 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025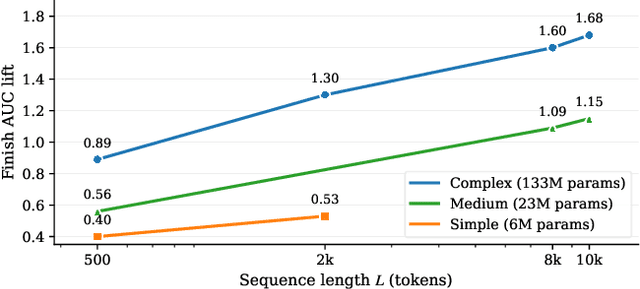
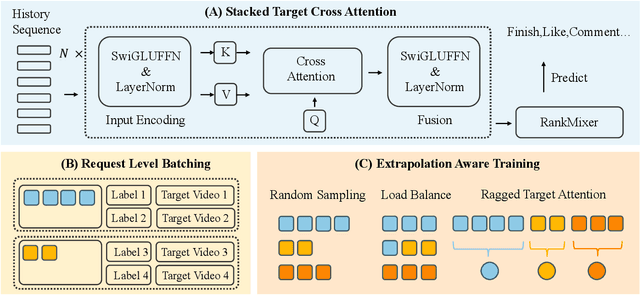

Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
SSPO: Self-traced Step-wise Preference Optimization for Process Supervision and Reasoning Compression
Aug 18, 2025Test-time scaling has proven effective in further enhancing the performance of pretrained Large Language Models (LLMs). However, mainstream post-training methods (i.e., reinforcement learning (RL) with chain-of-thought (CoT) reasoning) often incur substantial computational overhead due to auxiliary models and overthinking. In this paper, we empirically reveal that the incorrect answers partially stem from verbose reasoning processes lacking correct self-fix, where errors accumulate across multiple reasoning steps. To this end, we propose Self-traced Step-wise Preference Optimization (SSPO), a pluggable RL process supervision framework that enables fine-grained optimization of each reasoning step. Specifically, SSPO requires neither auxiliary models nor stepwise manual annotations. Instead, it leverages step-wise preference signals generated by the model itself to guide the optimization process for reasoning compression. Experiments demonstrate that the generated reasoning sequences from SSPO are both accurate and succinct, effectively mitigating overthinking behaviors without compromising model performance across diverse domains and languages.
Towards Dynamic Theory of Mind: Evaluating LLM Adaptation to Temporal Evolution of Human States
May 23, 2025As Large Language Models (LLMs) increasingly participate in human-AI interactions, evaluating their Theory of Mind (ToM) capabilities - particularly their ability to track dynamic mental states - becomes crucial. While existing benchmarks assess basic ToM abilities, they predominantly focus on static snapshots of mental states, overlooking the temporal evolution that characterizes real-world social interactions. We present \textsc{DynToM}, a novel benchmark specifically designed to evaluate LLMs' ability to understand and track the temporal progression of mental states across interconnected scenarios. Through a systematic four-step framework, we generate 1,100 social contexts encompassing 5,500 scenarios and 78,100 questions, each validated for realism and quality. Our comprehensive evaluation of ten state-of-the-art LLMs reveals that their average performance underperforms humans by 44.7\%, with performance degrading significantly when tracking and reasoning about the shift of mental states. This performance gap highlights fundamental limitations in current LLMs' ability to model the dynamic nature of human mental states.
RADAR: Enhancing Radiology Report Generation with Supplementary Knowledge Injection
May 20, 2025Large language models (LLMs) have demonstrated remarkable capabilities in various domains, including radiology report generation. Previous approaches have attempted to utilize multimodal LLMs for this task, enhancing their performance through the integration of domain-specific knowledge retrieval. However, these approaches often overlook the knowledge already embedded within the LLMs, leading to redundant information integration and inefficient utilization of learned representations. To address this limitation, we propose RADAR, a framework for enhancing radiology report generation with supplementary knowledge injection. RADAR improves report generation by systematically leveraging both the internal knowledge of an LLM and externally retrieved information. Specifically, it first extracts the model's acquired knowledge that aligns with expert image-based classification outputs. It then retrieves relevant supplementary knowledge to further enrich this information. Finally, by aggregating both sources, RADAR generates more accurate and informative radiology reports. Extensive experiments on MIMIC-CXR, CheXpert-Plus, and IU X-ray demonstrate that our model outperforms state-of-the-art LLMs in both language quality and clinical accuracy
Learning to Align Multi-Faceted Evaluation: A Unified and Robust Framework
Feb 26, 2025Large Language Models (LLMs) are being used more and more extensively for automated evaluation in various scenarios. Previous studies have attempted to fine-tune open-source LLMs to replicate the evaluation explanations and judgments of powerful proprietary models, such as GPT-4. However, these methods are largely limited to text-based analyses under predefined general criteria, resulting in reduced adaptability for unseen instructions and demonstrating instability in evaluating adherence to quantitative and structural constraints. To address these limitations, we propose a novel evaluation framework, ARJudge, that adaptively formulates evaluation criteria and synthesizes both text-based and code-driven analyses to evaluate LLM responses. ARJudge consists of two components: a fine-tuned Analyzer that generates multi-faceted evaluation analyses and a tuning-free Refiner that combines and refines all analyses to make the final judgment. We construct a Composite Analysis Corpus that integrates tasks for evaluation criteria generation alongside text-based and code-driven analysis generation to train the Analyzer. Our results demonstrate that ARJudge outperforms existing fine-tuned evaluators in effectiveness and robustness. Furthermore, it demonstrates the importance of multi-faceted evaluation and code-driven analyses in enhancing evaluation capabilities.
Training an LLM-as-a-Judge Model: Pipeline, Insights, and Practical Lessons
Feb 05, 2025The rapid advancement of large language models (LLMs) has opened new possibilities for their adoption as evaluative judges. This paper introduces Themis, a fine-tuned LLM judge that delivers sophisticated context-aware evaluations. We provide a comprehensive overview of the development pipeline for Themis, highlighting its scenario-dependent evaluation prompts and two novel methods for controlled instruction generation. These designs enable Themis to effectively distill evaluative skills from teacher models, while retaining flexibility for continuous development. We introduce two human-labeled benchmarks for meta-evaluation, demonstrating that Themis can achieve high alignment with human preferences in an economical manner. Additionally, we explore insights into the LLM-as-a-judge paradigm, revealing nuances in performance and the varied effects of reference answers. Notably, we observe that pure knowledge distillation from strong LLMs, though common, does not guarantee performance improvement through scaling. We propose a mitigation strategy based on instruction-following difficulty. Furthermore, we provide practical guidelines covering data balancing, prompt customization, multi-objective training, and metric aggregation. We aim for our method and findings, along with the fine-tuning data, benchmarks, and model checkpoints, to support future research and development in this area.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Memory-Augmented Multimodal LLMs for Surgical VQA via Self-Contained Inquiry
Nov 17, 2024



Comprehensively understanding surgical scenes in Surgical Visual Question Answering (Surgical VQA) requires reasoning over multiple objects. Previous approaches address this task using cross-modal fusion strategies to enhance reasoning ability. However, these methods often struggle with limited scene understanding and question comprehension, and some rely on external resources (e.g., pre-extracted object features), which can introduce errors and generalize poorly across diverse surgical environments. To address these challenges, we propose SCAN, a simple yet effective memory-augmented framework that leverages Multimodal LLMs to improve surgical context comprehension via Self-Contained Inquiry. SCAN operates autonomously, generating two types of memory for context augmentation: Direct Memory (DM), which provides multiple candidates (or hints) to the final answer, and Indirect Memory (IM), which consists of self-contained question-hint pairs to capture broader scene context. DM directly assists in answering the question, while IM enhances understanding of the surgical scene beyond the immediate query. Reasoning over these object-aware memories enables the model to accurately interpret images and respond to questions. Extensive experiments on three publicly available Surgical VQA datasets demonstrate that SCAN achieves state-of-the-art performance, offering improved accuracy and robustness across various surgical scenarios.
Subtle Errors Matter: Preference Learning via Error-injected Self-editing
Oct 09, 2024


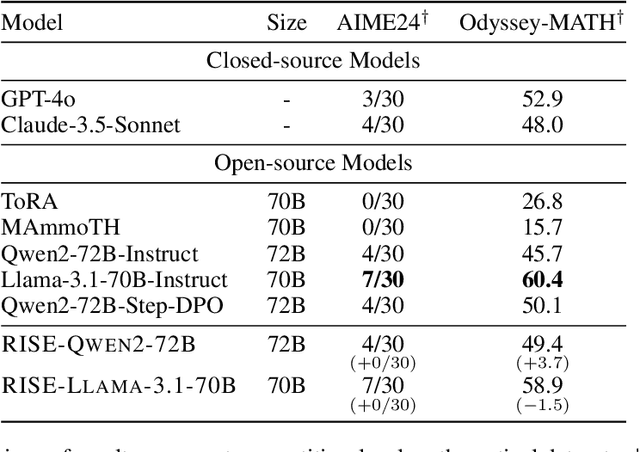
Large Language Models (LLMs) have exhibited strong mathematical reasoning and computational prowess, tackling tasks ranging from basic arithmetic to advanced competition-level problems. However, frequently occurring subtle errors, such as miscalculations or incorrect substitutions, limit the models' full mathematical potential. Existing studies to improve mathematical ability typically involve distilling reasoning skills from stronger LLMs or applying preference learning to step-wise response pairs. Although these methods leverage samples of varying granularity to mitigate reasoning errors, they overlook the frequently occurring subtle errors. A major reason is that sampled preference pairs involve differences unrelated to the errors, which may distract the model from focusing on subtle errors. In this work, we propose a novel preference learning framework called eRror-Injected Self-Editing (RISE), which injects predefined subtle errors into partial tokens of correct solutions to construct hard pairs for error mitigation. In detail, RISE uses the model itself to edit a small number of tokens in the solution, injecting designed subtle errors. Then, pairs composed of self-edited solutions and their corresponding correct ones, along with pairs of correct and incorrect solutions obtained through sampling, are used together for subtle error-aware DPO training. Compared with other preference learning methods, RISE further refines the training objective to focus on predefined errors and their tokens, without requiring fine-grained sampling or preference annotation. Extensive experiments validate the effectiveness of RISE, with preference learning on Qwen2-7B-Instruct yielding notable improvements of 3.0% on GSM8K and 7.9% on MATH.
Integrative Decoding: Improve Factuality via Implicit Self-consistency
Oct 02, 2024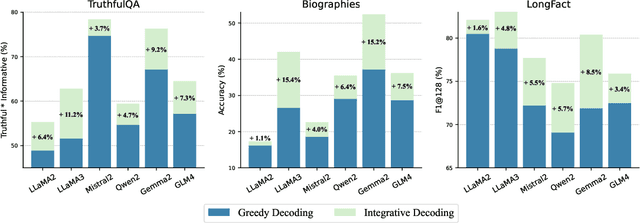
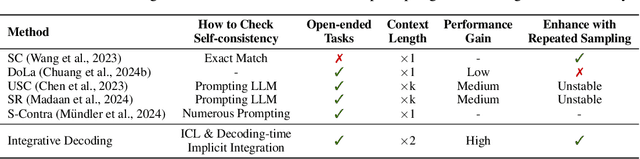
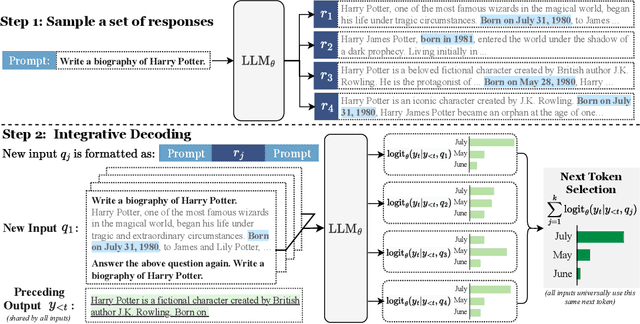
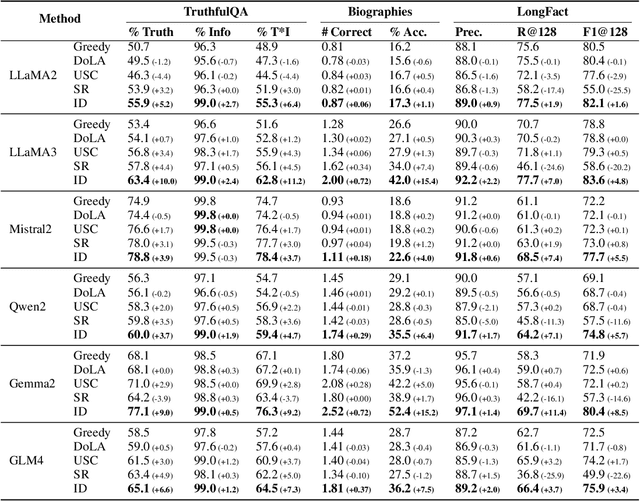
Self-consistency-based approaches, which involve repeatedly sampling multiple outputs and selecting the most consistent one as the final response, prove to be remarkably effective in improving the factual accuracy of large language models. Nonetheless, existing methods usually have strict constraints on the task format, largely limiting their applicability. In this paper, we present Integrative Decoding (ID), to unlock the potential of self-consistency in open-ended generation tasks. ID operates by constructing a set of inputs, each prepended with a previously sampled response, and then processes them concurrently, with the next token being selected by aggregating of all their corresponding predictions at each decoding step. In essence, this simple approach implicitly incorporates self-consistency in the decoding objective. Extensive evaluation shows that ID consistently enhances factuality over a wide range of language models, with substantial improvements on the TruthfulQA (+11.2%), Biographies (+15.4%) and LongFact (+8.5%) benchmarks. The performance gains amplify progressively as the number of sampled responses increases, indicating the potential of ID to scale up with repeated sampling.