 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMICON-Bench: Benchmarking and Enhancing Multi-Image Context Image Generation in Unified Multimodal Models
Feb 23, 2026Recent advancements in Unified Multimodal Models (UMMs) have enabled remarkable image understanding and generation capabilities. However, while models like Gemini-2.5-Flash-Image show emerging abilities to reason over multiple related images, existing benchmarks rarely address the challenges of multi-image context generation, focusing mainly on text-to-image or single-image editing tasks. In this work, we introduce \textbf{MICON-Bench}, a comprehensive benchmark covering six tasks that evaluate cross-image composition, contextual reasoning, and identity preservation. We further propose an MLLM-driven Evaluation-by-Checkpoint framework for automatic verification of semantic and visual consistency, where multimodal large language model (MLLM) serves as a verifier. Additionally, we present \textbf{Dynamic Attention Rebalancing (DAR)}, a training-free, plug-and-play mechanism that dynamically adjusts attention during inference to enhance coherence and reduce hallucinations. Extensive experiments on various state-of-the-art open-source models demonstrate both the rigor of MICON-Bench in exposing multi-image reasoning challenges and the efficacy of DAR in improving generation quality and cross-image coherence. Github: https://github.com/Angusliuuu/MICON-Bench.
PMG: Parameterized Motion Generator for Human-like Locomotion Control
Feb 13, 2026Recent advances in data-driven reinforcement learning and motion tracking have substantially improved humanoid locomotion, yet critical practical challenges remain. In particular, while low-level motion tracking and trajectory-following controllers are mature, whole-body reference-guided methods are difficult to adapt to higher-level command interfaces and diverse task contexts: they require large, high-quality datasets, are brittle across speed and pose regimes, and are sensitive to robot-specific calibration. To address these limitations, we propose the Parameterized Motion Generator (PMG), a real-time motion generator grounded in an analysis of human motion structure that synthesizes reference trajectories using only a compact set of parameterized motion data together with High-dimensional control commands. Combined with an imitation-learning pipeline and an optimization-based sim-to-real motor parameter identification module, we validate the complete approach on our humanoid prototype ZERITH Z1 and show that, within a single integrated system, PMG produces natural, human-like locomotion, responds precisely to high-dimensional control inputs-including VR-based teleoperation-and enables efficient, verifiable sim-to-real transfer. Together, these results establish a practical, experimentally validated pathway toward natural and deployable humanoid control.
Online identification of nonlinear time-varying systems with uncertain information
Jan 15, 2026Digital twins (DTs), serving as the core enablers for real-time monitoring and predictive maintenance of complex cyber-physical systems, impose critical requirements on their virtual models: high predictive accuracy, strong interpretability, and online adaptive capability. However, existing techniques struggle to meet these demands simultaneously: Bayesian methods excel in uncertainty quantification but lack model interpretability, while interpretable symbolic identification methods (e.g., SINDy) are constrained by their offline, batch-processing nature, which make real-time updates challenging. To bridge this semantic and computational gap, this paper proposes a novel Bayesian Regression-based Symbolic Learning (BRSL) framework. The framework formulates online symbolic discovery as a unified probabilistic state-space model. By incorporating sparse horseshoe priors, model selection is transformed into a Bayesian inference task, enabling simultaneous system identification and uncertainty quantification. Furthermore, we derive an online recursive algorithm with a forgetting factor and establish precise recursive conditions that guarantee the well-posedness of the posterior distribution. These conditions also function as real-time monitors for data utility, enhancing algorithmic robustness. Additionally, a rigorous convergence analysis is provided, demonstrating the convergence of parameter estimates under persistent excitation conditions. Case studies validate the effectiveness of the proposed framework in achieving interpretable, probabilistic prediction and online learning.
CHyLL: Learning Continuous Neural Representations of Hybrid Systems
Dec 10, 2025Learning the flows of hybrid systems that have both continuous and discrete time dynamics is challenging. The existing method learns the dynamics in each discrete mode, which suffers from the combination of mode switching and discontinuities in the flows. In this work, we propose CHyLL (Continuous Hybrid System Learning in Latent Space), which learns a continuous neural representation of a hybrid system without trajectory segmentation, event functions, or mode switching. The key insight of CHyLL is that the reset map glues the state space at the guard surface, reformulating the state space as a piecewise smooth quotient manifold where the flow becomes spatially continuous. Building upon these insights and the embedding theorems grounded in differential topology, CHyLL concurrently learns a singularity-free neural embedding in a higher-dimensional space and the continuous flow in it. We showcase that CHyLL can accurately predict the flow of hybrid systems with superior accuracy and identify the topological invariants of the hybrid systems. Finally, we apply CHyLL to the stochastic optimal control problem.
Imaginative World Modeling with Scene Graphs for Embodied Agent Navigation
Aug 09, 2025Semantic navigation requires an agent to navigate toward a specified target in an unseen environment. Employing an imaginative navigation strategy that predicts future scenes before taking action, can empower the agent to find target faster. Inspired by this idea, we propose SGImagineNav, a novel imaginative navigation framework that leverages symbolic world modeling to proactively build a global environmental representation. SGImagineNav maintains an evolving hierarchical scene graphs and uses large language models to predict and explore unseen parts of the environment. While existing methods solely relying on past observations, this imaginative scene graph provides richer semantic context, enabling the agent to proactively estimate target locations. Building upon this, SGImagineNav adopts an adaptive navigation strategy that exploits semantic shortcuts when promising and explores unknown areas otherwise to gather additional context. This strategy continuously expands the known environment and accumulates valuable semantic contexts, ultimately guiding the agent toward the target. SGImagineNav is evaluated in both real-world scenarios and simulation benchmarks. SGImagineNav consistently outperforms previous methods, improving success rate to 65.4 and 66.8 on HM3D and HSSD, and demonstrating cross-floor and cross-room navigation in real-world environments, underscoring its effectiveness and generalizability.
RollingQ: Reviving the Cooperation Dynamics in Multimodal Transformer
Jun 13, 2025Multimodal learning faces challenges in effectively fusing information from diverse modalities, especially when modality quality varies across samples. Dynamic fusion strategies, such as attention mechanism in Transformers, aim to address such challenge by adaptively emphasizing modalities based on the characteristics of input data. However, through amounts of carefully designed experiments, we surprisingly observed that the dynamic adaptability of widely-used self-attention models diminishes. Model tends to prefer one modality regardless of data characteristics. This bias triggers a self-reinforcing cycle that progressively overemphasizes the favored modality, widening the distribution gap in attention keys across modalities and deactivating attention mechanism's dynamic properties. To revive adaptability, we propose a simple yet effective method Rolling Query (RollingQ), which balances attention allocation by rotating the query to break the self-reinforcing cycle and mitigate the key distribution gap. Extensive experiments on various multimodal scenarios validate the effectiveness of RollingQ and the restoration of cooperation dynamics is pivotal for enhancing the broader capabilities of widely deployed multimodal Transformers. The source code is available at https://github.com/GeWu-Lab/RollingQ_ICML2025.
Analyzing 16,193 LLM Papers for Fun and Profits
Apr 15, 2025Large Language Models (LLMs) are reshaping the landscape of computer science research, driving significant shifts in research priorities across diverse conferences and fields. This study provides a comprehensive analysis of the publication trend of LLM-related papers in 77 top-tier computer science conferences over the past six years (2019-2024). We approach this analysis from four distinct perspectives: (1) We investigate how LLM research is driving topic shifts within major conferences. (2) We adopt a topic modeling approach to identify various areas of LLM-related topic growth and reveal the topics of concern at different conferences. (3) We explore distinct contribution patterns of academic and industrial institutions. (4) We study the influence of national origins on LLM development trajectories. Synthesizing the findings from these diverse analytical angles, we derive ten key insights that illuminate the dynamics and evolution of the LLM research ecosystem.
Region Based SLAM-Aware Exploration: Efficient and Robust Autonomous Mapping Strategy That Can Scale
Apr 14, 2025Autonomous exploration for mapping unknown large scale environments is a fundamental challenge in robotics, with efficiency in time, stability against map corruption and computational resources being crucial. This paper presents a novel approach to indoor exploration that addresses these key issues in existing methods. We introduce a Simultaneous Localization and Mapping (SLAM)-aware region-based exploration strategy that partitions the environment into discrete regions, allowing the robot to incrementally explore and stabilize each region before moving to the next one. This approach significantly reduces redundant exploration and improves overall efficiency. As the device finishes exploring a region and stabilizes it, we also perform SLAM keyframe marginalization, a technique which reduces problem complexity by eliminating variables, while preserving their essential information. To improves robustness and further enhance efficiency, we develop a check- point system that enables the robot to resume exploration from the last stable region in case of failures, eliminating the need for complete re-exploration. Our method, tested in real homes, office and simulations, outperforms state-of-the-art approaches. The improvements demonstrate substantial enhancements in various real world environments, with significant reductions in keyframe usage (85%), submap usage (50% office, 32% home), pose graph optimization time (78-80%), and exploration duration (10-15%). This region-based strategy with keyframe marginalization offers an efficient solution for autonomous robotic mapping.
A Two-Timescale Approach for Wireless Federated Learning with Parameter Freezing and Power Control
Apr 02, 2025



Federated learning (FL) enables distributed devices to train a shared machine learning (ML) model collaboratively while protecting their data privacy. However, the resource-limited mobile devices suffer from intensive computation-and-communication costs of model parameters. In this paper, we observe the phenomenon that the model parameters tend to be stabilized long before convergence during training process. Based on this observation, we propose a two-timescale FL framework by joint optimization of freezing stabilized parameters and controlling transmit power for the unstable parameters to balance the energy consumption and convergence. First, we analyze the impact of model parameter freezing and unreliable transmission on the convergence rate. Next, we formulate a two-timescale optimization problem of parameter freezing percentage and transmit power to minimize the model convergence error subject to the energy budget. To solve this problem, we decompose it into parallel sub-problems and decompose each sub-problem into two different timescales problems using the Lyapunov optimization method. The optimal parameter freezing and power control strategies are derived in an online fashion. Experimental results demonstrate the superiority of the proposed scheme compared with the benchmark schemes.
Deal: Distributed End-to-End GNN Inference for All Nodes
Mar 04, 2025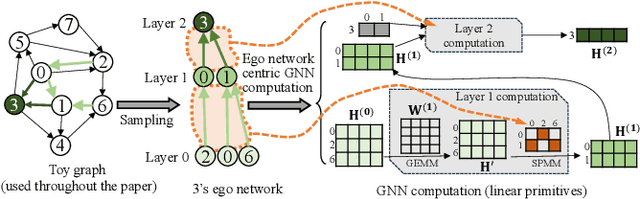

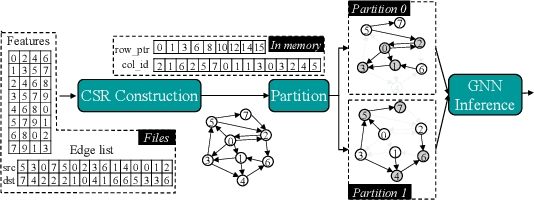
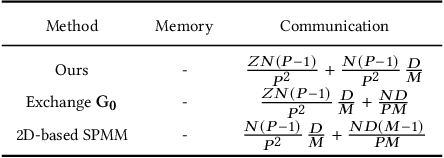
Graph Neural Networks (GNNs) are a new research frontier with various applications and successes. The end-to-end inference for all nodes, is common for GNN embedding models, which are widely adopted in applications like recommendation and advertising. While sharing opportunities arise in GNN tasks (i.e., inference for a few nodes and training), the potential for sharing in full graph end-to-end inference is largely underutilized because traditional efforts fail to fully extract sharing benefits due to overwhelming overheads or excessive memory usage. This paper introduces Deal, a distributed GNN inference system that is dedicated to end-to-end inference for all nodes for graphs with multi-billion edges. First, we unveil and exploit an untapped sharing opportunity during sampling, and maximize the benefits from sharing during subsequent GNN computation. Second, we introduce memory-saving and communication-efficient distributed primitives for lightweight 1-D graph and feature tensor collaborative partitioning-based distributed inference. Third, we introduce partitioned, pipelined communication and fusing feature preparation with the first GNN primitive for end-to-end inference. With Deal, the end-to-end inference time on real-world benchmark datasets is reduced up to 7.70 x and the graph construction time is reduced up to 21.05 x, compared to the state-of-the-art.