 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondensed Sample-Guided Model Inversion for Knowledge Distillation
Aug 25, 2024



Knowledge distillation (KD) is a key element in neural network compression that allows knowledge transfer from a pre-trained teacher model to a more compact student model. KD relies on access to the training dataset, which may not always be fully available due to privacy concerns or logistical issues related to the size of the data. To address this, "data-free" KD methods use synthetic data, generated through model inversion, to mimic the target data distribution. However, conventional model inversion methods are not designed to utilize supplementary information from the target dataset, and thus, cannot leverage it to improve performance, even when it is available. In this paper, we consider condensed samples, as a form of supplementary information, and introduce a method for using them to better approximate the target data distribution, thereby enhancing the KD performance. Our approach is versatile, evidenced by improvements of up to 11.4% in KD accuracy across various datasets and model inversion-based methods. Importantly, it remains effective even when using as few as one condensed sample per class, and can also enhance performance in few-shot scenarios where only limited real data samples are available.
Visual-Policy Learning through Multi-Camera View to Single-Camera View Knowledge Distillation for Robot Manipulation Tasks
Mar 13, 2023The use of multi-camera views simultaneously has been shown to improve the generalization capabilities and performance of visual policies. However, the hardware cost and design constraints in real-world scenarios can potentially make it challenging to use multiple cameras. In this study, we present a novel approach to enhance the generalization performance of vision-based Reinforcement Learning (RL) algorithms for robotic manipulation tasks. Our proposed method involves utilizing a technique known as knowledge distillation, in which a pre-trained ``teacher'' policy trained with multiple camera viewpoints guides a ``student'' policy in learning from a single camera viewpoint. To enhance the student policy's robustness against camera location perturbations, it is trained using data augmentation and extreme viewpoint changes. As a result, the student policy learns robust visual features that allow it to locate the object of interest accurately and consistently, regardless of the camera viewpoint. The efficacy and efficiency of the proposed method were evaluated both in simulation and real-world environments. The results demonstrate that the single-view visual student policy can successfully learn to grasp and lift a challenging object, which was not possible with a single-view policy alone. Furthermore, the student policy demonstrates zero-shot transfer capability, where it can successfully grasp and lift objects in real-world scenarios for unseen visual configurations.
Visuo-Tactile Manipulation Planning Using Reinforcement Learning with Affordance Representation
Jul 14, 2022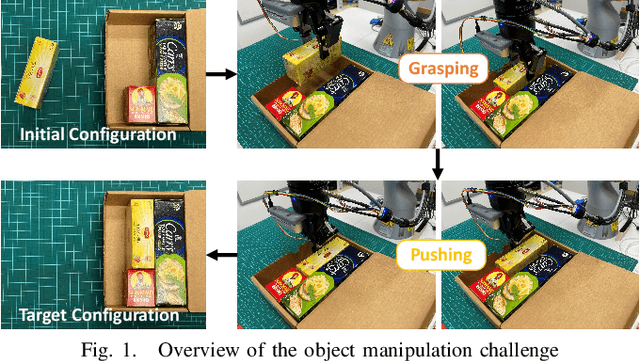
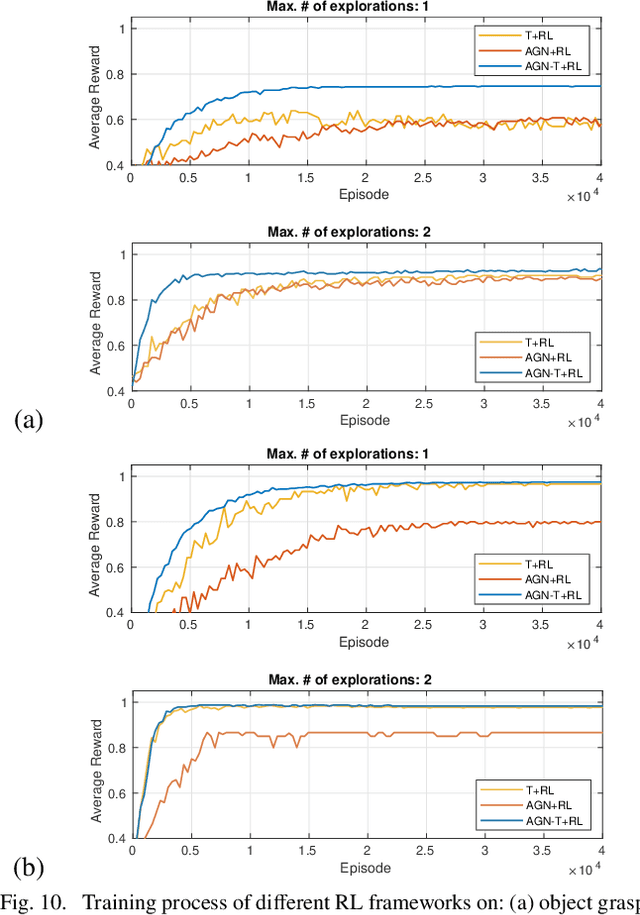
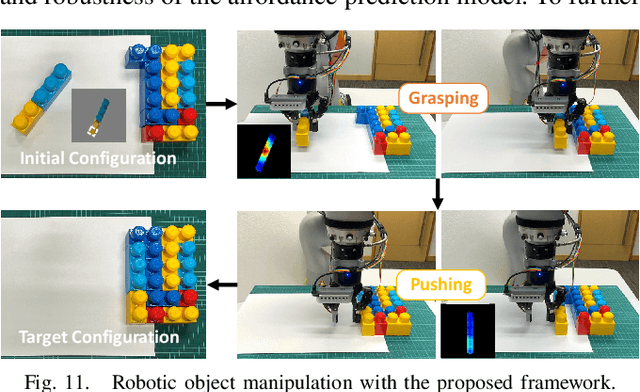
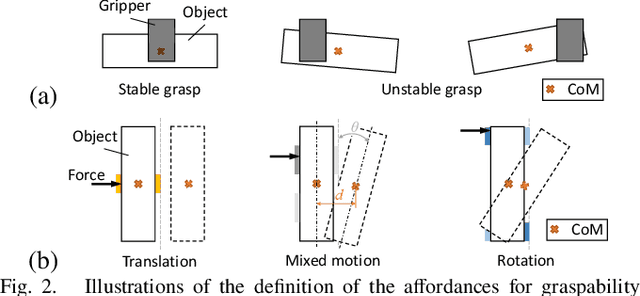
Robots are increasingly expected to manipulate objects in ever more unstructured environments where the object properties have high perceptual uncertainty from any single sensory modality. This directly impacts successful object manipulation. In this work, we propose a reinforcement learning-based motion planning framework for object manipulation which makes use of both on-the-fly multisensory feedback and a learned attention-guided deep affordance model as perceptual states. The affordance model is learned from multiple sensory modalities, including vision and touch (tactile and force/torque), which is designed to predict and indicate the manipulable regions of multiple affordances (i.e., graspability and pushability) for objects with similar appearances but different intrinsic properties (e.g., mass distribution). A DQN-based deep reinforcement learning algorithm is then trained to select the optimal action for successful object manipulation. To validate the performance of the proposed framework, our method is evaluated and benchmarked using both an open dataset and our collected dataset. The results show that the proposed method and overall framework outperform existing methods and achieve better accuracy and higher efficiency.
GloCAL: Glocalized Curriculum-Aided Learning of Multiple Tasks with Application to Robotic Grasping
Apr 14, 2022
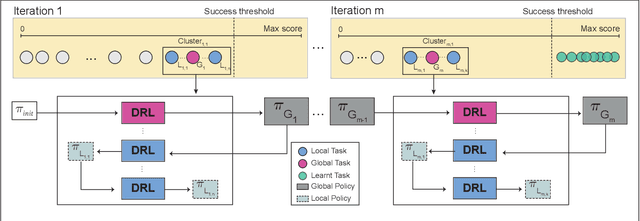
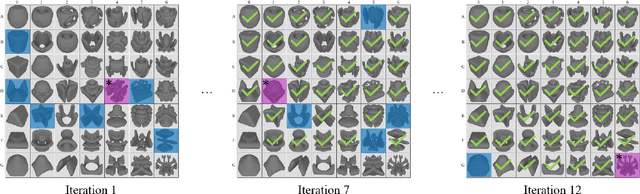
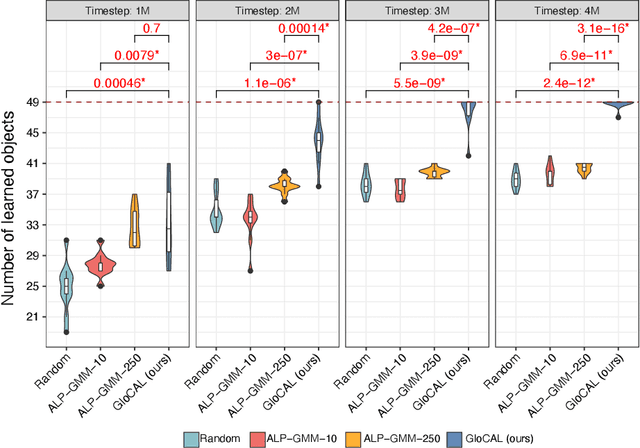
The domain of robotics is challenging to apply deep reinforcement learning due to the need for large amounts of data and for ensuring safety during learning. Curriculum learning has shown good performance in terms of sample- efficient deep learning. In this paper, we propose an algorithm (named GloCAL) that creates a curriculum for an agent to learn multiple discrete tasks, based on clustering tasks according to their evaluation scores. From the highest-performing cluster, a global task representative of the cluster is identified for learning a global policy that transfers to subsequently formed new clusters, while the remaining tasks in the cluster are learned as local policies. The efficacy and efficiency of our GloCAL algorithm are compared with other approaches in the domain of grasp learning for 49 objects with varied object complexity and grasp difficulty from the EGAD! dataset. The results show that GloCAL is able to learn to grasp 100% of the objects, whereas other approaches achieve at most 86% despite being given 1.5 times longer training time.
Approximating Constraint Manifolds Using Generative Models for Sampling-Based Constrained Motion Planning
Apr 14, 2022

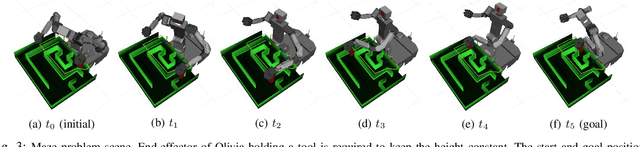

Sampling-based motion planning under task constraints is challenging because the null-measure constraint manifold in the configuration space makes rejection sampling extremely inefficient, if not impossible. This paper presents a learning-based sampling strategy for constrained motion planning problems. We investigate the use of two well-known deep generative models, the Conditional Variational Autoencoder (CVAE) and the Conditional Generative Adversarial Net (CGAN), to generate constraint-satisfying sample configurations. Instead of precomputed graphs, we use generative models conditioned on constraint parameters for approximating the constraint manifold. This approach allows for the efficient drawing of constraint-satisfying samples online without any need for modification of available sampling-based motion planning algorithms. We evaluate the efficiency of these two generative models in terms of their sampling accuracy and coverage of sampling distribution. Simulations and experiments are also conducted for different constraint tasks on two robotic platforms.
6D Pose Estimation with Correlation Fusion
Sep 24, 2019
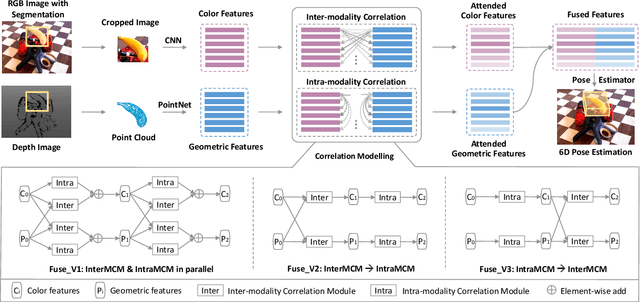
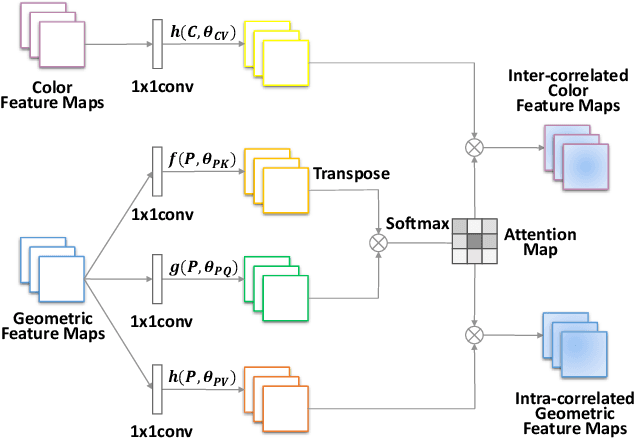

6D object pose estimation is widely applied in robotic tasks such as grasping and manipulation. Prior methods using RGB-only images are vulnerable to heavy occlusion and poor illumination, so it is important to complement them with depth information. However, existing methods using RGB-D data don't adequately exploit consistent and complementary information between two modalities. In this paper, we present a novel method to effectively consider the correlation within and across RGB and depth modalities with attention mechanism to learn discriminative multi-modal features. Then, effective fusion strategies for intra- and inter-correlation modules are explored to ensure efficient information flow between RGB and depth. To the best of our knowledge, this is the first work to explore effective intra- and inter-modality fusion in 6D pose estimation and experimental results show that our method can help achieve the state-of-the-art performance on LineMOD and YCB-Video datasets as well as benefit robot grasping task.