 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Model Selection for Time Series Forecasting via LLMs
Apr 02, 2025


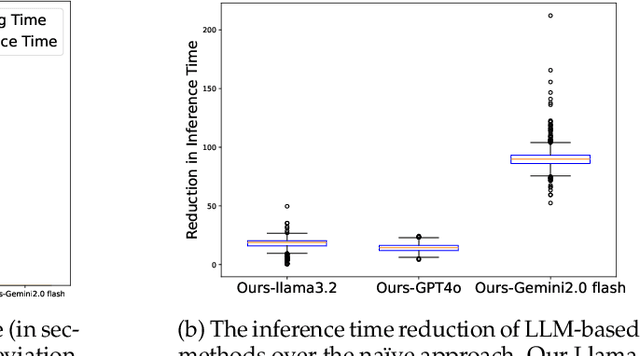
Model selection is a critical step in time series forecasting, traditionally requiring extensive performance evaluations across various datasets. Meta-learning approaches aim to automate this process, but they typically depend on pre-constructed performance matrices, which are costly to build. In this work, we propose to leverage Large Language Models (LLMs) as a lightweight alternative for model selection. Our method eliminates the need for explicit performance matrices by utilizing the inherent knowledge and reasoning capabilities of LLMs. Through extensive experiments with LLaMA, GPT and Gemini, we demonstrate that our approach outperforms traditional meta-learning techniques and heuristic baselines, while significantly reducing computational overhead. These findings underscore the potential of LLMs in efficient model selection for time series forecasting.
Research on fault diagnosis of nuclear power first-second circuit based on hierarchical multi-granularity classification network
Nov 12, 2024
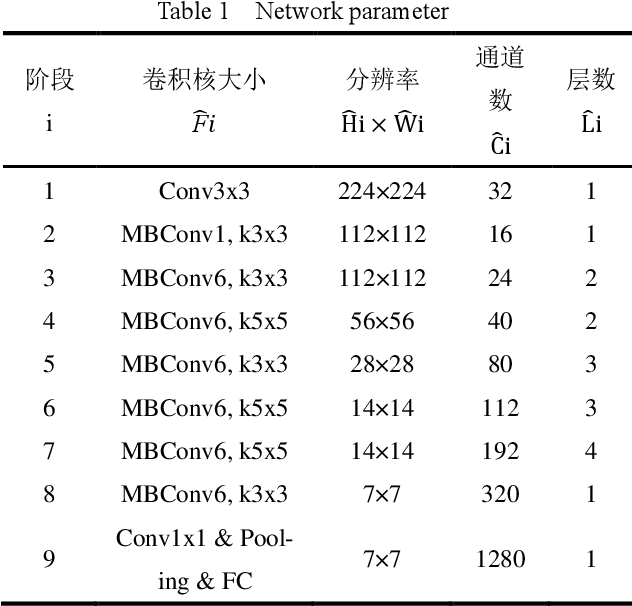
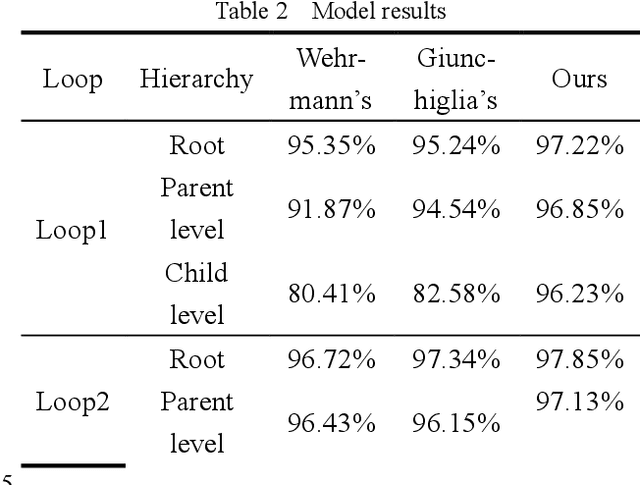

The safe and reliable operation of complex electromechanical systems in nuclear power plants is crucial for the safe production of nuclear power plants and their nuclear power unit. Therefore, accurate and timely fault diagnosis of nuclear power systems is of great significance for ensuring the safe and reliable operation of nuclear power plants. The existing fault diagnosis methods mainly target a single device or subsystem, making it difficult to analyze the inherent connections and mutual effects between different types of faults at the entire unit level. This article uses the AP1000 full-scale simulator to simulate the important mechanical component failures of some key systems in the primary and secondary circuits of nuclear power units, and constructs a fault dataset. Meanwhile, a hierarchical multi granularity classification fault diagnosis model based on the EfficientNet large model is proposed, aiming to achieve hierarchical classification of nuclear power faults. The results indicate that the proposed fault diagnosis model can effectively classify faults in different circuits and system components of nuclear power units into hierarchical categories. However, the fault dataset in this study was obtained from a simulator, which may introduce additional information due to parameter redundancy, thereby affecting the diagnostic performance of the model.
LawDNet: Enhanced Audio-Driven Lip Synthesis via Local Affine Warping Deformation
Sep 14, 2024In the domain of photorealistic avatar generation, the fidelity of audio-driven lip motion synthesis is essential for realistic virtual interactions. Existing methods face two key challenges: a lack of vivacity due to limited diversity in generated lip poses and noticeable anamorphose motions caused by poor temporal coherence. To address these issues, we propose LawDNet, a novel deep-learning architecture enhancing lip synthesis through a Local Affine Warping Deformation mechanism. This mechanism models the intricate lip movements in response to the audio input by controllable non-linear warping fields. These fields consist of local affine transformations focused on abstract keypoints within deep feature maps, offering a novel universal paradigm for feature warping in networks. Additionally, LawDNet incorporates a dual-stream discriminator for improved frame-to-frame continuity and employs face normalization techniques to handle pose and scene variations. Extensive evaluations demonstrate LawDNet's superior robustness and lip movement dynamism performance compared to previous methods. The advancements presented in this paper, including the methodologies, training data, source codes, and pre-trained models, will be made accessible to the research community.
Multi-objective Cross-task Learning via Goal-conditioned GPT-based Decision Transformers for Surgical Robot Task Automation
May 29, 2024



Surgical robot task automation has been a promising research topic for improving surgical efficiency and quality. Learning-based methods have been recognized as an interesting paradigm and been increasingly investigated. However, existing approaches encounter difficulties in long-horizon goal-conditioned tasks due to the intricate compositional structure, which requires decision-making for a sequence of sub-steps and understanding of inherent dynamics of goal-reaching tasks. In this paper, we propose a new learning-based framework by leveraging the strong reasoning capability of the GPT-based architecture to automate surgical robotic tasks. The key to our approach is developing a goal-conditioned decision transformer to achieve sequential representations with goal-aware future indicators in order to enhance temporal reasoning. Moreover, considering to exploit a general understanding of dynamics inherent in manipulations, thus making the model's reasoning ability to be task-agnostic, we also design a cross-task pretraining paradigm that uses multiple training objectives associated with data from diverse tasks. We have conducted extensive experiments on 10 tasks using the surgical robot learning simulator SurRoL~\cite{long2023human}. The results show that our new approach achieves promising performance and task versatility compared to existing methods. The learned trajectories can be deployed on the da Vinci Research Kit (dVRK) for validating its practicality in real surgical robot settings. Our project website is at: https://med-air.github.io/SurRoL.
Efficient Physically-based Simulation of Soft Bodies in Embodied Environment for Surgical Robot
Feb 02, 2024Surgical robot simulation platform plays a crucial role in enhancing training efficiency and advancing research on robot learning. Much effort have been made by scholars on developing open-sourced surgical robot simulators to facilitate research. We also developed SurRoL formerly, an open-source, da Vinci Research Kit (dVRK) compatible and interactive embodied environment for robot learning. Despite its advancements, the simulation of soft bodies still remained a major challenge within the open-source platforms available for surgical robotics. To this end, we develop an interactive physically based soft body simulation framework and integrate it to SurRoL. Specifically, we utilized a high-performance adaptation of the Material Point Method (MPM) along with the Neo-Hookean model to represent the deformable tissue. Lagrangian particles are used to track the motion and deformation of the soft body throughout the simulation and Eulerian grids are leveraged to discretize space and facilitate the calculation of forces, velocities, and other physical quantities. We also employed an efficient collision detection and handling strategy to simulate the interaction between soft body and rigid tool of the surgical robot. By employing the Taichi programming language, our implementation harnesses parallel computing to boost simulation speed. Experimental results show that our platform is able to simulate soft bodies efficiently with strong physical interpretability and plausible visual effects. These new features in SurRoL enable the efficient simulation of surgical tasks involving soft tissue manipulation and pave the path for further investigation of surgical robot learning. The code will be released in a new branch of SurRoL github repo.
Value-Informed Skill Chaining for Policy Learning of Long-Horizon Tasks with Surgical Robot
Jul 31, 2023



Reinforcement learning is still struggling with solving long-horizon surgical robot tasks which involve multiple steps over an extended duration of time due to the policy exploration challenge. Recent methods try to tackle this problem by skill chaining, in which the long-horizon task is decomposed into multiple subtasks for easing the exploration burden and subtask policies are temporally connected to complete the whole long-horizon task. However, smoothly connecting all subtask policies is difficult for surgical robot scenarios. Not all states are equally suitable for connecting two adjacent subtasks. An undesired terminate state of the previous subtask would make the current subtask policy unstable and result in a failed execution. In this work, we introduce value-informed skill chaining (ViSkill), a novel reinforcement learning framework for long-horizon surgical robot tasks. The core idea is to distinguish which terminal state is suitable for starting all the following subtask policies. To achieve this target, we introduce a state value function that estimates the expected success probability of the entire task given a state. Based on this value function, a chaining policy is learned to instruct subtask policies to terminate at the state with the highest value so that all subsequent policies are more likely to be connected for accomplishing the task. We demonstrate the effectiveness of our method on three complex surgical robot tasks from SurRoL, a comprehensive surgical simulation platform, achieving high task success rates and execution efficiency. Code is available at $\href{https://github.com/med-air/ViSkill}{\text{https://github.com/med-air/ViSkill}}$.
Human-in-the-loop Embodied Intelligence with Interactive Simulation Environment for Surgical Robot Learning
Jan 01, 2023



Surgical robot automation has attracted increasing research interest over the past decade, expecting its huge potential to benefit surgeons, nurses and patients. Recently, the learning paradigm of embodied AI has demonstrated promising ability to learn good control policies for various complex tasks, where embodied AI simulators play an essential role to facilitate relevant researchers. However, existing open-sourced simulators for surgical robot are still not sufficiently supporting human interactions through physical input devices, which further limits effective investigations on how human demonstrations would affect policy learning. In this paper, we study human-in-the-loop embodied intelligence with a new interactive simulation platform for surgical robot learning. Specifically, we establish our platform based on our previously released SurRoL simulator with several new features co-developed to allow high-quality human interaction via an input device. With these, we further propose to collect human demonstrations and imitate the action patterns to achieve more effective policy learning. We showcase the improvement of our simulation environment with the designed new features and tasks, and validate state-of-the-art reinforcement learning algorithms using the interactive environment. Promising results are obtained, with which we hope to pave the way for future research on surgical embodied intelligence. Our platform is released and will be continuously updated in the website: https://med-air.github.io/SurRoL/
CenterLoc3D: Monocular 3D Vehicle Localization Network for Roadside Surveillance Cameras
Apr 06, 2022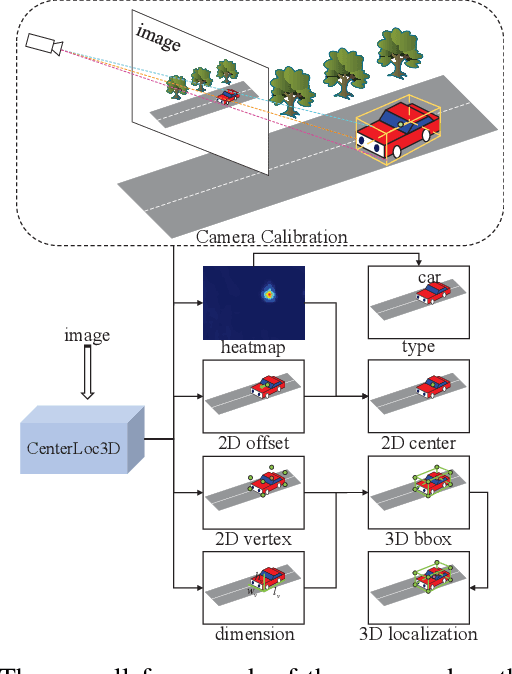
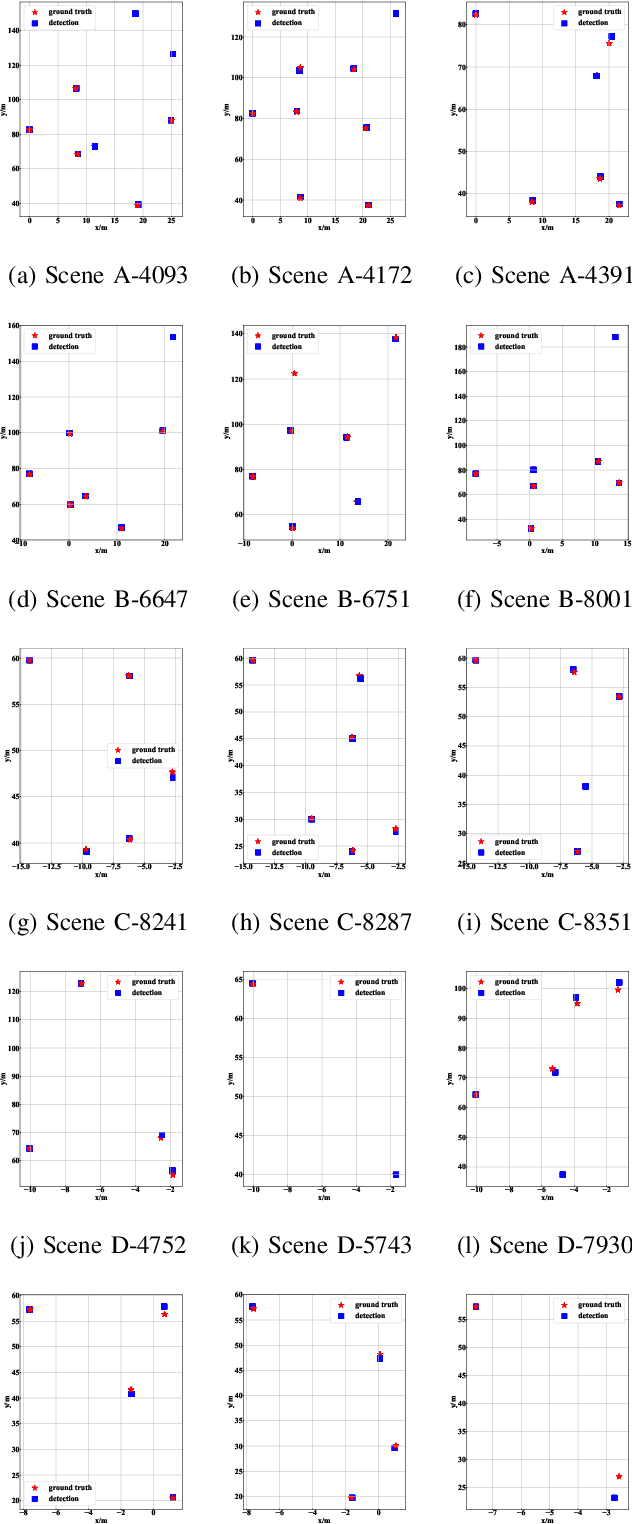
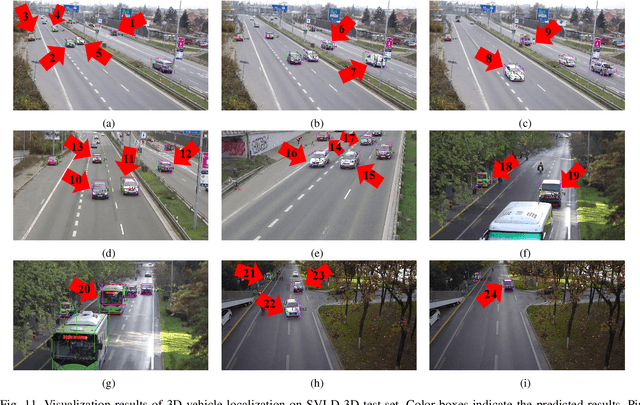
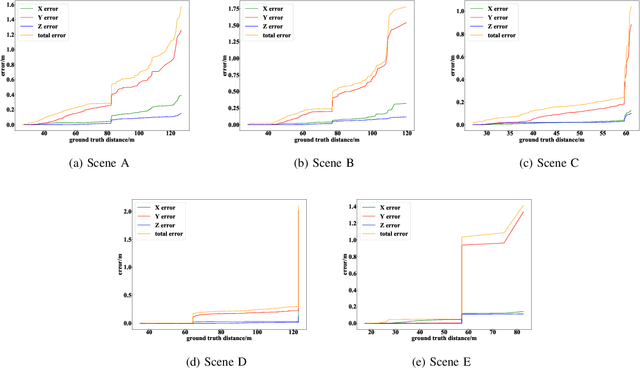
Monocular 3D vehicle localization is an important task in Intelligent Transportation System (ITS) and Cooperative Vehicle Infrastructure System (CVIS), which is usually achieved by monocular 3D vehicle detection. However, depth information cannot be obtained directly by monocular cameras due to the inherent imaging mechanism, resulting in more challenging monocular 3D tasks. Most of the current monocular 3D vehicle detection methods leverage 2D detectors and additional geometric modules, which reduces the efficiency. In this paper, we propose a 3D vehicle localization network CenterLoc3D for roadside monocular cameras, which directly predicts centroid and eight vertexes in image space, and the dimension of 3D bounding boxes without 2D detectors. To improve the precision of 3D vehicle localization, we propose a weighted-fusion module and a loss with spatial constraints embedded in CenterLoc3D. Firstly, the transformation matrix between 2D image space and 3D world space is solved by camera calibration. Secondly, vehicle type, centroid, eight vertexes, and the dimension of 3D vehicle bounding boxes are obtained by CenterLoc3D. Finally, centroid in 3D world space can be obtained by camera calibration and CenterLoc3D for 3D vehicle localization. To the best of our knowledge, this is the first application of 3D vehicle localization for roadside monocular cameras. Hence, we also propose a benchmark for this application including a dataset (SVLD-3D), an annotation tool (LabelImg-3D), and evaluation metrics. Through experimental validation, the proposed method achieves high accuracy and real-time performance.