 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fuzzy Reinforcement LSTM-based Long-term Prediction Model for Fault Conditions in Nuclear Power Plants
Nov 13, 2024

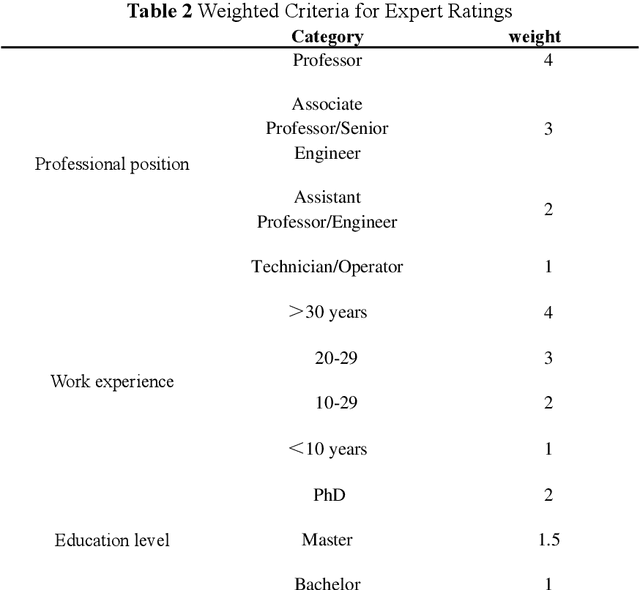

Early fault detection and timely maintenance scheduling can significantly mitigate operational risks in NPPs and enhance the reliability of operator decision-making. Therefore, it is necessary to develop an efficient Prognostics and Health Management (PHM) multi-step prediction model for predicting of system health status and prompt execution of maintenance operations. In this study, we propose a novel predictive model that integrates reinforcement learning with Long Short-Term Memory (LSTM) neural networks and the Expert Fuzzy Evaluation Method. The model is validated using parameter data for 20 different breach sizes in the Main Steam Line Break (MSLB) accident condition of the CPR1000 pressurized water reactor simulation model and it demonstrates a remarkable capability in accurately forecasting NPP parameter changes up to 128 steps ahead (with a time interval of 10 seconds per step, i.e., 1280 seconds), thereby satisfying the temporal advance requirement for fault prognostics in NPPs. Furthermore, this method provides an effective reference solution for PHM applications such as anomaly detection and remaining useful life prediction.
Research on fault diagnosis of nuclear power first-second circuit based on hierarchical multi-granularity classification network
Nov 12, 2024
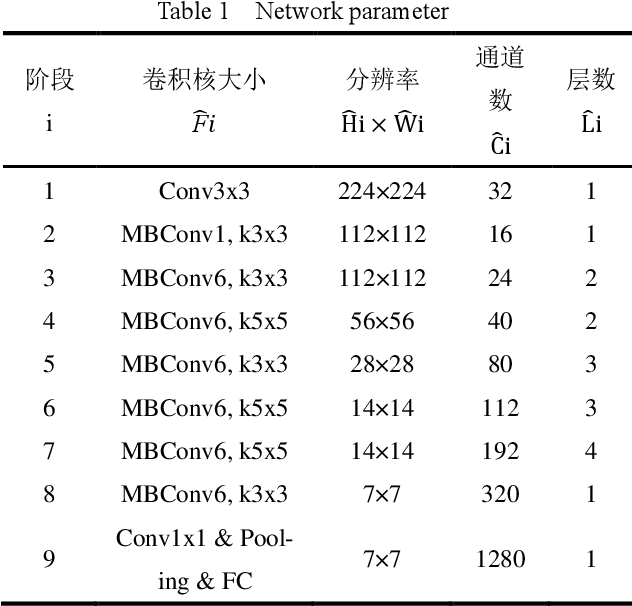
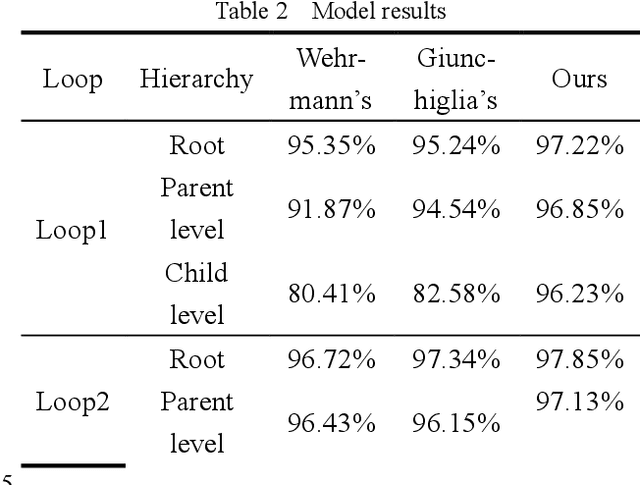

The safe and reliable operation of complex electromechanical systems in nuclear power plants is crucial for the safe production of nuclear power plants and their nuclear power unit. Therefore, accurate and timely fault diagnosis of nuclear power systems is of great significance for ensuring the safe and reliable operation of nuclear power plants. The existing fault diagnosis methods mainly target a single device or subsystem, making it difficult to analyze the inherent connections and mutual effects between different types of faults at the entire unit level. This article uses the AP1000 full-scale simulator to simulate the important mechanical component failures of some key systems in the primary and secondary circuits of nuclear power units, and constructs a fault dataset. Meanwhile, a hierarchical multi granularity classification fault diagnosis model based on the EfficientNet large model is proposed, aiming to achieve hierarchical classification of nuclear power faults. The results indicate that the proposed fault diagnosis model can effectively classify faults in different circuits and system components of nuclear power units into hierarchical categories. However, the fault dataset in this study was obtained from a simulator, which may introduce additional information due to parameter redundancy, thereby affecting the diagnostic performance of the model.
Research on an intelligent fault diagnosis method for nuclear power plants based on ETCN-SSA combined algorithm
Nov 11, 2024



Utilizing fault diagnosis methods is crucial for nuclear power professionals to achieve efficient and accurate fault diagnosis for nuclear power plants (NPPs). The performance of traditional methods is limited by their dependence on complex feature extraction and skilled expert knowledge, which can be time-consuming and subjective. This paper proposes a novel intelligent fault diagnosis method for NPPs that combines enhanced temporal convolutional network (ETCN) with sparrow search algorithm (SSA). ETCN utilizes temporal convolutional network (TCN), self-attention (SA) mechanism and residual block for enhancing performance. ETCN excels at extracting local features and capturing time series information, while SSA adaptively optimizes its hyperparameters for superior performance. The proposed method's performance is experimentally verified on a CPR1000 simulation dataset. Compared to other advanced intelligent fault diagnosis methods, the proposed one demonstrates superior performance across all evaluation metrics. This makes it a promising tool for NPP intelligent fault diagnosis, ultimately enhancing operational reliability.
Efficiently improving key weather variables forecasting by performing the guided iterative prediction in latent space
Jul 27, 2024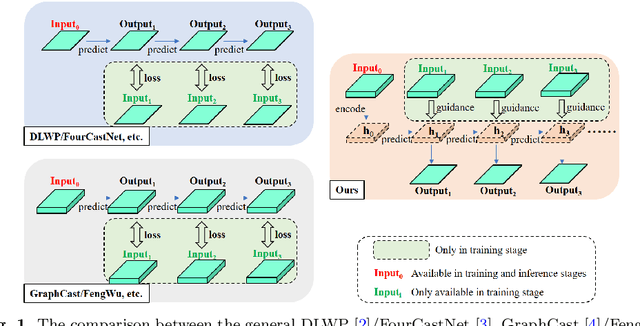

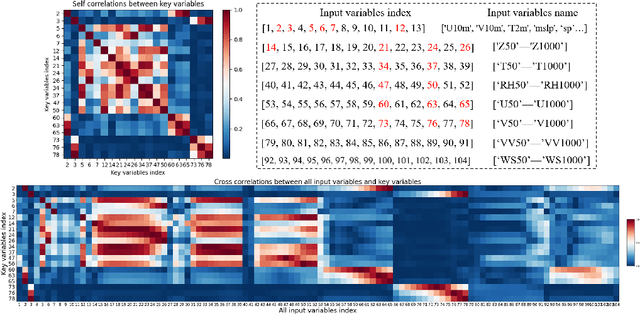

Weather forecasting refers to learning evolutionary patterns of some key upper-air and surface variables which is of great significance. Recently, deep learning-based methods have been increasingly applied in the field of weather forecasting due to their powerful feature learning capabilities. However, prediction methods based on the original space iteration struggle to effectively and efficiently utilize large number of weather variables. Therefore, we propose an 'encoding-prediction-decoding' prediction network. This network can efficiently benefit to more related input variables with key variables, that is, it can adaptively extract key variable-related low-dimensional latent feature from much more input atmospheric variables for iterative prediction. And we construct a loss function to guide the iteration of latent feature by utilizing multiple atmospheric variables in corresponding lead times. The obtained latent features through iterative prediction are then decoded to obtain the predicted values of key variables in multiple lead times. In addition, we improve the HTA algorithm in \cite{bi2023accurate} by inputting more time steps to enhance the temporal correlation between the prediction results and input variables. Both qualitative and quantitative prediction results on ERA5 dataset validate the superiority of our method over other methods. (The code will be available at https://github.com/rs-lsl/Kvp-lsi)
Diagnosing and Re-learning for Balanced Multimodal Learning
Jul 12, 2024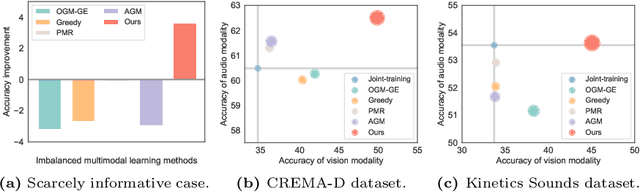
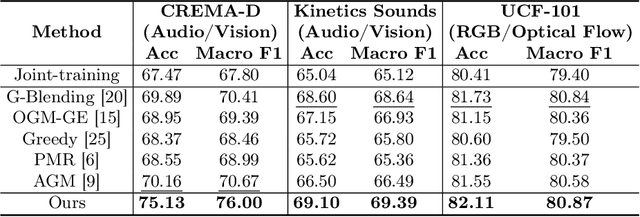
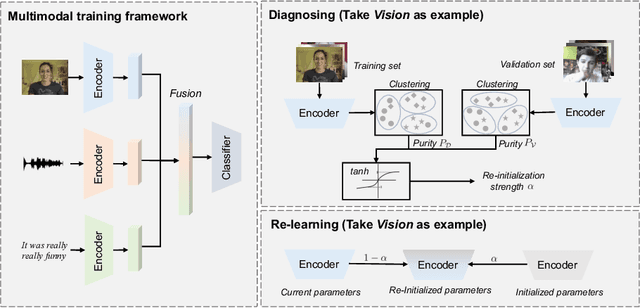
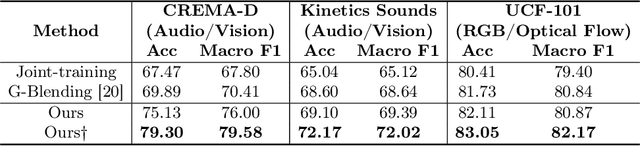
To overcome the imbalanced multimodal learning problem, where models prefer the training of specific modalities, existing methods propose to control the training of uni-modal encoders from different perspectives, taking the inter-modal performance discrepancy as the basis. However, the intrinsic limitation of modality capacity is ignored. The scarcely informative modalities can be recognized as ``worse-learnt'' ones, which could force the model to memorize more noise, counterproductively affecting the multimodal model ability. Moreover, the current modality modulation methods narrowly concentrate on selected worse-learnt modalities, even suppressing the training of others. Hence, it is essential to consider the intrinsic limitation of modality capacity and take all modalities into account during balancing. To this end, we propose the Diagnosing \& Re-learning method. The learning state of each modality is firstly estimated based on the separability of its uni-modal representation space, and then used to softly re-initialize the corresponding uni-modal encoder. In this way, the over-emphasizing of scarcely informative modalities is avoided. In addition, encoders of worse-learnt modalities are enhanced, simultaneously avoiding the over-training of other modalities. Accordingly, multimodal learning is effectively balanced and enhanced. Experiments covering multiple types of modalities and multimodal frameworks demonstrate the superior performance of our simple-yet-effective method for balanced multimodal learning. The source code and dataset are available at \url{https://github.com/GeWu-Lab/Diagnosing_Relearning_ECCV2024}.
Expressive and Generalizable Low-rank Adaptation for Large Models via Slow Cascaded Learning
Jul 01, 2024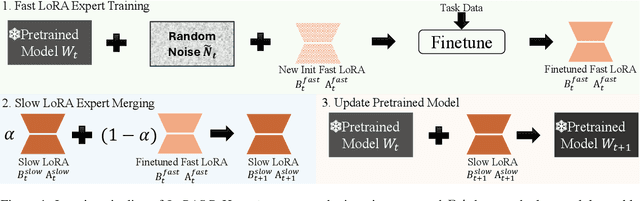



Efficient fine-tuning plays a fundamental role in modern large models, with low-rank adaptation emerging as a particularly promising approach. However, the existing variants of LoRA are hampered by limited expressiveness, a tendency to overfit, and sensitivity to hyperparameter settings. This paper presents LoRA Slow Cascade Learning (LoRASC), an innovative technique designed to enhance LoRA's expressiveness and generalization capabilities while preserving its training efficiency. Our approach augments expressiveness through a cascaded learning strategy that enables a mixture-of-low-rank adaptation, thereby increasing the model's ability to capture complex patterns. Additionally, we introduce a slow-fast update mechanism and cascading noisy tuning to bolster generalization. The extensive experiments on various language and vision datasets, as well as robustness benchmarks, demonstrate that the proposed method not only significantly outperforms existing baselines, but also mitigates overfitting, enhances model stability, and improves OOD robustness. Code will be release in https://github.com/microsoft/LoRASC very soon.
Spiking-PhysFormer: Camera-Based Remote Photoplethysmography with Parallel Spike-driven Transformer
Feb 09, 2024Artificial neural networks (ANNs) can help camera-based remote photoplethysmography (rPPG) in measuring cardiac activity and physiological signals from facial videos, such as pulse wave, heart rate and respiration rate with better accuracy. However, most existing ANN-based methods require substantial computing resources, which poses challenges for effective deployment on mobile devices. Spiking neural networks (SNNs), on the other hand, hold immense potential for energy-efficient deep learning owing to their binary and event-driven architecture. To the best of our knowledge, we are the first to introduce SNNs into the realm of rPPG, proposing a hybrid neural network (HNN) model, the Spiking-PhysFormer, aimed at reducing power consumption. Specifically, the proposed Spiking-PhyFormer consists of an ANN-based patch embedding block, SNN-based transformer blocks, and an ANN-based predictor head. First, to simplify the transformer block while preserving its capacity to aggregate local and global spatio-temporal features, we design a parallel spike transformer block to replace sequential sub-blocks. Additionally, we propose a simplified spiking self-attention mechanism that omits the value parameter without compromising the model's performance. Experiments conducted on four datasets-PURE, UBFC-rPPG, UBFC-Phys, and MMPD demonstrate that the proposed model achieves a 12.4\% reduction in power consumption compared to PhysFormer. Additionally, the power consumption of the transformer block is reduced by a factor of 12.2, while maintaining decent performance as PhysFormer and other ANN-based models.
DECO: Query-Based End-to-End Object Detection with ConvNets
Dec 21, 2023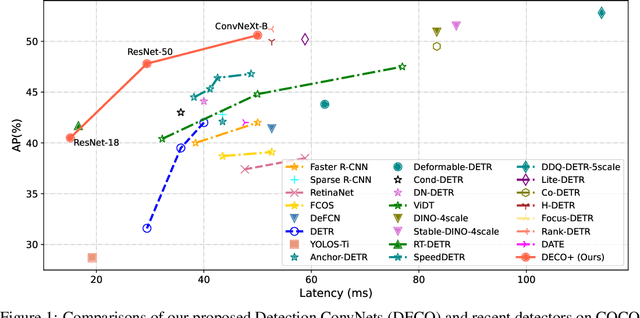
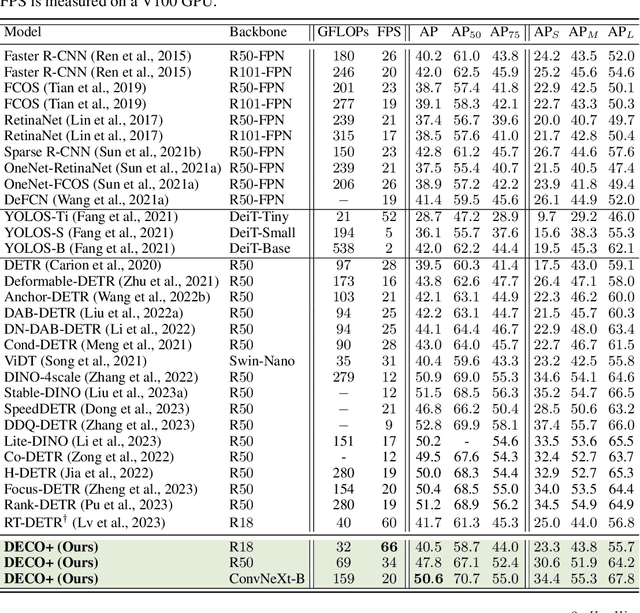
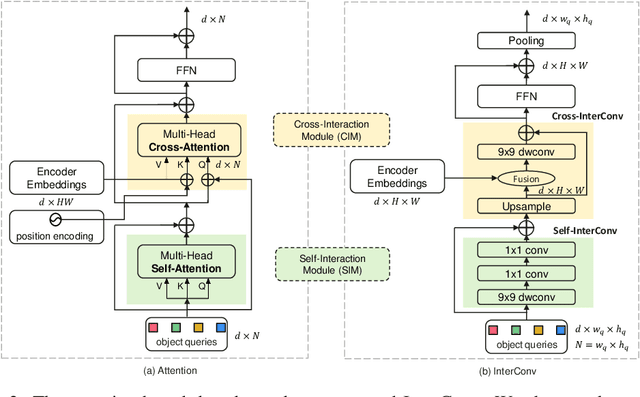
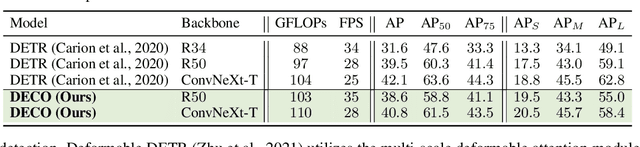
Detection Transformer (DETR) and its variants have shown great potential for accurate object detection in recent years. The mechanism of object query enables DETR family to directly obtain a fixed number of object predictions and streamlines the detection pipeline. Meanwhile, recent studies also reveal that with proper architecture design, convolution networks (ConvNets) also achieve competitive performance with transformers, \eg, ConvNeXt. To this end, in this paper we explore whether we could build a query-based end-to-end object detection framework with ConvNets instead of sophisticated transformer architecture. The proposed framework, \ie, Detection ConvNet (DECO), is composed of a backbone and convolutional encoder-decoder architecture. We carefully design the DECO encoder and propose a novel mechanism for our DECO decoder to perform interaction between object queries and image features via convolutional layers. We compare the proposed DECO against prior detectors on the challenging COCO benchmark. Despite its simplicity, our DECO achieves competitive performance in terms of detection accuracy and running speed. Specifically, with the ResNet-50 and ConvNeXt-Tiny backbone, DECO obtains $38.6\%$ and $40.8\%$ AP on COCO \textit{val} set with $35$ and $28$ FPS respectively and outperforms the DETR model. Incorporated with advanced multi-scale feature module, our DECO+ achieves $47.8\%$ AP with $34$ FPS. We hope the proposed DECO brings another perspective for designing object detection framework.
SAM-Deblur: Let Segment Anything Boost Image Deblurring
Sep 05, 2023Image deblurring is a critical task in the field of image restoration, aiming to eliminate blurring artifacts. However, the challenge of addressing non-uniform blurring leads to an ill-posed problem, which limits the generalization performance of existing deblurring models. To solve the problem, we propose a framework SAM-Deblur, integrating prior knowledge from the Segment Anything Model (SAM) into the deblurring task for the first time. In particular, SAM-Deblur is divided into three stages. First, We preprocess the blurred images, obtain image masks via SAM, and propose a mask dropout method for training to enhance model robustness. Then, to fully leverage the structural priors generated by SAM, we propose a Mask Average Pooling (MAP) unit specifically designed to average SAM-generated segmented areas, serving as a plug-and-play component which can be seamlessly integrated into existing deblurring networks. Finally, we feed the fused features generated by the MAP Unit into the deblurring model to obtain a sharp image. Experimental results on the RealBlurJ, ReloBlur, and REDS datasets reveal that incorporating our methods improves NAFNet's PSNR by 0.05, 0.96, and 7.03, respectively. Code will be available at \href{https://github.com/HPLQAQ/SAM-Deblur}{SAM-Deblur}.
Shield: Fast, Practical Defense and Vaccination for Deep Learning using JPEG Compression
Feb 19, 2018
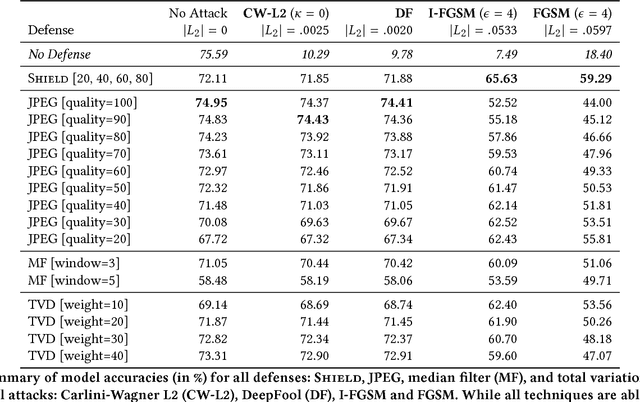

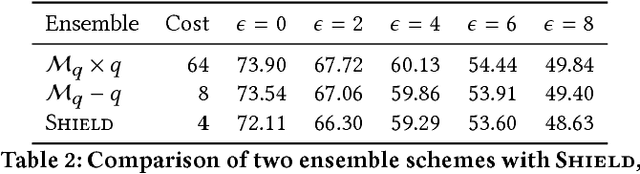
The rapidly growing body of research in adversarial machine learning has demonstrated that deep neural networks (DNNs) are highly vulnerable to adversarially generated images. This underscores the urgent need for practical defense that can be readily deployed to combat attacks in real-time. Observing that many attack strategies aim to perturb image pixels in ways that are visually imperceptible, we place JPEG compression at the core of our proposed Shield defense framework, utilizing its capability to effectively "compress away" such pixel manipulation. To immunize a DNN model from artifacts introduced by compression, Shield "vaccinates" a model by re-training it with compressed images, where different compression levels are applied to generate multiple vaccinated models that are ultimately used together in an ensemble defense. On top of that, Shield adds an additional layer of protection by employing randomization at test time that compresses different regions of an image using random compression levels, making it harder for an adversary to estimate the transformation performed. This novel combination of vaccination, ensembling, and randomization makes Shield a fortified multi-pronged protection. We conducted extensive, large-scale experiments using the ImageNet dataset, and show that our approaches eliminate up to 94% of black-box attacks and 98% of gray-box attacks delivered by the recent, strongest attacks, such as Carlini-Wagner's L2 and DeepFool. Our approaches are fast and work without requiring knowledge about the model.