 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIBench: Evaluating LMMs on Multimodal Interaction
Mar 13, 2026In different multimodal scenarios, it needs to integrate and utilize information across modalities in a specific way based on the demands of the task. Different integration ways between modalities are referred to as "multimodal interaction". How well a model handles various multimodal interactions largely characterizes its multimodal ability. In this paper, we introduce MIBench, a comprehensive benchmark designed to evaluate the multimodal interaction capabilities of Large Multimodal Models (LMMs), which formulates each instance as a (con_v , con_t, task) triplet with contexts from vision and text, necessitating that LMMs employ correct forms of multimodal interaction to effectively complete the task. MIBench assesses models from three key aspects: the ability to source information from vision-centric or text-centric cues, and the ability to generate new information from their joint synergy. Each interaction capability is evaluated hierarchically across three cognitive levels: Recognition, Understanding, and Reasoning. MIBench comprises over 10,000 vision-text context pairs spanning 32 distinct tasks. Evaluation of state-of-the-art LMMs show that: (1) LMMs' ability on multimodal interaction remains constrained, despite the scaling of model parameters and training data; (2) they are easily distracted by textual modalities when processing vision information; (3) they mostly possess a basic capacity for multimodal synergy; and (4) natively trained multimodal models show noticeable deficits in fundamental interaction ability. We expect that these observations can serve as a reference for developing LMMs with more enhanced multimodal ability in the future.
RollingQ: Reviving the Cooperation Dynamics in Multimodal Transformer
Jun 13, 2025Multimodal learning faces challenges in effectively fusing information from diverse modalities, especially when modality quality varies across samples. Dynamic fusion strategies, such as attention mechanism in Transformers, aim to address such challenge by adaptively emphasizing modalities based on the characteristics of input data. However, through amounts of carefully designed experiments, we surprisingly observed that the dynamic adaptability of widely-used self-attention models diminishes. Model tends to prefer one modality regardless of data characteristics. This bias triggers a self-reinforcing cycle that progressively overemphasizes the favored modality, widening the distribution gap in attention keys across modalities and deactivating attention mechanism's dynamic properties. To revive adaptability, we propose a simple yet effective method Rolling Query (RollingQ), which balances attention allocation by rotating the query to break the self-reinforcing cycle and mitigate the key distribution gap. Extensive experiments on various multimodal scenarios validate the effectiveness of RollingQ and the restoration of cooperation dynamics is pivotal for enhancing the broader capabilities of widely deployed multimodal Transformers. The source code is available at https://github.com/GeWu-Lab/RollingQ_ICML2025.
MokA: Multimodal Low-Rank Adaptation for MLLMs
Jun 05, 2025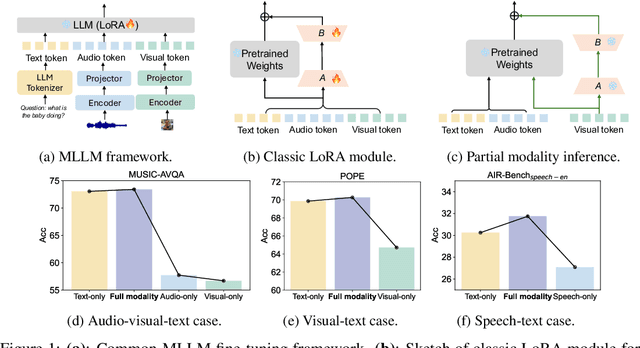
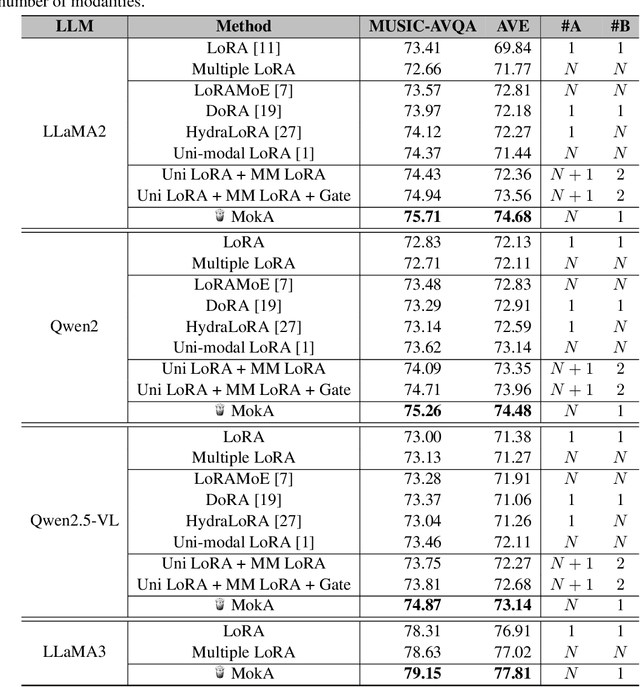
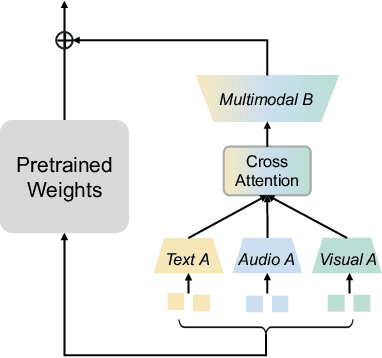
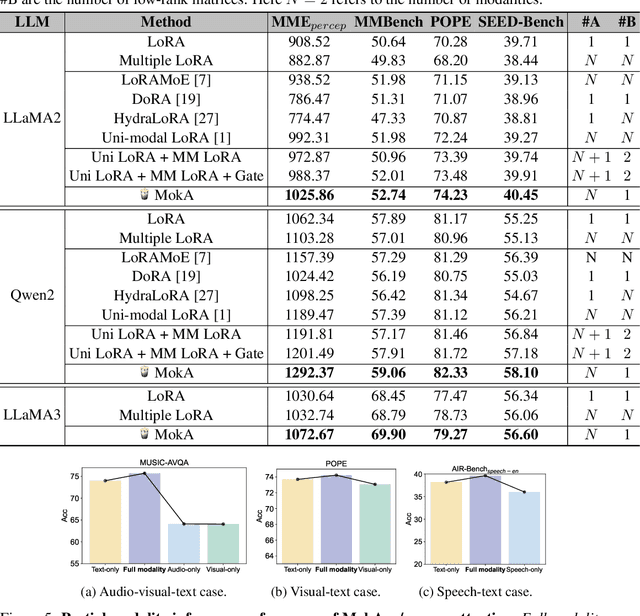
In this paper, we reveal that most current efficient multimodal fine-tuning methods are hindered by a key limitation: they are directly borrowed from LLMs, often neglecting the intrinsic differences of multimodal scenarios and even affecting the full utilization of all modalities. Inspired by our empirical observation, we argue that unimodal adaptation and cross-modal adaptation are two essential parts for the effective fine-tuning of MLLMs. From this perspective, we propose Multimodal low-rank Adaptation (MokA), a multimodal-aware efficient fine-tuning strategy that takes multimodal characteristics into consideration. It compresses unimodal information by modality-specific parameters while explicitly enhancing cross-modal interaction, ensuring both unimodal and cross-modal adaptation. Extensive experiments cover three representative multimodal scenarios (audio-visual-text, visual-text, and speech-text), and multiple LLM backbones (LLaMA2/3, Qwen2, Qwen2.5-VL, etc). Consistent improvements indicate the efficacy and versatility of the proposed method. Ablation studies and efficiency evaluation are also conducted to fully asses our method. Overall, we think MokA provides a more targeted solution for efficient adaptation of MLLMs, paving the way for further exploration. The project page is at https://gewu-lab.github.io/MokA.
Patch Matters: Training-free Fine-grained Image Caption Enhancement via Local Perception
Apr 09, 2025



High-quality image captions play a crucial role in improving the performance of cross-modal applications such as text-to-image generation, text-to-video generation, and text-image retrieval. To generate long-form, high-quality captions, many recent studies have employed multimodal large language models (MLLMs). However, current MLLMs often produce captions that lack fine-grained details or suffer from hallucinations, a challenge that persists in both open-source and closed-source models. Inspired by Feature-Integration theory, which suggests that attention must focus on specific regions to integrate visual information effectively, we propose a \textbf{divide-then-aggregate} strategy. Our method first divides the image into semantic and spatial patches to extract fine-grained details, enhancing the model's local perception of the image. These local details are then hierarchically aggregated to generate a comprehensive global description. To address hallucinations and inconsistencies in the generated captions, we apply a semantic-level filtering process during hierarchical aggregation. This training-free pipeline can be applied to both open-source models (LLaVA-1.5, LLaVA-1.6, Mini-Gemini) and closed-source models (Claude-3.5-Sonnet, GPT-4o, GLM-4V-Plus). Extensive experiments demonstrate that our method generates more detailed, reliable captions, advancing multimodal description generation without requiring model retraining. The source code are available at https://github.com/GeWu-Lab/Patch-Matters
Adaptive Unimodal Regulation for Balanced Multimodal Information Acquisition
Mar 24, 2025Sensory training during the early ages is vital for human development. Inspired by this cognitive phenomenon, we observe that the early training stage is also important for the multimodal learning process, where dataset information is rapidly acquired. We refer to this stage as the prime learning window. However, based on our observation, this prime learning window in multimodal learning is often dominated by information-sufficient modalities, which in turn suppresses the information acquisition of information-insufficient modalities. To address this issue, we propose Information Acquisition Regulation (InfoReg), a method designed to balance information acquisition among modalities. Specifically, InfoReg slows down the information acquisition process of information-sufficient modalities during the prime learning window, which could promote information acquisition of information-insufficient modalities. This regulation enables a more balanced learning process and improves the overall performance of the multimodal network. Experiments show that InfoReg outperforms related multimodal imbalanced methods across various datasets, achieving superior model performance. The code is available at https://github.com/GeWu-Lab/InfoReg_CVPR2025.
Enhancing Modality Representation and Alignment for Multimodal Cold-start Active Learning
Dec 12, 2024Training multimodal models requires a large amount of labeled data. Active learning (AL) aim to reduce labeling costs. Most AL methods employ warm-start approaches, which rely on sufficient labeled data to train a well-calibrated model that can assess the uncertainty and diversity of unlabeled data. However, when assembling a dataset, labeled data are often scarce initially, leading to a cold-start problem. Additionally, most AL methods seldom address multimodal data, highlighting a research gap in this field. Our research addresses these issues by developing a two-stage method for Multi-Modal Cold-Start Active Learning (MMCSAL). Firstly, we observe the modality gap, a significant distance between the centroids of representations from different modalities, when only using cross-modal pairing information as self-supervision signals. This modality gap affects data selection process, as we calculate both uni-modal and cross-modal distances. To address this, we introduce uni-modal prototypes to bridge the modality gap. Secondly, conventional AL methods often falter in multimodal scenarios where alignment between modalities is overlooked. Therefore, we propose enhancing cross-modal alignment through regularization, thereby improving the quality of selected multimodal data pairs in AL. Finally, our experiments demonstrate MMCSAL's efficacy in selecting multimodal data pairs across three multimodal datasets.
On-the-fly Modulation for Balanced Multimodal Learning
Oct 15, 2024



Multimodal learning is expected to boost model performance by integrating information from different modalities. However, its potential is not fully exploited because the widely-used joint training strategy, which has a uniform objective for all modalities, leads to imbalanced and under-optimized uni-modal representations. Specifically, we point out that there often exists modality with more discriminative information, e.g., vision of playing football and sound of blowing wind. They could dominate the joint training process, resulting in other modalities being significantly under-optimized. To alleviate this problem, we first analyze the under-optimized phenomenon from both the feed-forward and the back-propagation stages during optimization. Then, On-the-fly Prediction Modulation (OPM) and On-the-fly Gradient Modulation (OGM) strategies are proposed to modulate the optimization of each modality, by monitoring the discriminative discrepancy between modalities during training. Concretely, OPM weakens the influence of the dominant modality by dropping its feature with dynamical probability in the feed-forward stage, while OGM mitigates its gradient in the back-propagation stage. In experiments, our methods demonstrate considerable improvement across a variety of multimodal tasks. These simple yet effective strategies not only enhance performance in vanilla and task-oriented multimodal models, but also in more complex multimodal tasks, showcasing their effectiveness and flexibility. The source code is available at \url{https://github.com/GeWu-Lab/BML_TPAMI2024}.
Diagnosing and Re-learning for Balanced Multimodal Learning
Jul 12, 2024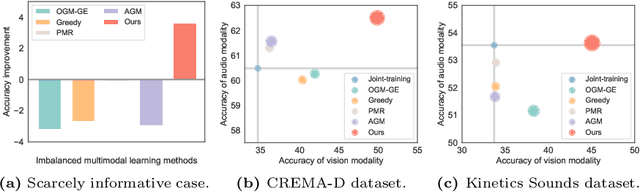
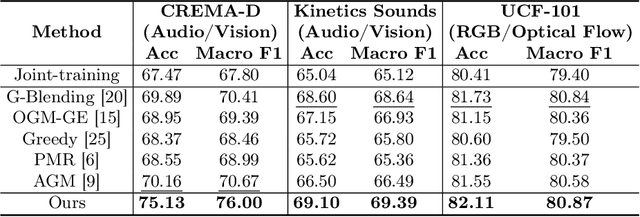
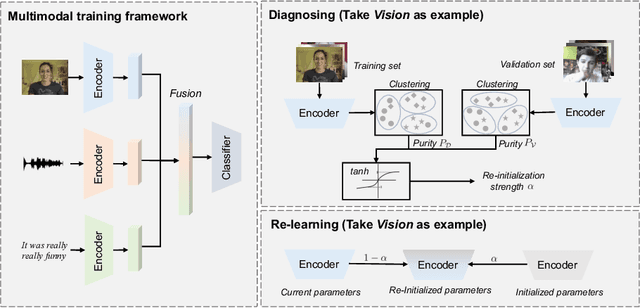
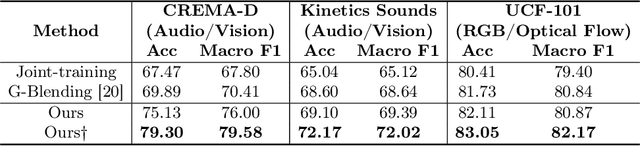
To overcome the imbalanced multimodal learning problem, where models prefer the training of specific modalities, existing methods propose to control the training of uni-modal encoders from different perspectives, taking the inter-modal performance discrepancy as the basis. However, the intrinsic limitation of modality capacity is ignored. The scarcely informative modalities can be recognized as ``worse-learnt'' ones, which could force the model to memorize more noise, counterproductively affecting the multimodal model ability. Moreover, the current modality modulation methods narrowly concentrate on selected worse-learnt modalities, even suppressing the training of others. Hence, it is essential to consider the intrinsic limitation of modality capacity and take all modalities into account during balancing. To this end, we propose the Diagnosing \& Re-learning method. The learning state of each modality is firstly estimated based on the separability of its uni-modal representation space, and then used to softly re-initialize the corresponding uni-modal encoder. In this way, the over-emphasizing of scarcely informative modalities is avoided. In addition, encoders of worse-learnt modalities are enhanced, simultaneously avoiding the over-training of other modalities. Accordingly, multimodal learning is effectively balanced and enhanced. Experiments covering multiple types of modalities and multimodal frameworks demonstrate the superior performance of our simple-yet-effective method for balanced multimodal learning. The source code and dataset are available at \url{https://github.com/GeWu-Lab/Diagnosing_Relearning_ECCV2024}.
MMPareto: Boosting Multimodal Learning with Innocent Unimodal Assistance
May 28, 2024



Multimodal learning methods with targeted unimodal learning objectives have exhibited their superior efficacy in alleviating the imbalanced multimodal learning problem. However, in this paper, we identify the previously ignored gradient conflict between multimodal and unimodal learning objectives, potentially misleading the unimodal encoder optimization. To well diminish these conflicts, we observe the discrepancy between multimodal loss and unimodal loss, where both gradient magnitude and covariance of the easier-to-learn multimodal loss are smaller than the unimodal one. With this property, we analyze Pareto integration under our multimodal scenario and propose MMPareto algorithm, which could ensure a final gradient with direction that is common to all learning objectives and enhanced magnitude to improve generalization, providing innocent unimodal assistance. Finally, experiments across multiple types of modalities and frameworks with dense cross-modal interaction indicate our superior and extendable method performance. Our method is also expected to facilitate multi-task cases with a clear discrepancy in task difficulty, demonstrating its ideal scalability. The source code and dataset are available at https://github.com/GeWu-Lab/MMPareto_ICML2024.
Multimodal Fusion on Low-quality Data: A Comprehensive Survey
Apr 27, 2024



Multimodal fusion focuses on integrating information from multiple modalities with the goal of more accurate prediction, which has achieved remarkable progress in a wide range of scenarios, including autonomous driving and medical diagnosis. However, the reliability of multimodal fusion remains largely unexplored especially under low-quality data settings. This paper surveys the common challenges and recent advances of multimodal fusion in the wild and presents them in a comprehensive taxonomy. From a data-centric view, we identify four main challenges that are faced by multimodal fusion on low-quality data, namely (1) noisy multimodal data that are contaminated with heterogeneous noises, (2) incomplete multimodal data that some modalities are missing, (3) imbalanced multimodal data that the qualities or properties of different modalities are significantly different and (4) quality-varying multimodal data that the quality of each modality dynamically changes with respect to different samples. This new taxonomy will enable researchers to understand the state of the field and identify several potential directions. We also provide discussion for the open problems in this field together with interesting future research directions.