 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFUN: Towards an Affordance Foundation Model for Functionality Understanding
Jun 01, 2026Affordance understanding bridges visual perception and physical action, serving as an explainable interface for robot manipulation in open and unstructured real-world environments. Yet, building an affordance foundation model that not only understands where and how the interaction should happen, but also generalizes across diverse environments, objects, and tasks, remains a long-standing research challenge. Existing methods typically address only part of this challenge, either localizing task-relevant regions without specifying executable motion, or predicting motion but with limited scalability. In this paper, we present ourmodel, a step towards an affordance foundation model for functionality understanding. From a single RGB-D observation and a language task description, ourmodel predicts a task-conditional functional mask (where to interact) and a 3D post-contact motion curve (how to interact). To support open-world generalization, we build a large-scale standardized data pipeline that converts heterogeneous robot, human, simulation, and real-world scan data into a shared affordance schema with language, masks, and object-centric 3D motion labels. We evaluate ourmodel from three aspects: for affordance segmentation, ourmodel outperforms all baselines by a large margin across 8 test sets from 4 benchmarks, improving mean gIoU/cIoU by +23.9/+26.3; for contact-point prediction, it predicts substantially more accurate points, with a 12.7--61.3% hit-rate gain over the best baseline; and for 3D motion, it achieves the best performance on all three test sets. ourmodel can be deployed for real-world robot manipulation without finetuning for robot embodiment or using task-specific heuristics, demonstrating the ability to adapt to open-world affordance tasks. Project page: https://www.zhaoningwang.com/AFUN
How Should LLMs Consume High-Quality Data? Optimal Data Scheduling via Quality-Aware Functional Scaling Laws
May 25, 2026High-quality data is scarce in large language model (LLM) training, yet how to schedule its use jointly with training dynamics lacks theoretical guidance. We extend functional scaling laws by incorporating a data-quality dimension, and solve the joint data-quality and batch-size scheduling problem in asymptotic closed form. The solution reveals two regimes and a dual role of high-quality data. In the noise-limited regime, high-quality data should be used as a signal amplifier: lowering the batch size converts cleaner data into more signal without amplifying noise. In the signal-limited regime, it should be used as a noise suppressor: late placement reduces terminal noise without sacrificing signal accumulation. Existing curriculum-style pipelines primarily exploit the second role by placing cleaner data late, but miss the first role because conventional decay schedules reduce update intensity exactly when high-quality data becomes available. Guided by this, we propose Drop-Stable-Rampup for LLM midtraining: upon the quality transition, drop the batch size, hold it stable to accumulate signal, then ramp up to suppress terminal noise. On a 15B Mixture-of-Experts model midtrained on 108B tokens, Drop-Stable-Rampup improves average accuracy over Warmup-Stable-Decay (WSD) by +1.70 and over Cosine-decay by +2.98, with particularly large gains on mathematical reasoning benchmarks such as GSM8K (+4.23) and MATH (+2.80).
HE-SNR: Uncovering Latent Logic via Entropy for Guiding Mid-Training on SWE-BENCH
Jan 28, 2026SWE-bench has emerged as the premier benchmark for evaluating Large Language Models on complex software engineering tasks. While these capabilities are fundamentally acquired during the mid-training phase and subsequently elicited during Supervised Fine-Tuning (SFT), there remains a critical deficit in metrics capable of guiding mid-training effectively. Standard metrics such as Perplexity (PPL) are compromised by the "Long-Context Tax" and exhibit weak correlation with downstream SWE performance. In this paper, we bridge this gap by first introducing a rigorous data filtering strategy. Crucially, we propose the Entropy Compression Hypothesis, redefining intelligence not by scalar Top-1 compression, but by the capacity to structure uncertainty into Entropy-Compressed States of low orders ("reasonable hesitation"). Grounded in this fine-grained entropy analysis, we formulate a novel metric, HE-SNR (High-Entropy Signal-to-Noise Ratio). Validated on industrial-scale Mixture-of-Experts (MoE) models across varying context windows (32K/128K), our approach demonstrates superior robustness and predictive power. This work provides both the theoretical foundation and practical tools for optimizing the latent potential of LLMs in complex engineering domains.
LodeStar: Long-horizon Dexterity via Synthetic Data Augmentation from Human Demonstrations
Aug 24, 2025Developing robotic systems capable of robustly executing long-horizon manipulation tasks with human-level dexterity is challenging, as such tasks require both physical dexterity and seamless sequencing of manipulation skills while robustly handling environment variations. While imitation learning offers a promising approach, acquiring comprehensive datasets is resource-intensive. In this work, we propose a learning framework and system LodeStar that automatically decomposes task demonstrations into semantically meaningful skills using off-the-shelf foundation models, and generates diverse synthetic demonstration datasets from a few human demos through reinforcement learning. These sim-augmented datasets enable robust skill training, with a Skill Routing Transformer (SRT) policy effectively chaining the learned skills together to execute complex long-horizon manipulation tasks. Experimental evaluations on three challenging real-world long-horizon dexterous manipulation tasks demonstrate that our approach significantly improves task performance and robustness compared to previous baselines. Videos are available at lodestar-robot.github.io.
Solving Vision Tasks with Simple Photoreceptors Instead of Cameras
Jun 17, 2024A de facto standard in solving computer vision problems is to use a common high-resolution camera and choose its placement on an agent (i.e., position and orientation) based on human intuition. On the other hand, extremely simple and well-designed visual sensors found throughout nature allow many organisms to perform diverse, complex behaviors. In this work, motivated by these examples, we raise the following questions: 1. How effective simple visual sensors are in solving vision tasks? 2. What role does their design play in their effectiveness? We explore simple sensors with resolutions as low as one-by-one pixel, representing a single photoreceptor First, we demonstrate that just a few photoreceptors can be enough to solve many tasks, such as visual navigation and continuous control, reasonably well, with performance comparable to that of a high-resolution camera. Second, we show that the design of these simple visual sensors plays a crucial role in their ability to provide useful information and successfully solve these tasks. To find a well-performing design, we present a computational design optimization algorithm and evaluate its effectiveness across different tasks and domains, showing promising results. Finally, we perform a human survey to evaluate the effectiveness of intuitive designs devised manually by humans, showing that the computationally found design is among the best designs in most cases.
Multi-objective Cross-task Learning via Goal-conditioned GPT-based Decision Transformers for Surgical Robot Task Automation
May 29, 2024



Surgical robot task automation has been a promising research topic for improving surgical efficiency and quality. Learning-based methods have been recognized as an interesting paradigm and been increasingly investigated. However, existing approaches encounter difficulties in long-horizon goal-conditioned tasks due to the intricate compositional structure, which requires decision-making for a sequence of sub-steps and understanding of inherent dynamics of goal-reaching tasks. In this paper, we propose a new learning-based framework by leveraging the strong reasoning capability of the GPT-based architecture to automate surgical robotic tasks. The key to our approach is developing a goal-conditioned decision transformer to achieve sequential representations with goal-aware future indicators in order to enhance temporal reasoning. Moreover, considering to exploit a general understanding of dynamics inherent in manipulations, thus making the model's reasoning ability to be task-agnostic, we also design a cross-task pretraining paradigm that uses multiple training objectives associated with data from diverse tasks. We have conducted extensive experiments on 10 tasks using the surgical robot learning simulator SurRoL~\cite{long2023human}. The results show that our new approach achieves promising performance and task versatility compared to existing methods. The learned trajectories can be deployed on the da Vinci Research Kit (dVRK) for validating its practicality in real surgical robot settings. Our project website is at: https://med-air.github.io/SurRoL.
InteractionNet: Joint Planning and Prediction for Autonomous Driving with Transformers
Sep 07, 2023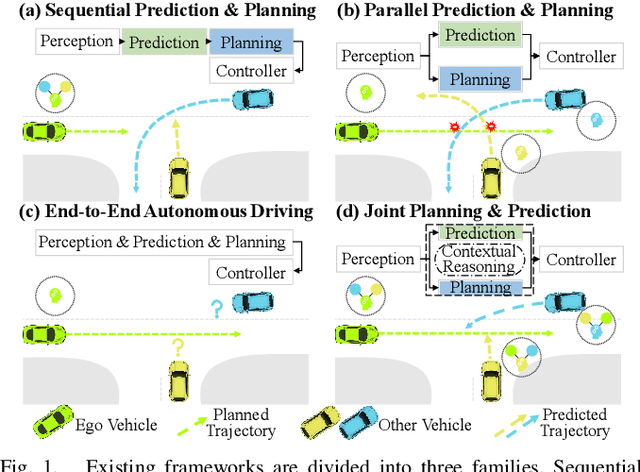
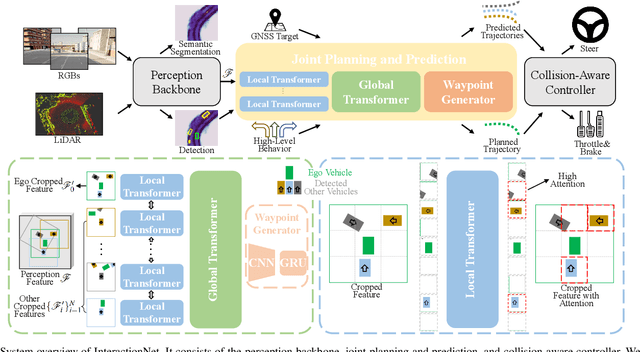
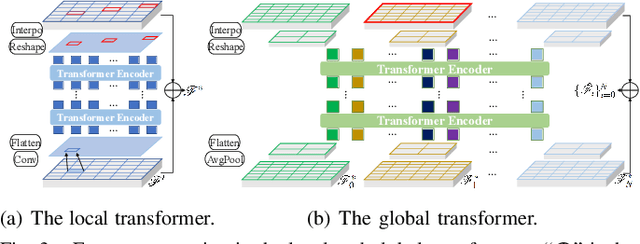

Planning and prediction are two important modules of autonomous driving and have experienced tremendous advancement recently. Nevertheless, most existing methods regard planning and prediction as independent and ignore the correlation between them, leading to the lack of consideration for interaction and dynamic changes of traffic scenarios. To address this challenge, we propose InteractionNet, which leverages transformer to share global contextual reasoning among all traffic participants to capture interaction and interconnect planning and prediction to achieve joint. Besides, InteractionNet deploys another transformer to help the model pay extra attention to the perceived region containing critical or unseen vehicles. InteractionNet outperforms other baselines in several benchmarks, especially in terms of safety, which benefits from the joint consideration of planning and forecasting. The code will be available at https://github.com/fujiawei0724/InteractionNet.
Complementing Onboard Sensors with Satellite Map: A New Perspective for HD Map Construction
Aug 29, 2023



High-Definition (HD) maps play a crucial role in autonomous driving systems. Recent methods have attempted to construct HD maps in real-time based on information obtained from vehicle onboard sensors. However, the performance of these methods is significantly susceptible to the environment surrounding the vehicle due to the inherent limitation of onboard sensors, such as weak capacity for long-range detection. In this study, we demonstrate that supplementing onboard sensors with satellite maps can enhance the performance of HD map construction methods, leveraging the broad coverage capability of satellite maps. For the purpose of further research, we release the satellite map tiles as a complementary dataset of nuScenes dataset. Meanwhile, we propose a hierarchical fusion module that enables better fusion of satellite maps information with existing methods. Specifically, we design an attention mask based on segmentation and distance, applying the cross-attention mechanism to fuse onboard Bird's Eye View (BEV) features and satellite features in feature-level fusion. An alignment module is introduced before concatenation in BEV-level fusion to mitigate the impact of misalignment between the two features. The experimental results on the augmented nuScenes dataset showcase the seamless integration of our module into three existing HD map construction methods. It notably enhances their performance in both HD map semantic segmentation and instance detection tasks.
Learning Deep Sensorimotor Policies for Vision-based Autonomous Drone Racing
Oct 26, 2022



Autonomous drones can operate in remote and unstructured environments, enabling various real-world applications. However, the lack of effective vision-based algorithms has been a stumbling block to achieving this goal. Existing systems often require hand-engineered components for state estimation, planning, and control. Such a sequential design involves laborious tuning, human heuristics, and compounding delays and errors. This paper tackles the vision-based autonomous-drone-racing problem by learning deep sensorimotor policies. We use contrastive learning to extract robust feature representations from the input images and leverage a two-stage learning-by-cheating framework for training a neural network policy. The resulting policy directly infers control commands with feature representations learned from raw images, forgoing the need for globally-consistent state estimation, trajectory planning, and handcrafted control design. Our experimental results indicate that our vision-based policy can achieve the same level of racing performance as the state-based policy while being robust against different visual disturbances and distractors. We believe this work serves as a stepping-stone toward developing intelligent vision-based autonomous systems that control the drone purely from image inputs, like human pilots.