 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal-Horizon Social Robot Navigation in Heterogeneous Crowds
Feb 28, 2026Navigating social robots in dense, dynamic crowds is challenging due to environmental uncertainty and complex human-robot interactions. While Model Predictive Control (MPC) offers strong real-time performance, its reliance on a fixed prediction horizon limits adaptability to changing environments and social dynamics. Furthermore, most MPC approaches treat pedestrians as homogeneous obstacles, ignoring social heterogeneity and cooperative or adversarial interactions, which often causes the Frozen Robot Problem in partially observable real-world environments. In this paper, we identify the planning horizon as a socially conditioned decision variable rather than a fixed design choice. Building on this insight, we propose an optimal-horizon social navigation framework that optimizes MPC foresight online according to inferred social context. A spatio-temporal Transformer infers pedestrian cooperation attributes from local trajectory observations, which serve as social priors for a reinforcement learning policy that optimally selects the prediction horizon under a task-driven objective. The resulting horizon-aware MPC incorporates socially conditioned safety constraints to balance navigation efficiency and interaction safety. Extensive simulations and real-world robot experiments demonstrate that optimal foresight selection is critical for robust social navigation in partially observable crowds. Compared to state-of-the-art baselines, the proposed approach achieves a 6.8\% improvement in success rate, reduces collisions by 50\%, and shortens navigation time by 19\%, with a low timeout rate of 0.8\%, validating the necessity of socially optimal planning horizons for efficient and safe robot navigation in crowded environments. Code and videos are available at Under Review.
StructVPR++: Distill Structural and Semantic Knowledge with Weighting Samples for Visual Place Recognition
Mar 09, 2025Visual place recognition is a challenging task for autonomous driving and robotics, which is usually considered as an image retrieval problem. A commonly used two-stage strategy involves global retrieval followed by re-ranking using patch-level descriptors. Most deep learning-based methods in an end-to-end manner cannot extract global features with sufficient semantic information from RGB images. In contrast, re-ranking can utilize more explicit structural and semantic information in one-to-one matching process, but it is time-consuming. To bridge the gap between global retrieval and re-ranking and achieve a good trade-off between accuracy and efficiency, we propose StructVPR++, a framework that embeds structural and semantic knowledge into RGB global representations via segmentation-guided distillation. Our key innovation lies in decoupling label-specific features from global descriptors, enabling explicit semantic alignment between image pairs without requiring segmentation during deployment. Furthermore, we introduce a sample-wise weighted distillation strategy that prioritizes reliable training pairs while suppressing noisy ones. Experiments on four benchmarks demonstrate that StructVPR++ surpasses state-of-the-art global methods by 5-23% in Recall@1 and even outperforms many two-stage approaches, achieving real-time efficiency with a single RGB input.
Leveraging Anchor-based LiDAR 3D Object Detection via Point Assisted Sample Selection
Mar 04, 2024



3D object detection based on LiDAR point cloud and prior anchor boxes is a critical technology for autonomous driving environment perception and understanding. Nevertheless, an overlooked practical issue in existing methods is the ambiguity in training sample allocation based on box Intersection over Union (IoU_box). This problem impedes further enhancements in the performance of anchor-based LiDAR 3D object detectors. To tackle this challenge, this paper introduces a new training sample selection method that utilizes point cloud distribution for anchor sample quality measurement, named Point Assisted Sample Selection (PASS). This method has undergone rigorous evaluation on two widely utilized datasets. Experimental results demonstrate that the application of PASS elevates the average precision of anchor-based LiDAR 3D object detectors to a novel state-of-the-art, thereby proving the effectiveness of the proposed approach. The codes will be made available at https://github.com/XJTU-Haolin/Point_Assisted_Sample_Selection.
InteractionNet: Joint Planning and Prediction for Autonomous Driving with Transformers
Sep 07, 2023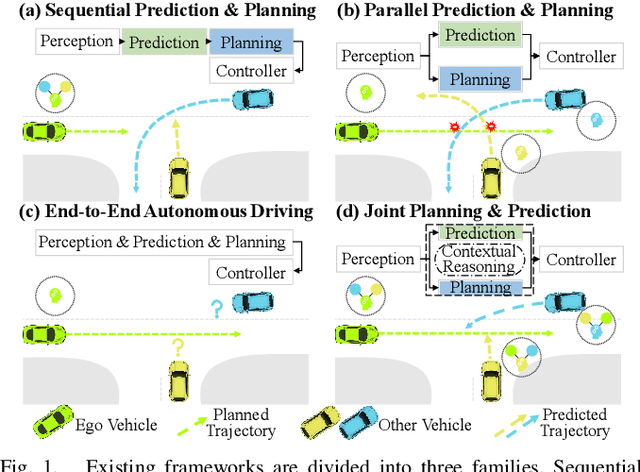
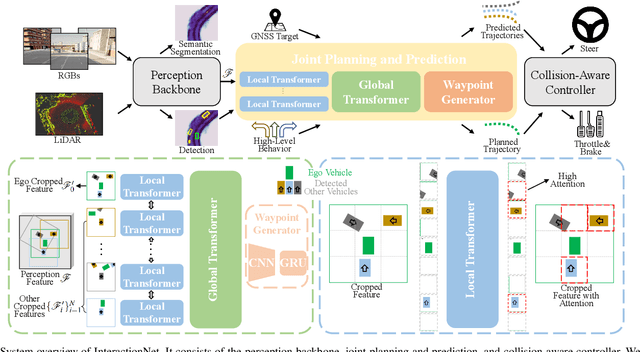
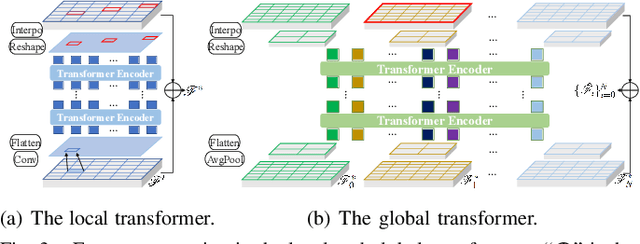

Planning and prediction are two important modules of autonomous driving and have experienced tremendous advancement recently. Nevertheless, most existing methods regard planning and prediction as independent and ignore the correlation between them, leading to the lack of consideration for interaction and dynamic changes of traffic scenarios. To address this challenge, we propose InteractionNet, which leverages transformer to share global contextual reasoning among all traffic participants to capture interaction and interconnect planning and prediction to achieve joint. Besides, InteractionNet deploys another transformer to help the model pay extra attention to the perceived region containing critical or unseen vehicles. InteractionNet outperforms other baselines in several benchmarks, especially in terms of safety, which benefits from the joint consideration of planning and forecasting. The code will be available at https://github.com/fujiawei0724/InteractionNet.
MLF-DET: Multi-Level Fusion for Cross-Modal 3D Object Detection
Jul 18, 2023In this paper, we propose a novel and effective Multi-Level Fusion network, named as MLF-DET, for high-performance cross-modal 3D object DETection, which integrates both the feature-level fusion and decision-level fusion to fully utilize the information in the image. For the feature-level fusion, we present the Multi-scale Voxel Image fusion (MVI) module, which densely aligns multi-scale voxel features with image features. For the decision-level fusion, we propose the lightweight Feature-cued Confidence Rectification (FCR) module which further exploits image semantics to rectify the confidence of detection candidates. Besides, we design an effective data augmentation strategy termed Occlusion-aware GT Sampling (OGS) to reserve more sampled objects in the training scenes, so as to reduce overfitting. Extensive experiments on the KITTI dataset demonstrate the effectiveness of our method. Notably, on the extremely competitive KITTI car 3D object detection benchmark, our method reaches 82.89% moderate AP and achieves state-of-the-art performance without bells and whistles.
StructVPR: Distill Structural Knowledge with Weighting Samples for Visual Place Recognition
Dec 09, 2022Visual place recognition (VPR) is usually considered as a specific image retrieval problem. Limited by existing training frameworks, most deep learning-based works cannot extract sufficiently stable global features from RGB images and rely on a time-consuming re-ranking step to exploit spatial structural information for better performance. In this paper, we propose StructVPR, a novel training architecture for VPR, to enhance structural knowledge in RGB global features and thus improve feature stability in a constantly changing environment. Specifically, StructVPR uses segmentation images as a more definitive source of structural knowledge input into a CNN network and applies knowledge distillation to avoid online segmentation and inference of seg-branch in testing. Considering that not all samples contain high-quality and helpful knowledge, and some even hurt the performance of distillation, we partition samples and weigh each sample's distillation loss to enhance the expected knowledge precisely. Finally, StructVPR achieves impressive performance on several benchmarks using only global retrieval and even outperforms many two-stage approaches by a large margin. After adding additional re-ranking, ours achieves state-of-the-art performance while maintaining a low computational cost.
Model-based Decision Making with Imagination for Autonomous Parking
Aug 25, 2021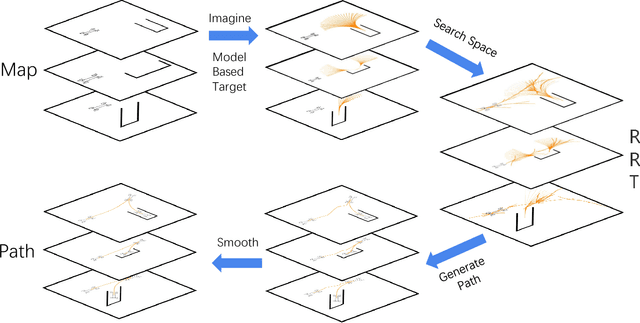
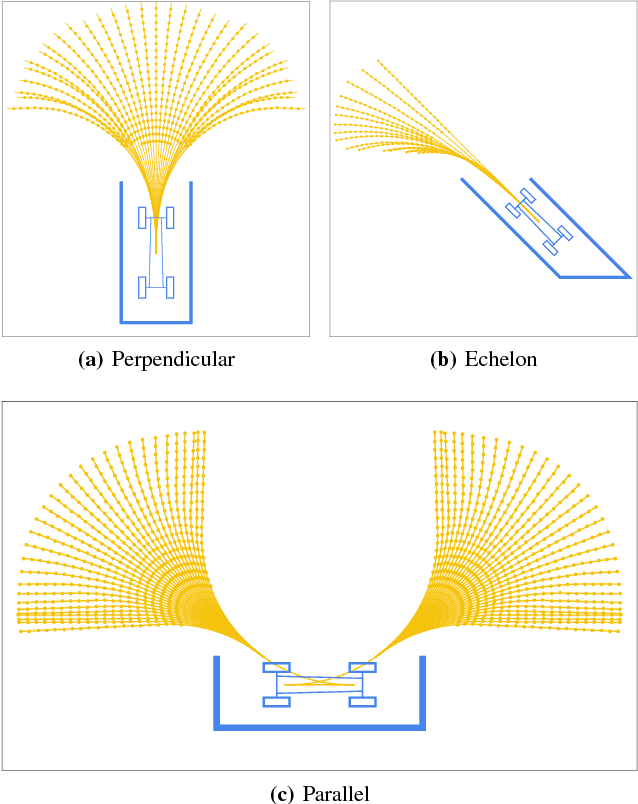
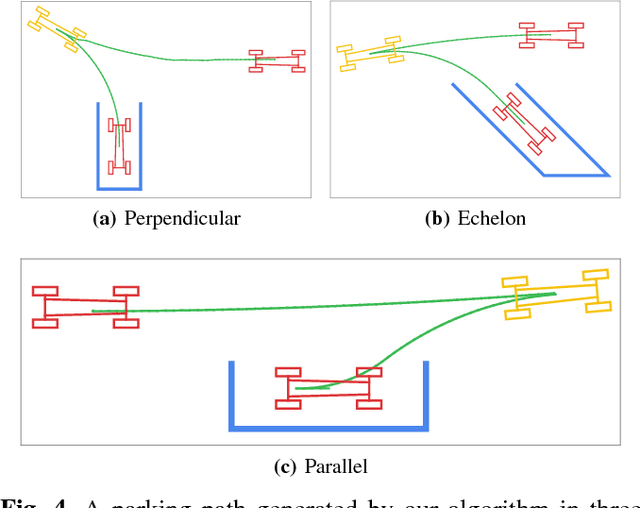
Autonomous parking technology is a key concept within autonomous driving research. This paper will propose an imaginative autonomous parking algorithm to solve issues concerned with parking. The proposed algorithm consists of three parts: an imaginative model for anticipating results before parking, an improved rapid-exploring random tree (RRT) for planning a feasible trajectory from a given start point to a parking lot, and a path smoothing module for optimizing the efficiency of parking tasks. Our algorithm is based on a real kinematic vehicle model; which makes it more suitable for algorithm application on real autonomous cars. Furthermore, due to the introduction of the imagination mechanism, the processing speed of our algorithm is ten times faster than that of traditional methods, permitting the realization of real-time planning simultaneously. In order to evaluate the algorithm's effectiveness, we have compared our algorithm with traditional RRT, within three different parking scenarios. Ultimately, results show that our algorithm is more stable than traditional RRT and performs better in terms of efficiency and quality.
* Published by IEEE IV 2018
Traffic Agent Trajectory Prediction Using Social Convolution and Attention Mechanism
Jul 06, 2020
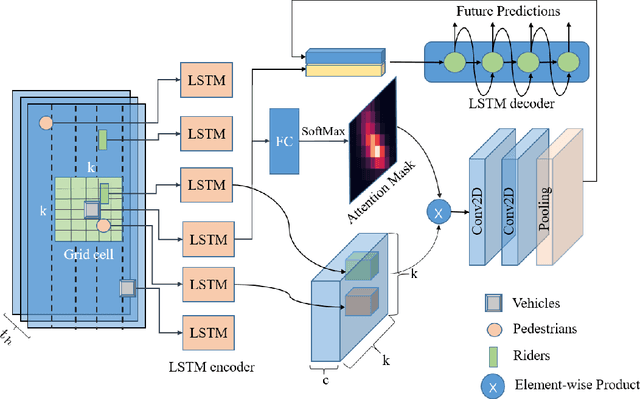
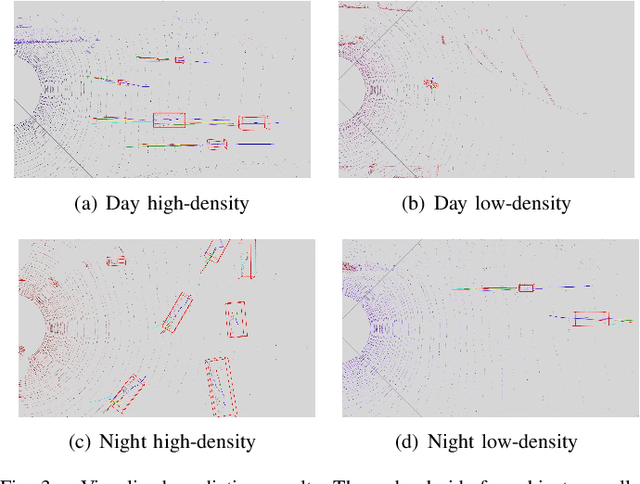
The trajectory prediction is significant for the decision-making of autonomous driving vehicles. In this paper, we propose a model to predict the trajectories of target agents around an autonomous vehicle. The main idea of our method is considering the history trajectories of the target agent and the influence of surrounding agents on the target agent. To this end, we encode the target agent history trajectories as an attention mask and construct a social map to encode the interactive relationship between the target agent and its surrounding agents. Given a trajectory sequence, the LSTM networks are firstly utilized to extract the features for all agents, based on which the attention mask and social map are formed. Then, the attention mask and social map are fused to get the fusion feature map, which is processed by the social convolution to obtain a fusion feature representation. Finally, this fusion feature is taken as the input of a variable-length LSTM to predict the trajectory of the target agent. We note that the variable-length LSTM enables our model to handle the case that the number of agents in the sensing scope is highly dynamic in traffic scenes. To verify the effectiveness of our method, we widely compare with several methods on a public dataset, achieving a 20% error decrease. In addition, the model satisfies the real-time requirement with the 32 fps.
Knowledge-based Recurrent Attentive Neural Network for Small Object Detection
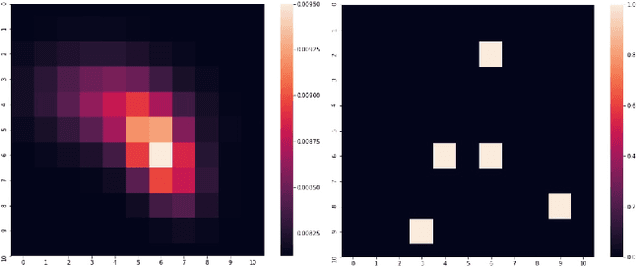
May 02, 2018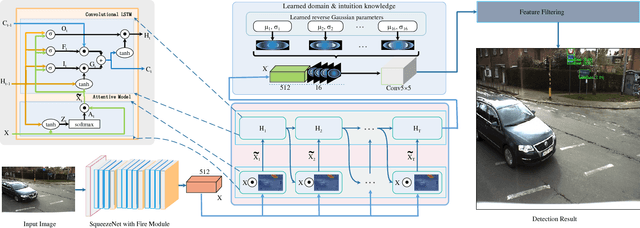


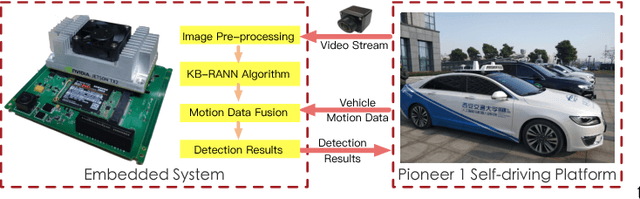
Accurate Traffic Sign Detection (TSD) can help intelligent systems make better decisions according to the traffic regulations. TSD, regarded as a typical small object detection problem in some way, is fundamental in Advanced Driver Assistance Systems (ADAS) and self-driving. However, although deep neural networks have achieved human even superhuman performance on several tasks, due to their own limitations, small object detection is still an open question. In this paper, we proposed a brain-inspired network, named as KB-RANN, to handle this problem. Attention mechanism is an essential function of our brain, we used a novel recurrent attentive neural network to improve the detection accuracy in a fine-grained manner. Further, we combined domain specific knowledge and intuitive knowledge to improve the efficiency. Experimental result shows that our methods achieved better performance than several popular methods widely used in object detection. More significantly, we transplanted our method on our designed embedded system and deployed on our self-driving car successfully.
Brain Inspired Cognitive Model with Attention for Self-Driving Cars
Feb 18, 2017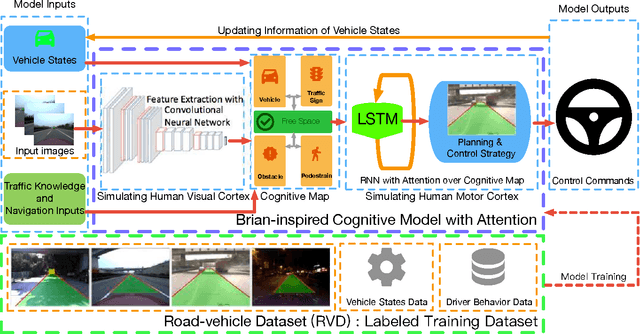
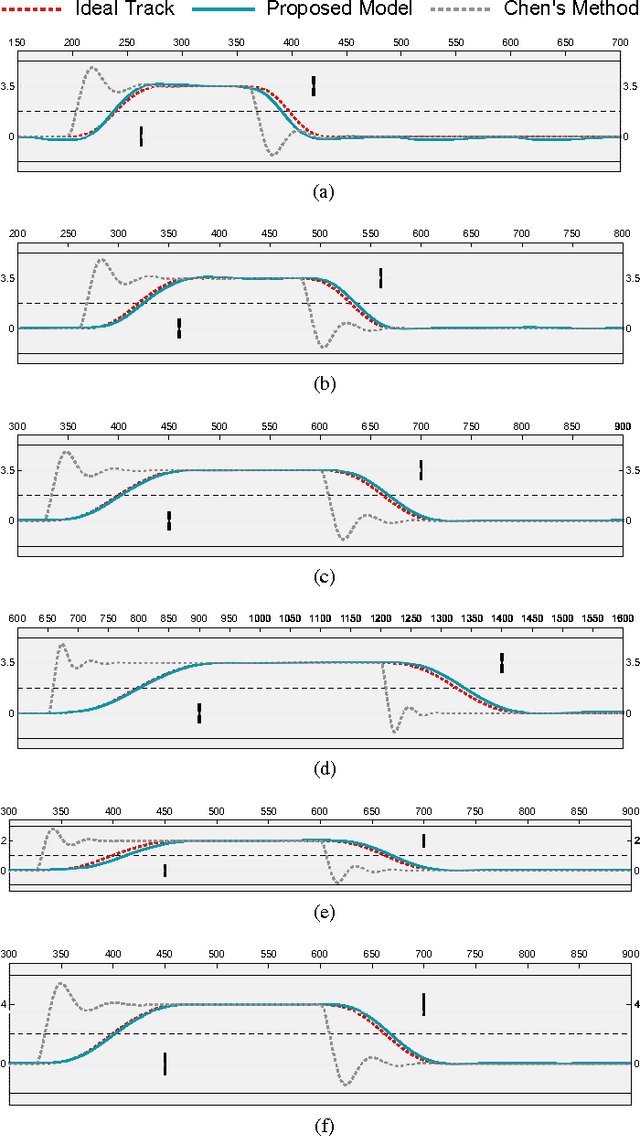
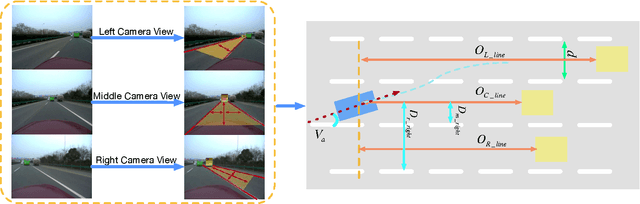

Perception-driven approach and end-to-end system are two major vision-based frameworks for self-driving cars. However, it is difficult to introduce attention and historical information of autonomous driving process, which are the essential factors for achieving human-like driving into these two methods. In this paper, we propose a novel model for self-driving cars named brain-inspired cognitive model with attention (CMA). This model consists of three parts: a convolutional neural network for simulating human visual cortex, a cognitive map built to describe relationships between objects in complex traffic scene and a recurrent neural network that combines with the real-time updated cognitive map to implement attention mechanism and long-short term memory. The benefit of our model is that can accurately solve three tasks simultaneously:1) detection of the free space and boundaries of the current and adjacent lanes. 2)estimation of obstacle distance and vehicle attitude, and 3) learning of driving behavior and decision making from human driver. More significantly, the proposed model could accept external navigating instructions during an end-to-end driving process. For evaluation, we build a large-scale road-vehicle dataset which contains more than forty thousand labeled road images captured by three cameras on our self-driving car. Moreover, human driving activities and vehicle states are recorded in the meanwhile.