 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Harnessing Precise and Diverse Semantics for Few-Shot Whole Slide Image Classification
Feb 24, 2026In computational pathology, few-shot whole slide image classification is primarily driven by the extreme scarcity of expert-labeled slides. Recent vision-language methods incorporate textual semantics generated by large language models, but treat these descriptions as static class-level priors that are shared across all samples and lack sample-wise refinement. This limits both the diversity and precision of visual-semantic alignment, hindering generalization under limited supervision. To overcome this, we propose the stochastic MUlti-view Semantic Enhancement (MUSE), a framework that first refines semantic precision via sample-wise adaptation and then enhances semantic richness through retrieval-augmented multi-view generation. Specifically, MUSE introduces Sample-wise Fine-grained Semantic Enhancement (SFSE), which yields a fine-grained semantic prior for each sample through MoE-based adaptive visual-semantic interaction. Guided by this prior, Stochastic Multi-view Model Optimization (SMMO) constructs an LLM-generated knowledge base of diverse pathological descriptions per class, then retrieves and stochastically integrates multiple matched textual views during training. These dynamically selected texts serve as enriched semantic supervisions to stochastically optimize the vision-language model, promoting robustness and mitigating overfitting. Experiments on three benchmark WSI datasets show that MUSE consistently outperforms existing vision-language baselines in few-shot settings, demonstrating that effective few-shot pathology learning requires not only richer semantic sources but also their active and sample-aware semantic optimization. Our code is available at: https://github.com/JiahaoXu-god/CVPR2026_MUSE.
AbductiveMLLM: Boosting Visual Abductive Reasoning Within MLLMs
Jan 06, 2026Visual abductive reasoning (VAR) is a challenging task that requires AI systems to infer the most likely explanation for incomplete visual observations. While recent MLLMs develop strong general-purpose multimodal reasoning capabilities, they fall short in abductive inference, as compared to human beings. To bridge this gap, we draw inspiration from the interplay between verbal and pictorial abduction in human cognition, and propose to strengthen abduction of MLLMs by mimicking such dual-mode behavior. Concretely, we introduce AbductiveMLLM comprising of two synergistic components: REASONER and IMAGINER. The REASONER operates in the verbal domain. It first explores a broad space of possible explanations using a blind LLM and then prunes visually incongruent hypotheses based on cross-modal causal alignment. The remaining hypotheses are introduced into the MLLM as targeted priors, steering its reasoning toward causally coherent explanations. The IMAGINER, on the other hand, further guides MLLMs by emulating human-like pictorial thinking. It conditions a text-to-image diffusion model on both the input video and the REASONER's output embeddings to "imagine" plausible visual scenes that correspond to verbal explanation, thereby enriching MLLMs' contextual grounding. The two components are trained jointly in an end-to-end manner. Experiments on standard VAR benchmarks show that AbductiveMLLM achieves state-of-the-art performance, consistently outperforming traditional solutions and advanced MLLMs.
MI-DETR: An Object Detection Model with Multi-time Inquiries Mechanism
Mar 03, 2025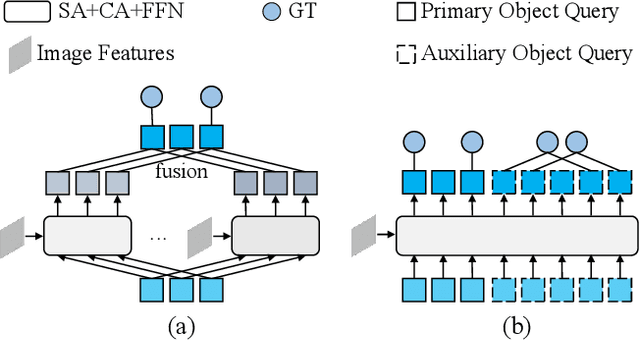
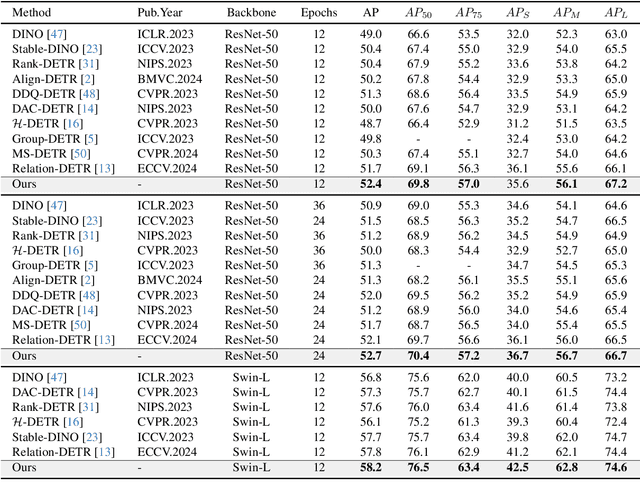
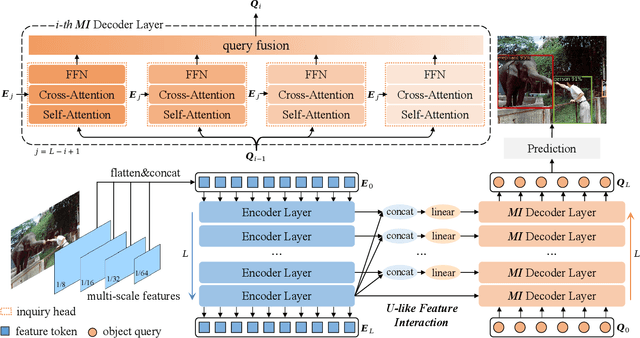
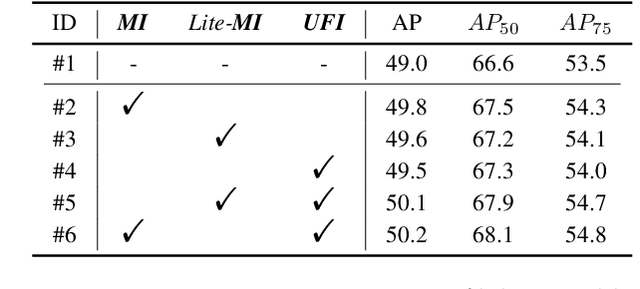
Based on analyzing the character of cascaded decoder architecture commonly adopted in existing DETR-like models, this paper proposes a new decoder architecture. The cascaded decoder architecture constrains object queries to update in the cascaded direction, only enabling object queries to learn relatively-limited information from image features. However, the challenges for object detection in natural scenes (e.g., extremely-small, heavily-occluded, and confusingly mixed with the background) require an object detection model to fully utilize image features, which motivates us to propose a new decoder architecture with the parallel Multi-time Inquiries (MI) mechanism. MI enables object queries to learn more comprehensive information, and our MI based model, MI-DETR, outperforms all existing DETR-like models on COCO benchmark under different backbones and training epochs, achieving +2.3 AP and +0.6 AP improvements compared to the most representative model DINO and SOTA model Relation-DETR under ResNet-50 backbone. In addition, a series of diagnostic and visualization experiments demonstrate the effectiveness, rationality, and interpretability of MI.
On-Road Object Importance Estimation: A New Dataset and A Model with Multi-Fold Top-Down Guidance
Nov 26, 2024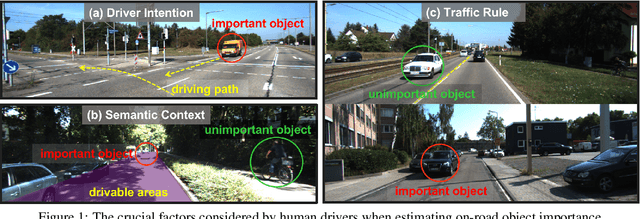

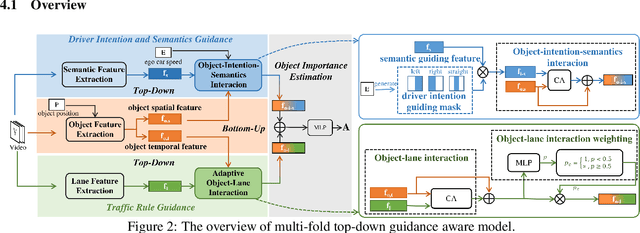
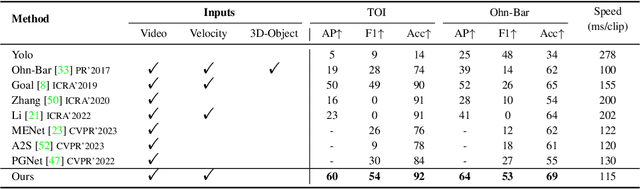
This paper addresses the problem of on-road object importance estimation, which utilizes video sequences captured from the driver's perspective as the input. Although this problem is significant for safer and smarter driving systems, the exploration of this problem remains limited. On one hand, publicly-available large-scale datasets are scarce in the community. To address this dilemma, this paper contributes a new large-scale dataset named Traffic Object Importance (TOI). On the other hand, existing methods often only consider either bottom-up feature or single-fold guidance, leading to limitations in handling highly dynamic and diverse traffic scenarios. Different from existing methods, this paper proposes a model that integrates multi-fold top-down guidance with the bottom-up feature. Specifically, three kinds of top-down guidance factors (ie, driver intention, semantic context, and traffic rule) are integrated into our model. These factors are important for object importance estimation, but none of the existing methods simultaneously consider them. To our knowledge, this paper proposes the first on-road object importance estimation model that fuses multi-fold top-down guidance factors with bottom-up feature. Extensive experiments demonstrate that our model outperforms state-of-the-art methods by large margins, achieving 23.1% Average Precision (AP) improvement compared with the recently proposed model (ie, Goal).
DI-MaskDINO: A Joint Object Detection and Instance Segmentation Model
Oct 22, 2024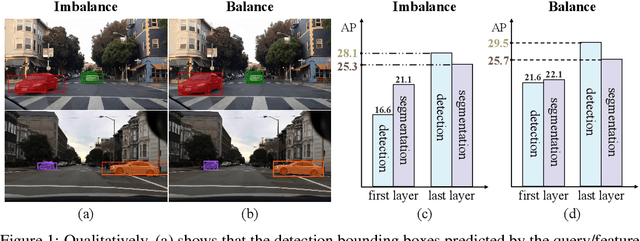
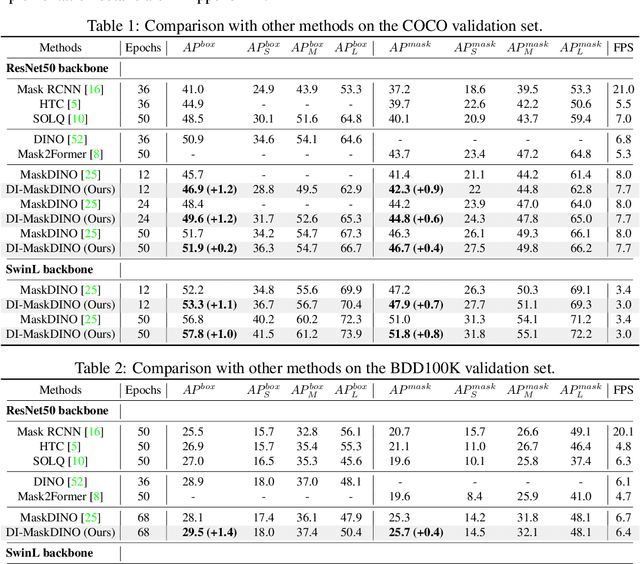
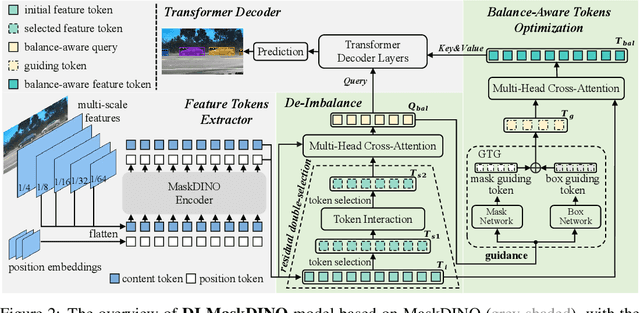
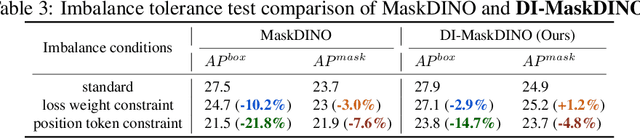
This paper is motivated by an interesting phenomenon: the performance of object detection lags behind that of instance segmentation (i.e., performance imbalance) when investigating the intermediate results from the beginning transformer decoder layer of MaskDINO (i.e., the SOTA model for joint detection and segmentation). This phenomenon inspires us to think about a question: will the performance imbalance at the beginning layer of transformer decoder constrain the upper bound of the final performance? With this question in mind, we further conduct qualitative and quantitative pre-experiments, which validate the negative impact of detection-segmentation imbalance issue on the model performance. To address this issue, this paper proposes DI-MaskDINO model, the core idea of which is to improve the final performance by alleviating the detection-segmentation imbalance. DI-MaskDINO is implemented by configuring our proposed De-Imbalance (DI) module and Balance-Aware Tokens Optimization (BATO) module to MaskDINO. DI is responsible for generating balance-aware query, and BATO uses the balance-aware query to guide the optimization of the initial feature tokens. The balance-aware query and optimized feature tokens are respectively taken as the Query and Key&Value of transformer decoder to perform joint object detection and instance segmentation. DI-MaskDINO outperforms existing joint object detection and instance segmentation models on COCO and BDD100K benchmarks, achieving +1.2 $AP^{box}$ and +0.9 $AP^{mask}$ improvements compared to SOTA joint detection and segmentation model MaskDINO. In addition, DI-MaskDINO also obtains +1.0 $AP^{box}$ improvement compared to SOTA object detection model DINO and +3.0 $AP^{mask}$ improvement compared to SOTA segmentation model Mask2Former.
Multi-Type Map Construction via Semantics-Aware Autonomous Exploration in Unknown Indoor Environments
Apr 07, 2024This paper proposes a novel semantics-aware autonomous exploration model to handle the long-standing issue: the mainstream RRT (Rapid-exploration Random Tree) based exploration models usually make the mobile robot switch frequently between different regions, leading to the excessively-repeated explorations for the same region. Our proposed semantics-aware model encourages a mobile robot to fully explore the current region before moving to the next region, which is able to avoid excessively-repeated explorations and make the exploration faster. The core idea of semantics-aware autonomous exploration model is optimizing the sampling point selection mechanism and frontier point evaluation function by considering the semantic information of regions. In addition, compared with existing autonomous exploration methods that usually construct the single-type or 2-3 types of maps, our model allows to construct four kinds of maps including point cloud map, occupancy grid map, topological map, and semantic map. To test the performance of our model, we conducted experiments in three simulated environments. The experiment results demonstrate that compared to Improved RRT, our model achieved 33.0% exploration time reduction and 39.3% exploration trajectory length reduction when maintaining >98% exploration rate.
Intention Action Anticipation Model with Guide-Feedback Loop Mechanism
Mar 19, 2024Anticipating human intention from videos has broad applications, such as automatic driving, robot assistive technology, and virtual reality. This study addresses the problem of intention action anticipation using egocentric video sequences to estimate actions that indicate human intention. We propose a Hierarchical Complete-Recent (HCR) information fusion model that makes full use of the features of the entire video sequence (i.e., complete features) and the features of the video tail sequence (i.e., recent features). The HCR model has two primary mechanisms. The Guide-Feedback Loop (GFL) mechanism is proposed to model the relation between one recent feature and one complete feature. Based on GFL, the MultiComplete-Recent Feature Aggregation (MCRFA) module is proposed to model the relation of one recent feature with multiscale complete features. Based on GFL and MCRFA, the HCR model can hierarchically explore the rich interrelationships between multiscale complete features and multiscale recent features. Through comparative and ablation experiments, we validate the effectiveness of our model on two well-known public datasets: EPIC-Kitchens and EGTEA Gaze+.
A Fast and Map-Free Model for Trajectory Prediction in Traffics
Jul 19, 2023To handle the two shortcomings of existing methods, (i)nearly all models rely on high-definition (HD) maps, yet the map information is not always available in real traffic scenes and HD map-building is expensive and time-consuming and (ii) existing models usually focus on improving prediction accuracy at the expense of reducing computing efficiency, yet the efficiency is crucial for various real applications, this paper proposes an efficient trajectory prediction model that is not dependent on traffic maps. The core idea of our model is encoding single-agent's spatial-temporal information in the first stage and exploring multi-agents' spatial-temporal interactions in the second stage. By comprehensively utilizing attention mechanism, LSTM, graph convolution network and temporal transformer in the two stages, our model is able to learn rich dynamic and interaction information of all agents. Our model achieves the highest performance when comparing with existing map-free methods and also exceeds most map-based state-of-the-art methods on the Argoverse dataset. In addition, our model also exhibits a faster inference speed than the baseline methods.
Inspired by Norbert Wiener: FeedBack Loop Network Learning Incremental Knowledge for Driver Attention Prediction and Beyond
Dec 05, 2022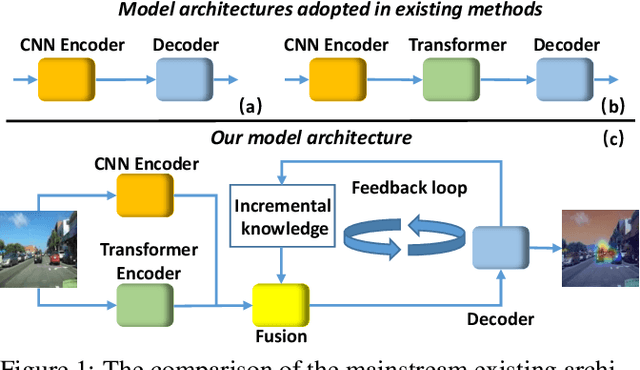
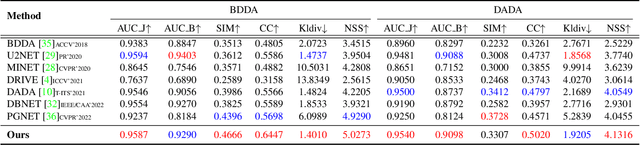
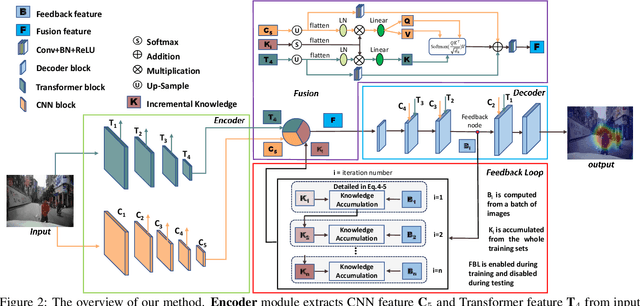
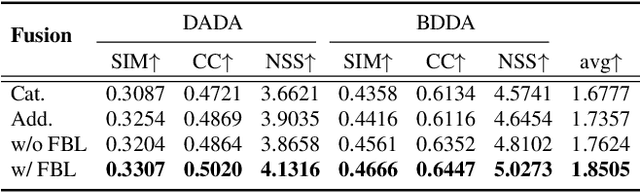
The problem of predicting driver attention from the driving perspective is gaining the increasing research focuses due to its remarkable significance for autonomous driving and assisted driving systems. Driving experience is extremely important for driver attention prediction, a skilled driver is able to effortlessly predict oncoming danger (before it becomes salient) based on driving experience and quickly pay attention on the corresponding zones. However, the nonobjective driving experience is difficult to model, so a mechanism simulating driver experience accumulation procedure is absent in existing methods, and the existing methods usually follow the technique line of saliency prediction methods to predict driver attention. In this paper, we propose a FeedBack Loop Network (FBLNet), which attempts to model the driving experience accumulation procedure. By over-and-over iterations, FBLNet generates the incremental knowledge that carries rich historically-accumulative long-term temporal information. The incremental knowledge to our model is like the driving experience to humans. Under the guidance of the incremental knowledge, our model fuses the CNN feature and Transformer feature that are extracted from the input image to predict driver attention. Our model exhibits solid advantage over existing methods, achieving an average 10.3% performance improvement on three public datasets.
X-GGM: Graph Generative Modeling for Out-of-Distribution Generalization in Visual Question Answering
Jul 24, 2021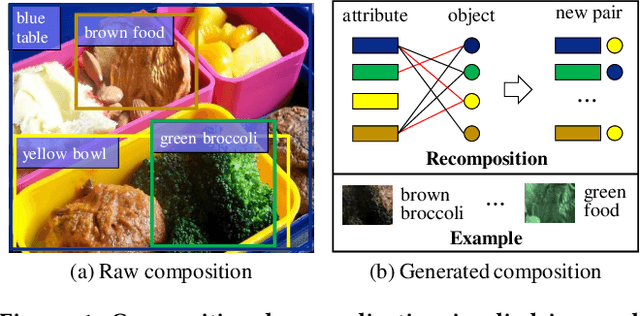

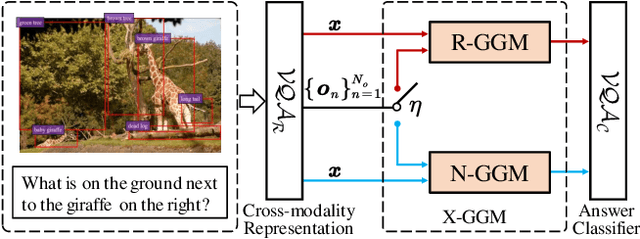
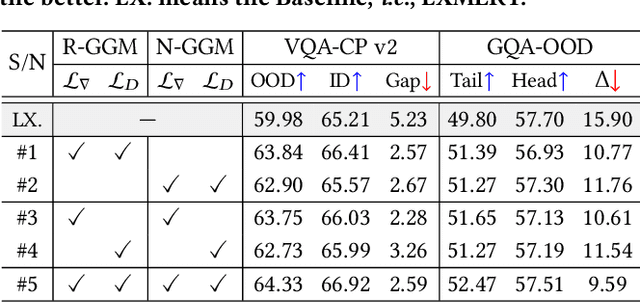
Encouraging progress has been made towards Visual Question Answering (VQA) in recent years, but it is still challenging to enable VQA models to adaptively generalize to out-of-distribution (OOD) samples. Intuitively, recompositions of existing visual concepts (i.e., attributes and objects) can generate unseen compositions in the training set, which will promote VQA models to generalize to OOD samples. In this paper, we formulate OOD generalization in VQA as a compositional generalization problem and propose a graph generative modeling-based training scheme (X-GGM) to handle the problem implicitly. X-GGM leverages graph generative modeling to iteratively generate a relation matrix and node representations for the predefined graph that utilizes attribute-object pairs as nodes. Furthermore, to alleviate the unstable training issue in graph generative modeling, we propose a gradient distribution consistency loss to constrain the data distribution with adversarial perturbations and the generated distribution. The baseline VQA model (LXMERT) trained with the X-GGM scheme achieves state-of-the-art OOD performance on two standard VQA OOD benchmarks, i.e., VQA-CP v2 and GQA-OOD. Extensive ablation studies demonstrate the effectiveness of X-GGM components.