 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMI-DETR: An Object Detection Model with Multi-time Inquiries Mechanism
Mar 03, 2025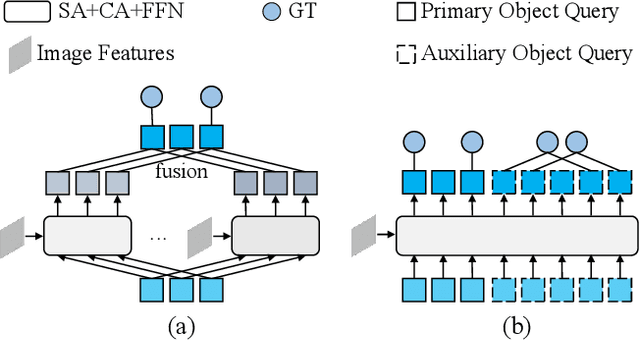
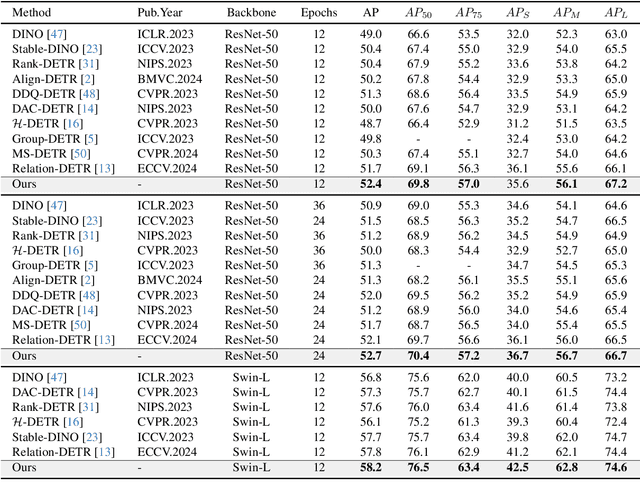
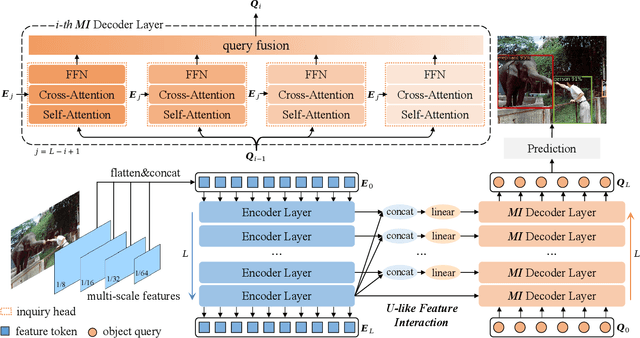
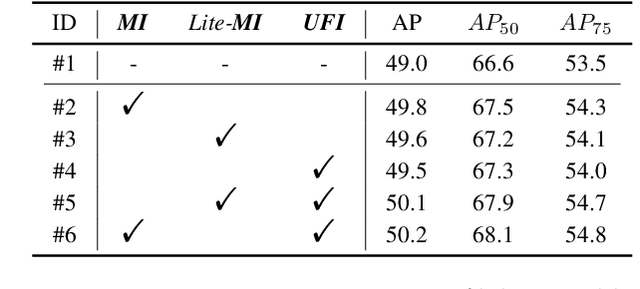
Based on analyzing the character of cascaded decoder architecture commonly adopted in existing DETR-like models, this paper proposes a new decoder architecture. The cascaded decoder architecture constrains object queries to update in the cascaded direction, only enabling object queries to learn relatively-limited information from image features. However, the challenges for object detection in natural scenes (e.g., extremely-small, heavily-occluded, and confusingly mixed with the background) require an object detection model to fully utilize image features, which motivates us to propose a new decoder architecture with the parallel Multi-time Inquiries (MI) mechanism. MI enables object queries to learn more comprehensive information, and our MI based model, MI-DETR, outperforms all existing DETR-like models on COCO benchmark under different backbones and training epochs, achieving +2.3 AP and +0.6 AP improvements compared to the most representative model DINO and SOTA model Relation-DETR under ResNet-50 backbone. In addition, a series of diagnostic and visualization experiments demonstrate the effectiveness, rationality, and interpretability of MI.
DI-MaskDINO: A Joint Object Detection and Instance Segmentation Model
Oct 22, 2024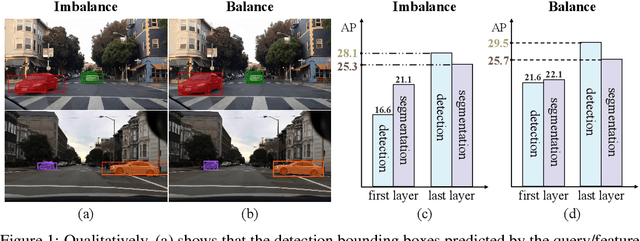
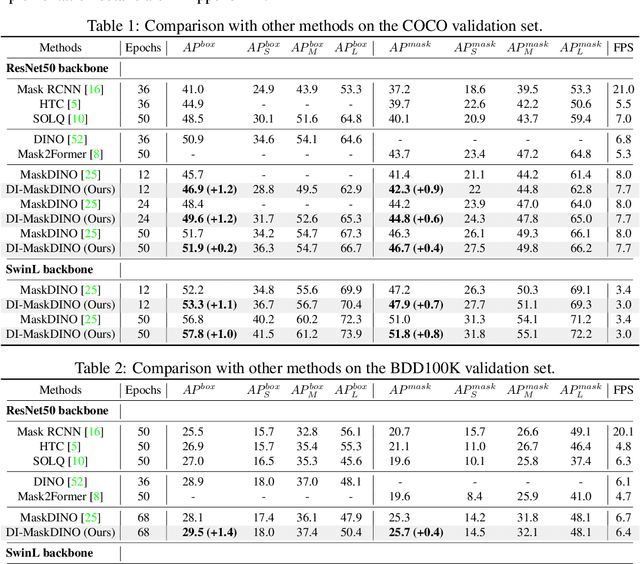
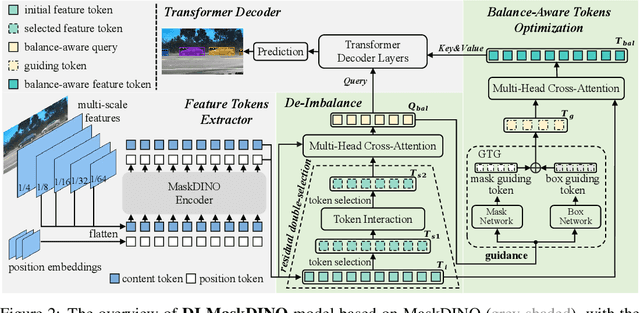
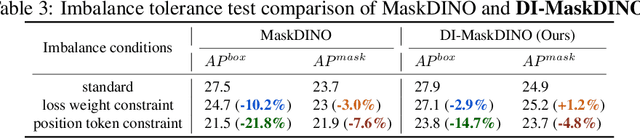
This paper is motivated by an interesting phenomenon: the performance of object detection lags behind that of instance segmentation (i.e., performance imbalance) when investigating the intermediate results from the beginning transformer decoder layer of MaskDINO (i.e., the SOTA model for joint detection and segmentation). This phenomenon inspires us to think about a question: will the performance imbalance at the beginning layer of transformer decoder constrain the upper bound of the final performance? With this question in mind, we further conduct qualitative and quantitative pre-experiments, which validate the negative impact of detection-segmentation imbalance issue on the model performance. To address this issue, this paper proposes DI-MaskDINO model, the core idea of which is to improve the final performance by alleviating the detection-segmentation imbalance. DI-MaskDINO is implemented by configuring our proposed De-Imbalance (DI) module and Balance-Aware Tokens Optimization (BATO) module to MaskDINO. DI is responsible for generating balance-aware query, and BATO uses the balance-aware query to guide the optimization of the initial feature tokens. The balance-aware query and optimized feature tokens are respectively taken as the Query and Key&Value of transformer decoder to perform joint object detection and instance segmentation. DI-MaskDINO outperforms existing joint object detection and instance segmentation models on COCO and BDD100K benchmarks, achieving +1.2 $AP^{box}$ and +0.9 $AP^{mask}$ improvements compared to SOTA joint detection and segmentation model MaskDINO. In addition, DI-MaskDINO also obtains +1.0 $AP^{box}$ improvement compared to SOTA object detection model DINO and +3.0 $AP^{mask}$ improvement compared to SOTA segmentation model Mask2Former.
BAGUA: Scaling up Distributed Learning with System Relaxations
Jul 12, 2021
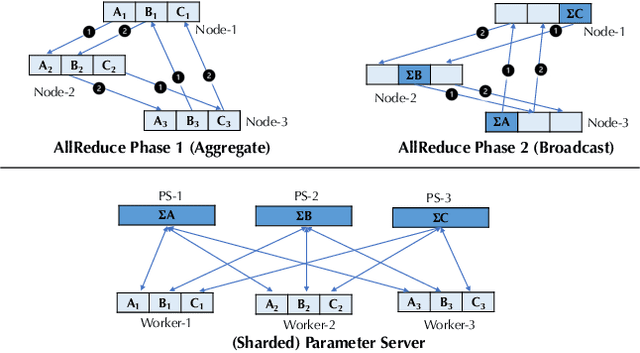
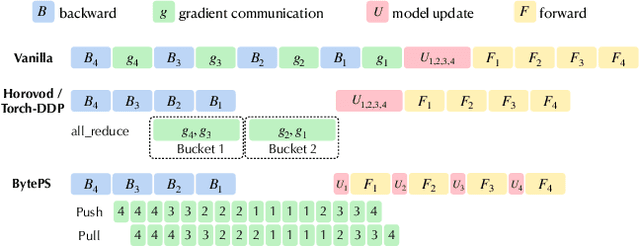

Recent years have witnessed a growing list of systems for distributed data-parallel training. Existing systems largely fit into two paradigms, i.e., parameter server and MPI-style collective operations. On the algorithmic side, researchers have proposed a wide range of techniques to lower the communication via system relaxations: quantization, decentralization, and communication delay. However, most, if not all, existing systems only rely on standard synchronous and asynchronous stochastic gradient (SG) based optimization, therefore, cannot take advantage of all possible optimizations that the machine learning community has been developing recently. Given this emerging gap between the current landscapes of systems and theory, we build BAGUA, a communication framework whose design goal is to provide a system abstraction that is both flexible and modular to support state-of-the-art system relaxation techniques of distributed training. Powered by the new system design, BAGUA has a great ability to implement and extend various state-of-the-art distributed learning algorithms. In a production cluster with up to 16 machines (128 GPUs), BAGUA can outperform PyTorch-DDP, Horovod and BytePS in the end-to-end training time by a significant margin (up to 1.95 times) across a diverse range of tasks. Moreover, we conduct a rigorous tradeoff exploration showing that different algorithms and system relaxations achieve the best performance over different network conditions.