 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaparoscopic Image Desmoking Using the U-Net with New Loss Function and Integrated Differentiable Wiener Filter
May 27, 2025Laparoscopic surgeries often suffer from reduced visual clarity due to the presence of surgical smoke originated by surgical instruments, which poses significant challenges for both surgeons and vision based computer-assisted technologies. In order to remove the surgical smoke, a novel U-Net deep learning with new loss function and integrated differentiable Wiener filter (ULW) method is presented. Specifically, the new loss function integrates the pixel, structural, and perceptual properties. Thus, the new loss function, which combines the structural similarity index measure loss, the perceptual loss, as well as the mean squared error loss, is able to enhance the quality and realism of the reconstructed images. Furthermore, the learnable Wiener filter is capable of effectively modelling the degradation process caused by the surgical smoke. The effectiveness of the proposed ULW method is evaluated using the publicly available paired laparoscopic smoke and smoke-free image dataset, which provides reliable benchmarking and quantitative comparisons. Experimental results show that the proposed ULW method excels in both visual clarity and metric-based evaluation. As a result, the proposed ULW method offers a promising solution for real-time enhancement of laparoscopic imagery. The code is available at https://github.com/chengyuyang-njit/ImageDesmoke.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Interpretable Automatic Rosacea Detection with Whitened Cosine Similarity
Apr 10, 2025
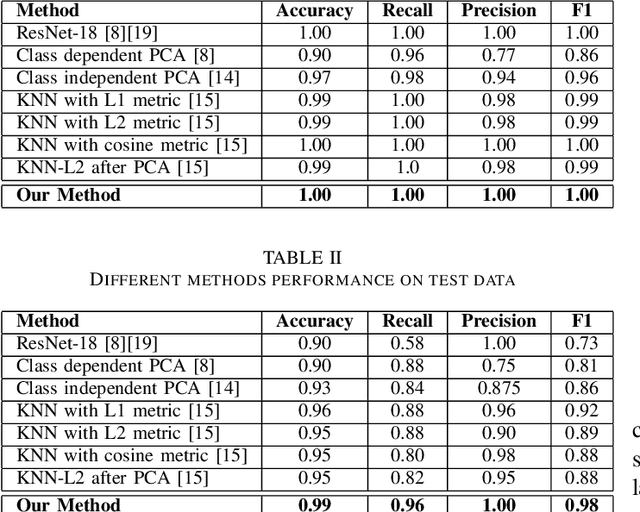
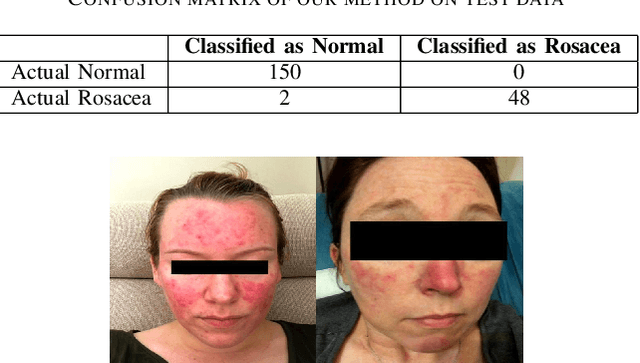
According to the National Rosacea Society, approximately sixteen million Americans suffer from rosacea, a common skin condition that causes flushing or long-term redness on a person's face. To increase rosacea awareness and to better assist physicians to make diagnosis on this disease, we propose an interpretable automatic rosacea detection method based on whitened cosine similarity in this paper. The contributions of the proposed methods are three-fold. First, the proposed method can automatically distinguish patients suffering from rosacea from people who are clean of this disease with a significantly higher accuracy than other methods in unseen test data, including both classical deep learning and statistical methods. Second, the proposed method addresses the interpretability issue by measuring the similarity between the test sample and the means of two classes, namely the rosacea class versus the normal class, which allows both medical professionals and patients to understand and trust the results. And finally, the proposed methods will not only help increase awareness of rosacea in the general population, but will also help remind patients who suffer from this disease of possible early treatment, as rosacea is more treatable in its early stages. The code and data are available at https://github.com/chengyuyang-njit/ICCRD-2025. The code and data are available at https://github.com/chengyuyang-njit/ICCRD-2025.
Increasing Rosacea Awareness Among Population Using Deep Learning and Statistical Approaches
Nov 11, 2024Approximately 16 million Americans suffer from rosacea according to the National Rosacea Society. To increase rosacea awareness, automatic rosacea detection methods using deep learning and explainable statistical approaches are presented in this paper. The deep learning method applies the ResNet-18 for rosacea detection, and the statistical approaches utilize the means of the two classes, namely, the rosacea class vs. the normal class, and the principal component analysis to extract features from the facial images for automatic rosacea detection. The contributions of the proposed methods are three-fold. First, the proposed methods are able to automatically distinguish patients who are suffering from rosacea from people who are clean of this disease. Second, the statistical approaches address the explainability issue that allows doctors and patients to understand and trust the results. And finally, the proposed methods will not only help increase rosacea awareness in the general population but also help remind the patients who suffer from this disease of possible early treatment since rosacea is more treatable at its early stages. The code and data are available at https://github.com/cyang322/rosacea_detection.git.
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
May 23, 2024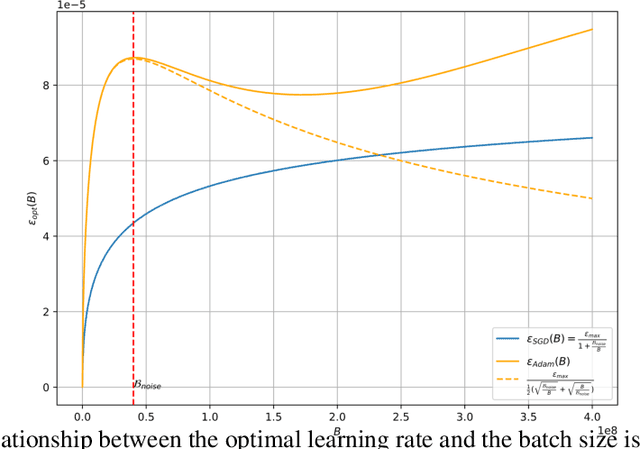
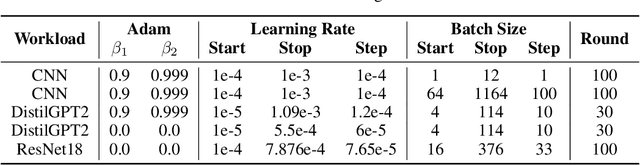
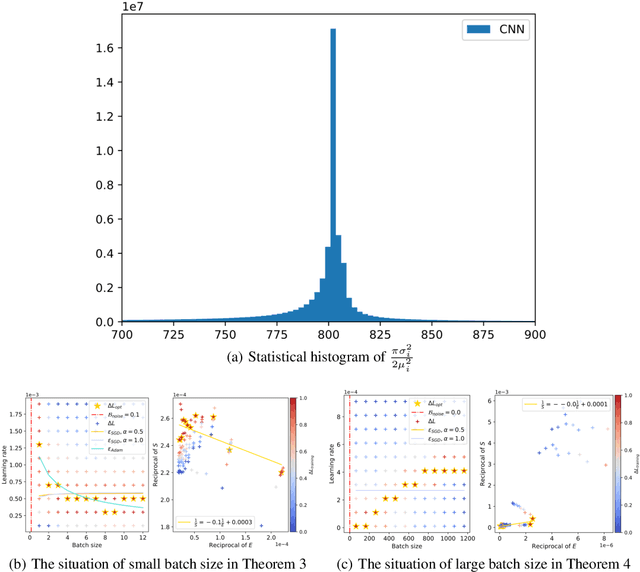
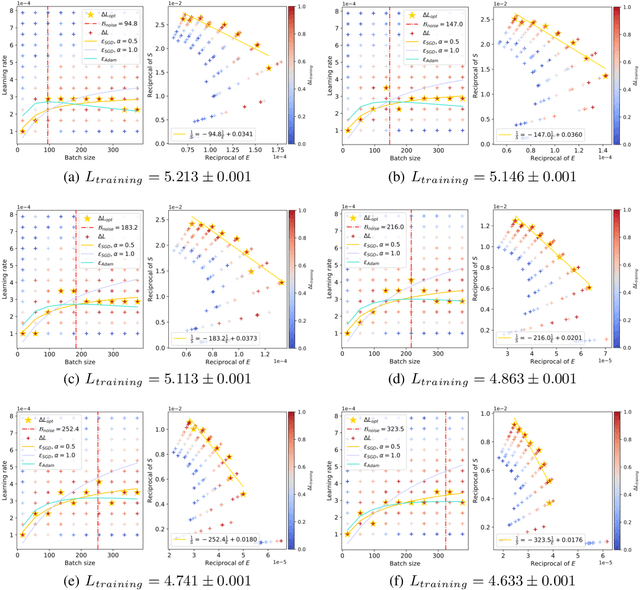
In current deep learning tasks, Adam style optimizers such as Adam, Adagrad, RMSProp, Adafactor, and Lion have been widely used as alternatives to SGD style optimizers. These optimizers typically update model parameters using the sign of gradients, resulting in more stable convergence curves. The learning rate and the batch size are the most critical hyperparameters for optimizers, which require careful tuning to enable effective convergence. Previous research has shown that the optimal learning rate increases linearly or follows similar rules with batch size for SGD style optimizers. However, this conclusion is not applicable to Adam style optimizers. In this paper, we elucidate the connection between optimal learning rates and batch sizes for Adam style optimizers through both theoretical analysis and extensive experiments. First, we raise the scaling law between batch sizes and optimal learning rates in the sign of gradient case, in which we prove that the optimal learning rate first rises and then falls as the batch size increases. Moreover, the peak value of the surge will gradually move toward the larger batch size as training progresses. Second, we conducted experiments on various CV and NLP tasks and verified the correctness of the scaling law.
Ammunition Component Classification Using Deep Learning
Aug 26, 2022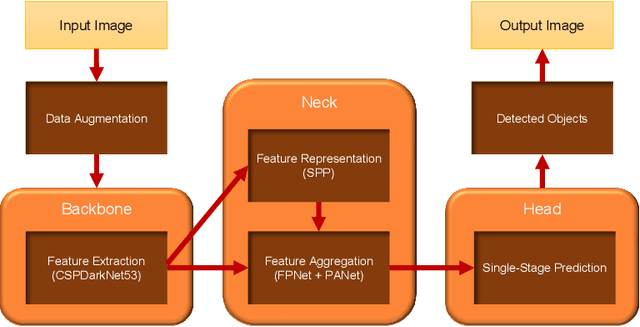

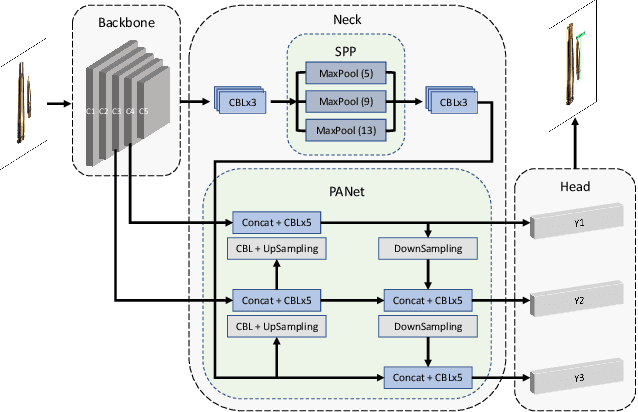
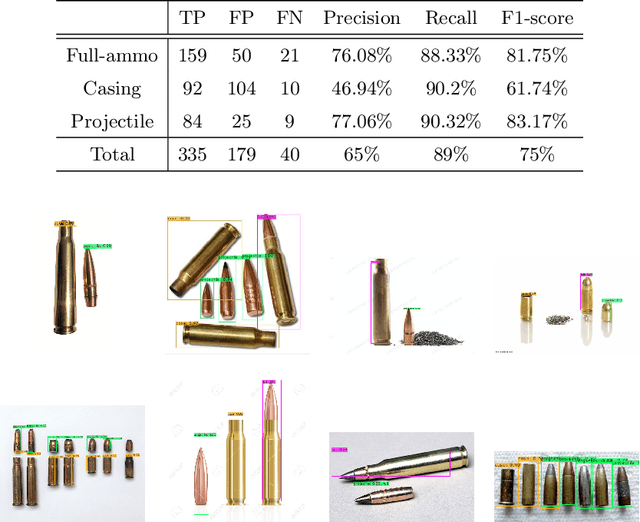
Ammunition scrap inspection is an essential step in the process of recycling ammunition metal scrap. Most ammunition is composed of a number of components, including case, primer, powder, and projectile. Ammo scrap containing energetics is considered to be potentially dangerous and should be separated before the recycling process. Manually inspecting each piece of scrap is tedious and time-consuming. We have gathered a dataset of ammunition components with the goal of applying artificial intelligence for classifying safe and unsafe scrap pieces automatically. First, two training datasets are manually created from visual and x-ray images of ammo. Second, the x-ray dataset is augmented using the spatial transforms of histogram equalization, averaging, sharpening, power law, and Gaussian blurring in order to compensate for the lack of sufficient training data. Lastly, the representative YOLOv4 object detection method is applied to detect the ammo components and classify the scrap pieces into safe and unsafe classes, respectively. The trained models are tested against unseen data in order to evaluate the performance of the applied method. The experiments demonstrate the feasibility of ammo component detection and classification using deep learning. The datasets and the pre-trained models are available at https://github.com/hadi-ghnd/Scrap-Classification.
* Conference: International Conference on Machine Learning and Data Mining MLDM 2022 link: http://www.ibai-publishing.org/html/proceedings_2022/pdf/proceedings_mldm_2022.pdf ISBN: 978-3-942952-93-4
Real-Time Accident Detection in Traffic Surveillance Using Deep Learning
Aug 12, 2022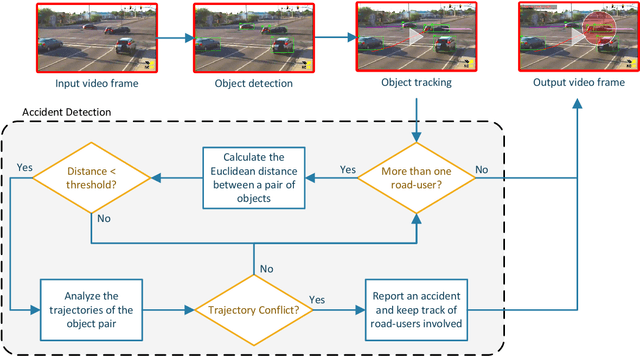
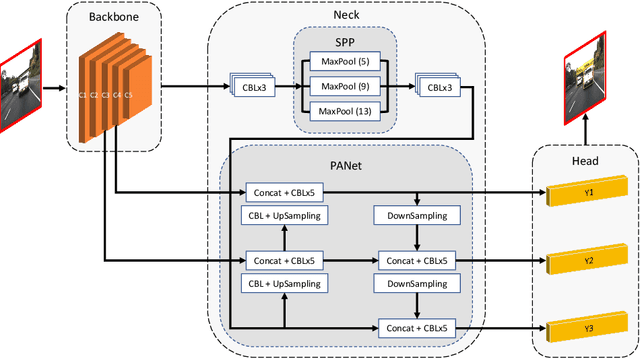

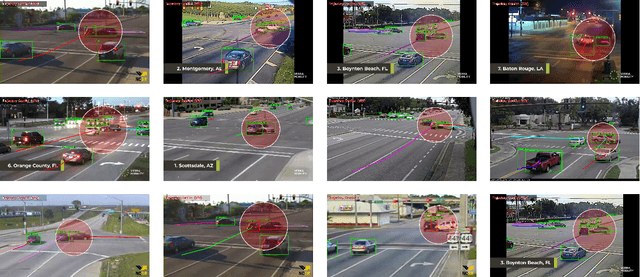
Automatic detection of traffic accidents is an important emerging topic in traffic monitoring systems. Nowadays many urban intersections are equipped with surveillance cameras connected to traffic management systems. Therefore, computer vision techniques can be viable tools for automatic accident detection. This paper presents a new efficient framework for accident detection at intersections for traffic surveillance applications. The proposed framework consists of three hierarchical steps, including efficient and accurate object detection based on the state-of-the-art YOLOv4 method, object tracking based on Kalman filter coupled with the Hungarian algorithm for association, and accident detection by trajectory conflict analysis. A new cost function is applied for object association to accommodate for occlusion, overlapping objects, and shape changes in the object tracking step. The object trajectories are analyzed in terms of velocity, angle, and distance in order to detect different types of trajectory conflicts including vehicle-to-vehicle, vehicle-to-pedestrian, and vehicle-to-bicycle. Experimental results using real traffic video data show the feasibility of the proposed method in real-time applications of traffic surveillance. In particular, trajectory conflicts, including near-accidents and accidents occurring at urban intersections are detected with a low false alarm rate and a high detection rate. The robustness of the proposed framework is evaluated using video sequences collected from YouTube with diverse illumination conditions. The dataset is publicly available at: http://github.com/hadi-ghnd/AccidentDetection.
* link to IEEE: https://ieeexplore.ieee.org/abstract/document/9827736
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021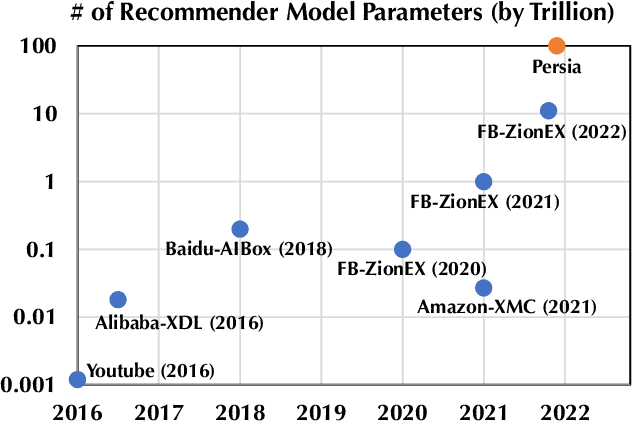
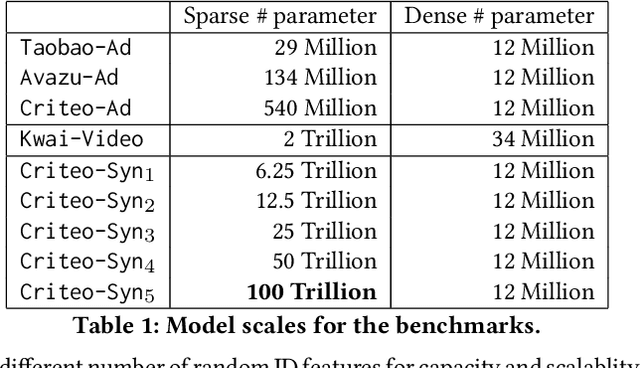
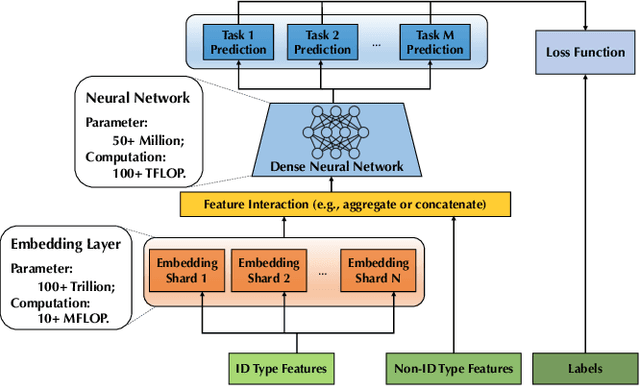
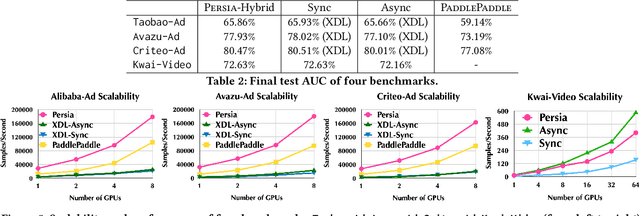
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
Smart Traffic Monitoring System using Computer Vision and Edge Computing
Sep 07, 2021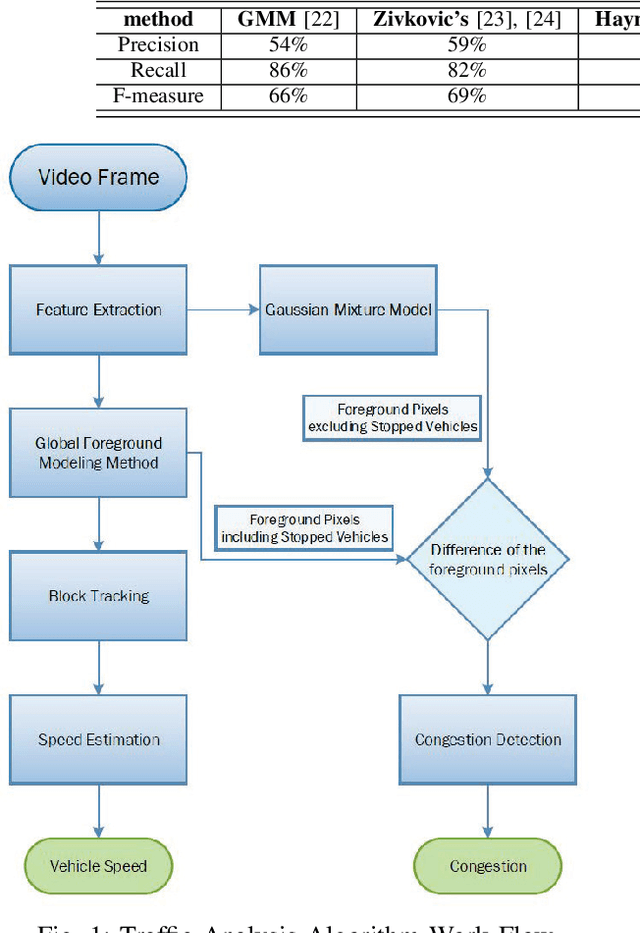


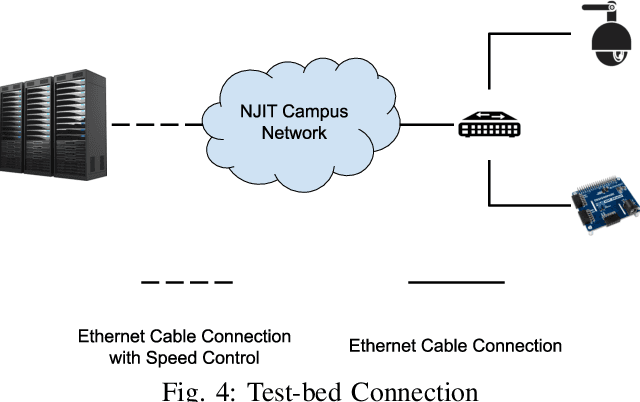
Traffic management systems capture tremendous video data and leverage advances in video processing to detect and monitor traffic incidents. The collected data are traditionally forwarded to the traffic management center (TMC) for in-depth analysis and may thus exacerbate the network paths to the TMC. To alleviate such bottlenecks, we propose to utilize edge computing by equipping edge nodes that are close to cameras with computing resources (e.g. cloudlets). A cloudlet, with limited computing resources as compared to TMC, provides limited video processing capabilities. In this paper, we focus on two common traffic monitoring tasks, congestion detection, and speed detection, and propose a two-tier edge computing based model that takes into account of both the limited computing capability in cloudlets and the unstable network condition to the TMC. Our solution utilizes two algorithms for each task, one implemented at the edge and the other one at the TMC, which are designed with the consideration of different computing resources. While the TMC provides strong computation power, the video quality it receives depends on the underlying network conditions. On the other hand, the edge processes very high-quality video but with limited computing resources. Our model captures this trade-off. We evaluate the performance of the proposed two-tier model as well as the traffic monitoring algorithms via test-bed experiments under different weather as well as network conditions and show that our proposed hybrid edge-cloud solution outperforms both the cloud-only and edge-only solutions.
BAGUA: Scaling up Distributed Learning with System Relaxations
Jul 12, 2021
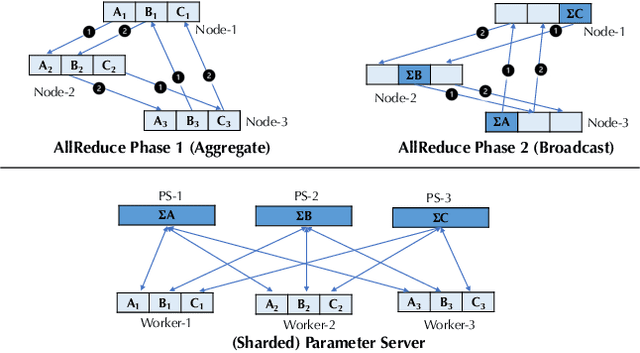
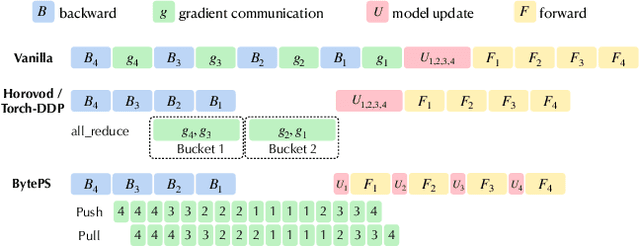

Recent years have witnessed a growing list of systems for distributed data-parallel training. Existing systems largely fit into two paradigms, i.e., parameter server and MPI-style collective operations. On the algorithmic side, researchers have proposed a wide range of techniques to lower the communication via system relaxations: quantization, decentralization, and communication delay. However, most, if not all, existing systems only rely on standard synchronous and asynchronous stochastic gradient (SG) based optimization, therefore, cannot take advantage of all possible optimizations that the machine learning community has been developing recently. Given this emerging gap between the current landscapes of systems and theory, we build BAGUA, a communication framework whose design goal is to provide a system abstraction that is both flexible and modular to support state-of-the-art system relaxation techniques of distributed training. Powered by the new system design, BAGUA has a great ability to implement and extend various state-of-the-art distributed learning algorithms. In a production cluster with up to 16 machines (128 GPUs), BAGUA can outperform PyTorch-DDP, Horovod and BytePS in the end-to-end training time by a significant margin (up to 1.95 times) across a diverse range of tasks. Moreover, we conduct a rigorous tradeoff exploration showing that different algorithms and system relaxations achieve the best performance over different network conditions.