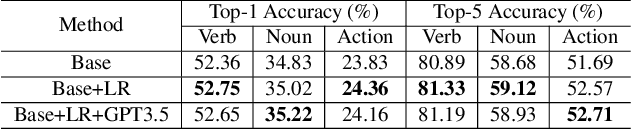
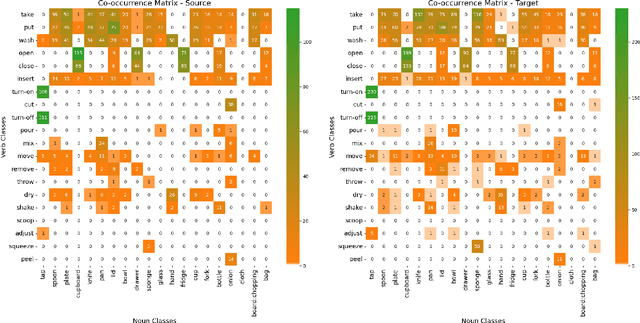

In this technical report, we present our findings from a study conducted on the EPIC-KITCHENS-100 Unsupervised Domain Adaptation task for Action Recognition. Our research focuses on the innovative application of a differentiable logic loss in the training to leverage the co-occurrence relations between verb and noun, as well as the pre-trained Large Language Models (LLMs) to generate the logic rules for the adaptation to unseen action labels. Specifically, the model's predictions are treated as the truth assignment of a co-occurrence logic formula to compute the logic loss, which measures the consistency between the predictions and the logic constraints. By using the verb-noun co-occurrence matrix generated from the dataset, we observe a moderate improvement in model performance compared to our baseline framework. To further enhance the model's adaptability to novel action labels, we experiment with rules generated using GPT-3.5, which leads to a slight decrease in performance. These findings shed light on the potential and challenges of incorporating differentiable logic and LLMs for knowledge extraction in unsupervised domain adaptation for action recognition. Our final submission (entitled `NS-LLM') achieved the first place in terms of top-1 action recognition accuracy.
Team VI-I2R Technical Report on EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2022
Jan 29, 2023



In this report, we present the technical details of our submission to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation (UDA) Challenge for Action Recognition 2022. This task aims to adapt an action recognition model trained on a labeled source domain to an unlabeled target domain. To achieve this goal, we propose an action-aware domain adaptation framework that leverages the prior knowledge induced from the action recognition task during the adaptation. Specifically, we disentangle the source features into action-relevant features and action-irrelevant features using the learned action classifier and then align the target features with the action-relevant features. To further improve the action prediction performance, we exploit the verb-noun co-occurrence matrix to constrain and refine the action predictions. Our final submission achieved the first place in terms of top-1 action recognition accuracy.
Visuo-Tactile Manipulation Planning Using Reinforcement Learning with Affordance Representation
Jul 14, 2022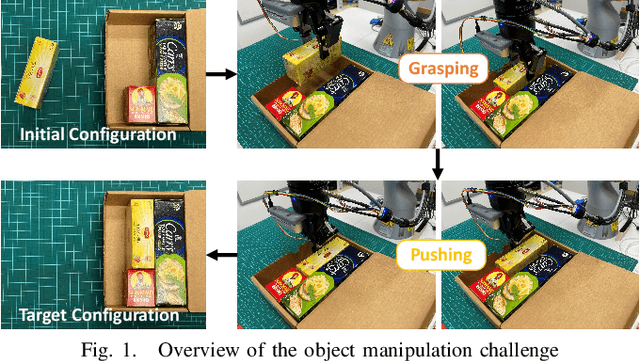
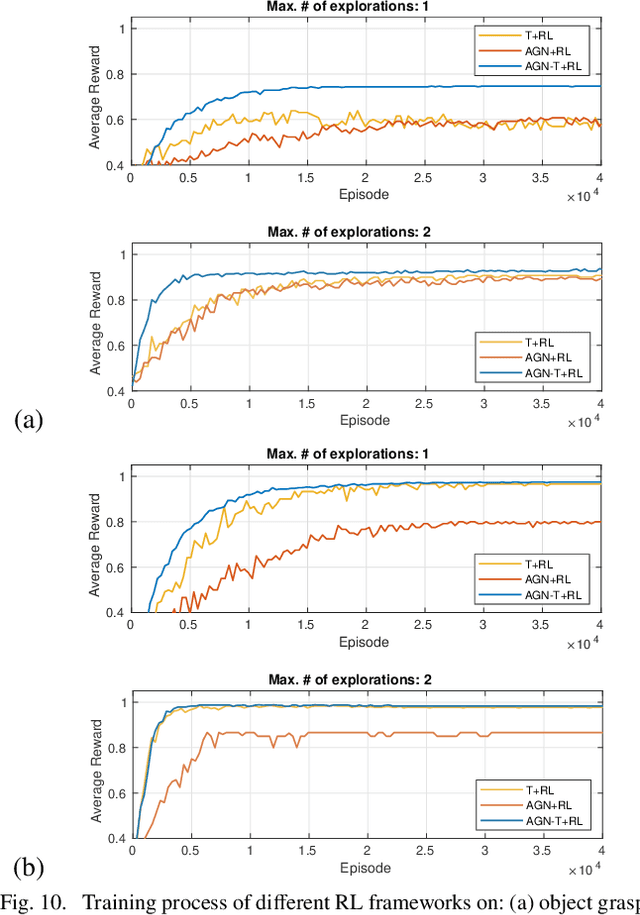
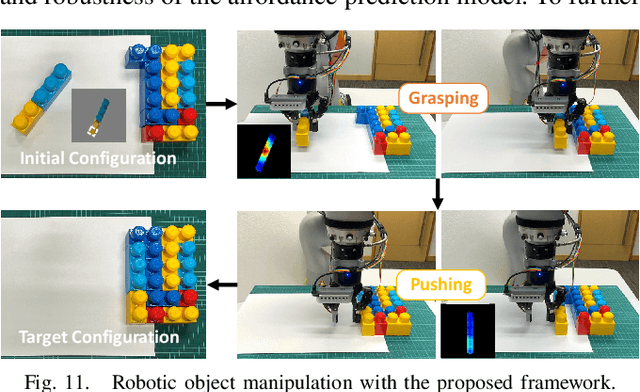
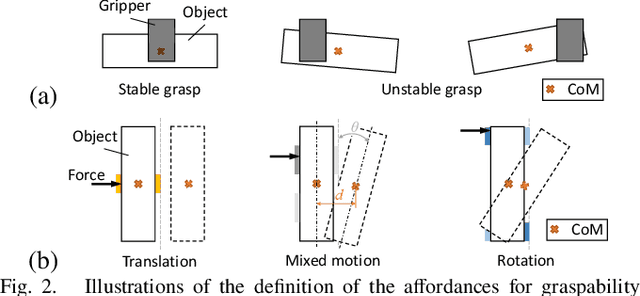
Robots are increasingly expected to manipulate objects in ever more unstructured environments where the object properties have high perceptual uncertainty from any single sensory modality. This directly impacts successful object manipulation. In this work, we propose a reinforcement learning-based motion planning framework for object manipulation which makes use of both on-the-fly multisensory feedback and a learned attention-guided deep affordance model as perceptual states. The affordance model is learned from multiple sensory modalities, including vision and touch (tactile and force/torque), which is designed to predict and indicate the manipulable regions of multiple affordances (i.e., graspability and pushability) for objects with similar appearances but different intrinsic properties (e.g., mass distribution). A DQN-based deep reinforcement learning algorithm is then trained to select the optimal action for successful object manipulation. To validate the performance of the proposed framework, our method is evaluated and benchmarked using both an open dataset and our collected dataset. The results show that the proposed method and overall framework outperform existing methods and achieve better accuracy and higher efficiency.
Team VI-I2R Technical Report on EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2021
Jun 03, 2022

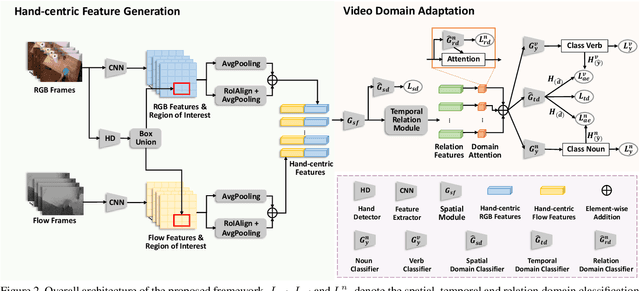

In this report, we present the technical details of our approach to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation (UDA) Challenge for Action Recognition. The EPIC-KITCHENS-100 dataset consists of daily kitchen activities focusing on the interaction between human hands and their surrounding objects. It is very challenging to accurately recognize these fine-grained activities, due to the presence of distracting objects and visually similar action classes, especially in the unlabelled target domain. Based on an existing method for video domain adaptation, i.e., TA3N, we propose to learn hand-centric features by leveraging the hand bounding box information for UDA on fine-grained action recognition. This helps reduce the distraction from background as well as facilitate the learning of domain-invariant features. To achieve high quality hand localization, we adopt an uncertainty-aware domain adaptation network, i.e., MEAA, to train a domain-adaptive hand detector, which only uses very limited hand bounding box annotations in the source domain but can generalize well to the unlabelled target domain. Our submission achieved the 1st place in terms of top-1 action recognition accuracy, using only RGB and optical flow modalities as input.