 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6D Pose Estimation with Correlation Fusion
Paper and Code
Sep 24, 2019
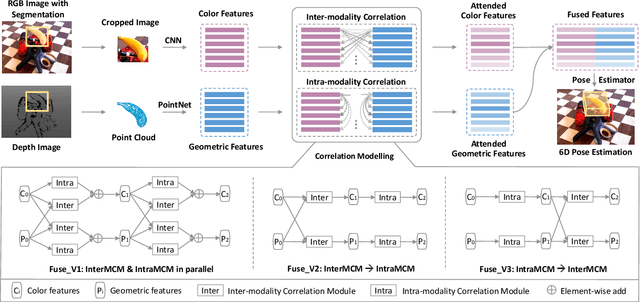
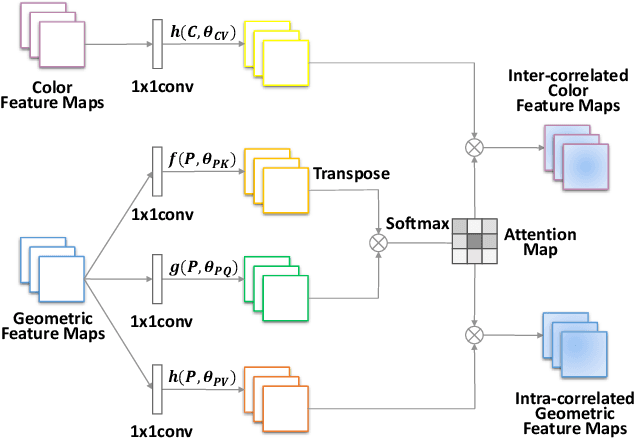

6D object pose estimation is widely applied in robotic tasks such as grasping and manipulation. Prior methods using RGB-only images are vulnerable to heavy occlusion and poor illumination, so it is important to complement them with depth information. However, existing methods using RGB-D data don't adequately exploit consistent and complementary information between two modalities. In this paper, we present a novel method to effectively consider the correlation within and across RGB and depth modalities with attention mechanism to learn discriminative multi-modal features. Then, effective fusion strategies for intra- and inter-correlation modules are explored to ensure efficient information flow between RGB and depth. To the best of our knowledge, this is the first work to explore effective intra- and inter-modality fusion in 6D pose estimation and experimental results show that our method can help achieve the state-of-the-art performance on LineMOD and YCB-Video datasets as well as benefit robot grasping task.