 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Client-level Assessment of Collaborative Backdoor Poisoning in Non-IID Federated Learning
Apr 21, 2025Federated learning (FL) enables collaborative model training using decentralized private data from multiple clients. While FL has shown robustness against poisoning attacks with basic defenses, our research reveals new vulnerabilities stemming from non-independent and identically distributed (non-IID) data among clients. These vulnerabilities pose a substantial risk of model poisoning in real-world FL scenarios. To demonstrate such vulnerabilities, we develop a novel collaborative backdoor poisoning attack called CollaPois. In this attack, we distribute a single pre-trained model infected with a Trojan to a group of compromised clients. These clients then work together to produce malicious gradients, causing the FL model to consistently converge towards a low-loss region centered around the Trojan-infected model. Consequently, the impact of the Trojan is amplified, especially when the benign clients have diverse local data distributions and scattered local gradients. CollaPois stands out by achieving its goals while involving only a limited number of compromised clients, setting it apart from existing attacks. Also, CollaPois effectively avoids noticeable shifts or degradation in the FL model's performance on legitimate data samples, allowing it to operate stealthily and evade detection by advanced robust FL algorithms. Thorough theoretical analysis and experiments conducted on various benchmark datasets demonstrate the superiority of CollaPois compared to state-of-the-art backdoor attacks. Notably, CollaPois bypasses existing backdoor defenses, especially in scenarios where clients possess diverse data distributions. Moreover, the results show that CollaPois remains effective even when involving a small number of compromised clients. Notably, clients whose local data is closely aligned with compromised clients experience higher risks of backdoor infections.
An Adaptive Black-box Defense against Trojan Attacks
Sep 05, 2022
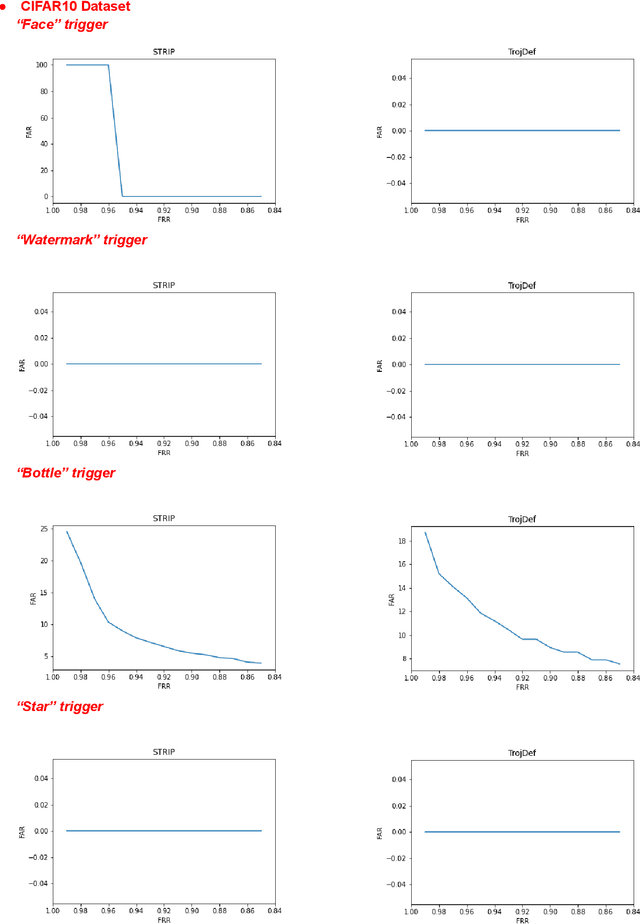
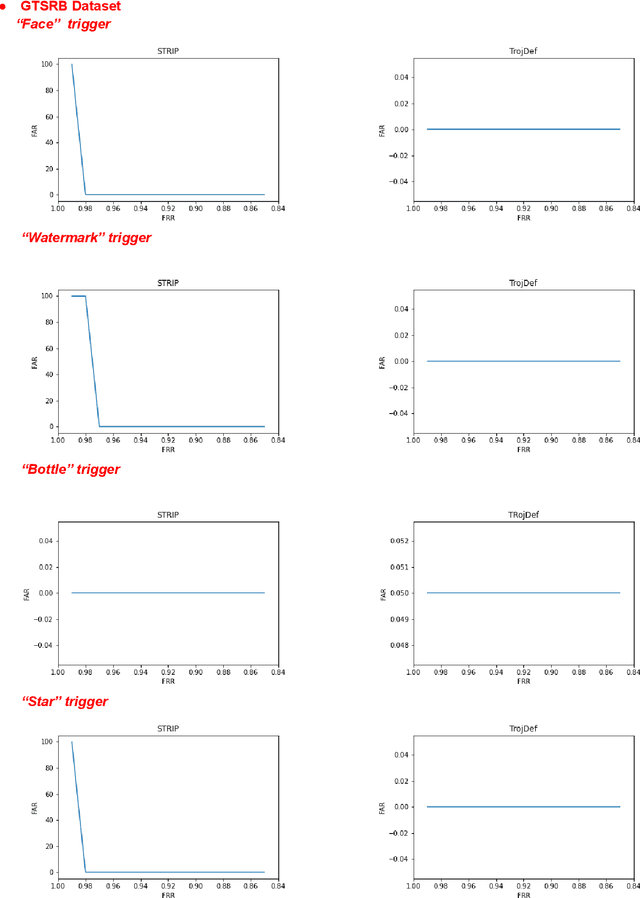
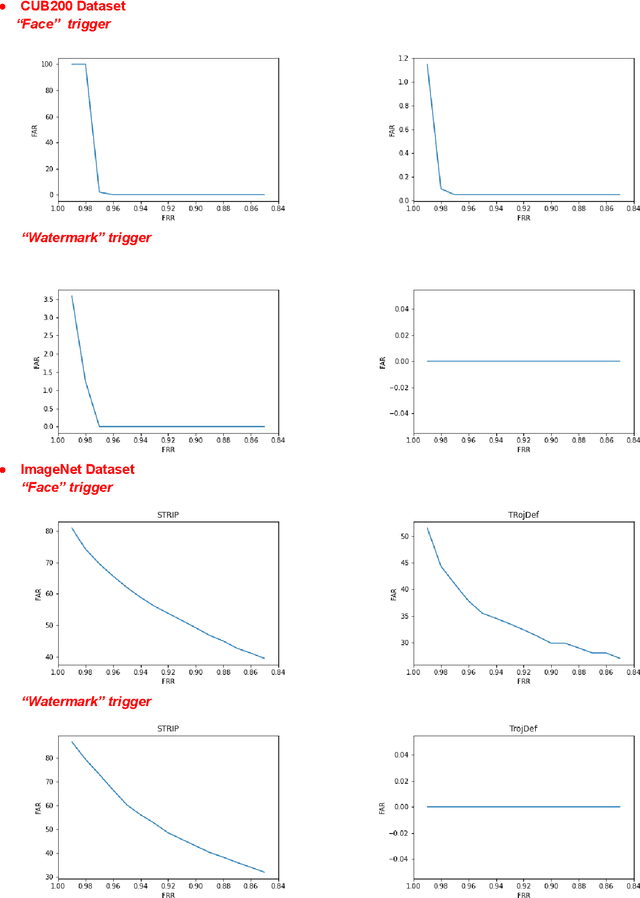
Trojan backdoor is a poisoning attack against Neural Network (NN) classifiers in which adversaries try to exploit the (highly desirable) model reuse property to implant Trojans into model parameters for backdoor breaches through a poisoned training process. Most of the proposed defenses against Trojan attacks assume a white-box setup, in which the defender either has access to the inner state of NN or is able to run back-propagation through it. In this work, we propose a more practical black-box defense, dubbed TrojDef, which can only run forward-pass of the NN. TrojDef tries to identify and filter out Trojan inputs (i.e., inputs augmented with the Trojan trigger) by monitoring the changes in the prediction confidence when the input is repeatedly perturbed by random noise. We derive a function based on the prediction outputs which is called the prediction confidence bound to decide whether the input example is Trojan or not. The intuition is that Trojan inputs are more stable as the misclassification only depends on the trigger, while benign inputs will suffer when augmented with noise due to the perturbation of the classification features. Through mathematical analysis, we show that if the attacker is perfect in injecting the backdoor, the Trojan infected model will be trained to learn the appropriate prediction confidence bound, which is used to distinguish Trojan and benign inputs under arbitrary perturbations. However, because the attacker might not be perfect in injecting the backdoor, we introduce a nonlinear transform to the prediction confidence bound to improve the detection accuracy in practical settings. Extensive empirical evaluations show that TrojDef significantly outperforms the-state-of-the-art defenses and is highly stable under different settings, even when the classifier architecture, the training process, or the hyper-parameters change.
Smart Traffic Monitoring System using Computer Vision and Edge Computing
Sep 07, 2021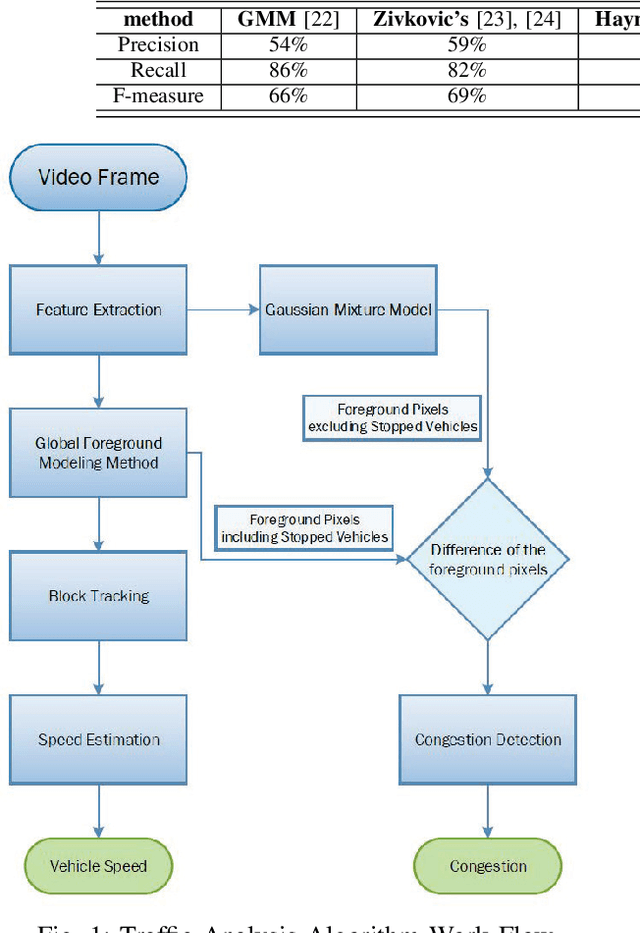


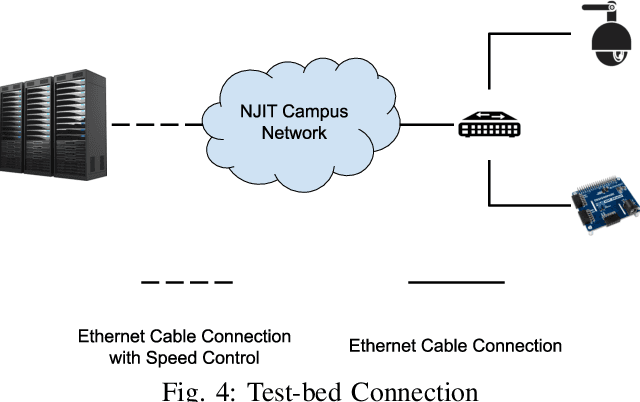
Traffic management systems capture tremendous video data and leverage advances in video processing to detect and monitor traffic incidents. The collected data are traditionally forwarded to the traffic management center (TMC) for in-depth analysis and may thus exacerbate the network paths to the TMC. To alleviate such bottlenecks, we propose to utilize edge computing by equipping edge nodes that are close to cameras with computing resources (e.g. cloudlets). A cloudlet, with limited computing resources as compared to TMC, provides limited video processing capabilities. In this paper, we focus on two common traffic monitoring tasks, congestion detection, and speed detection, and propose a two-tier edge computing based model that takes into account of both the limited computing capability in cloudlets and the unstable network condition to the TMC. Our solution utilizes two algorithms for each task, one implemented at the edge and the other one at the TMC, which are designed with the consideration of different computing resources. While the TMC provides strong computation power, the video quality it receives depends on the underlying network conditions. On the other hand, the edge processes very high-quality video but with limited computing resources. Our model captures this trade-off. We evaluate the performance of the proposed two-tier model as well as the traffic monitoring algorithms via test-bed experiments under different weather as well as network conditions and show that our proposed hybrid edge-cloud solution outperforms both the cloud-only and edge-only solutions.
A Synergetic Attack against Neural Network Classifiers combining Backdoor and Adversarial Examples
Sep 03, 2021
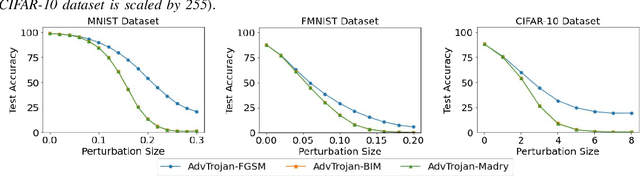
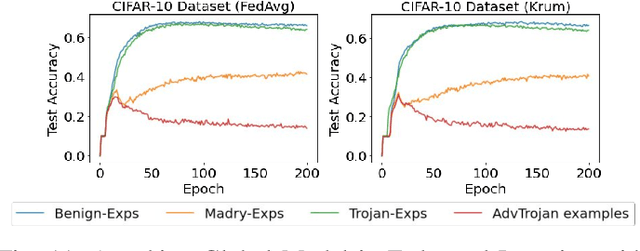
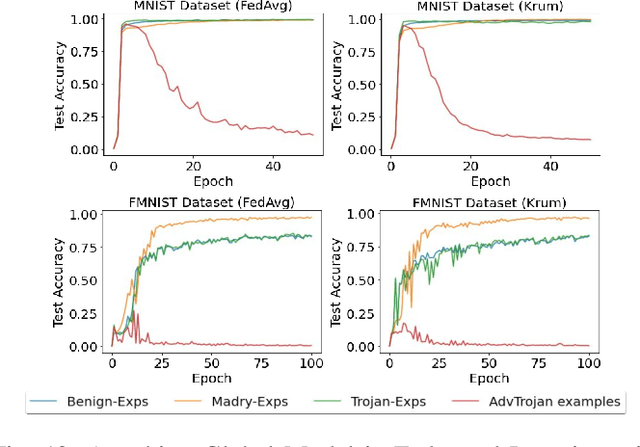
In this work, we show how to jointly exploit adversarial perturbation and model poisoning vulnerabilities to practically launch a new stealthy attack, dubbed AdvTrojan. AdvTrojan is stealthy because it can be activated only when: 1) a carefully crafted adversarial perturbation is injected into the input examples during inference, and 2) a Trojan backdoor is implanted during the training process of the model. We leverage adversarial noise in the input space to move Trojan-infected examples across the model decision boundary, making it difficult to detect. The stealthiness behavior of AdvTrojan fools the users into accidentally trust the infected model as a robust classifier against adversarial examples. AdvTrojan can be implemented by only poisoning the training data similar to conventional Trojan backdoor attacks. Our thorough analysis and extensive experiments on several benchmark datasets show that AdvTrojan can bypass existing defenses with a success rate close to 100% in most of our experimental scenarios and can be extended to attack federated learning tasks as well.
ManiGen: A Manifold Aided Black-box Generator of Adversarial Examples
Jul 11, 2020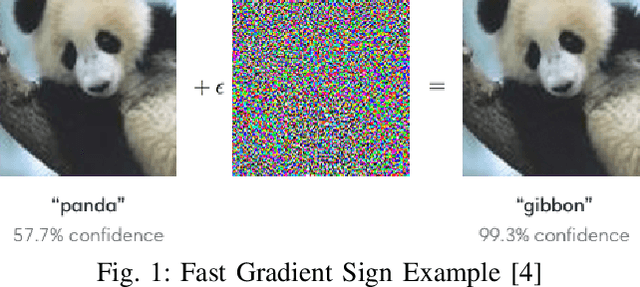

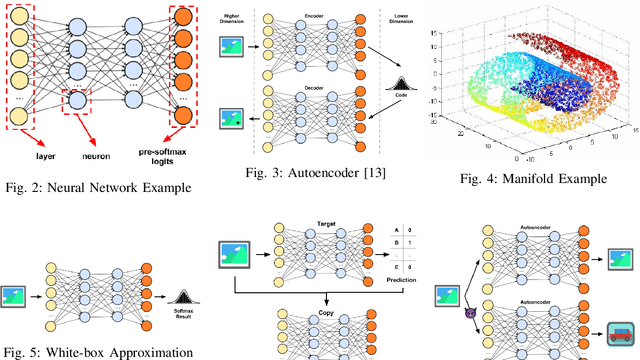

Machine learning models, especially neural network (NN) classifiers, have acceptable performance and accuracy that leads to their wide adoption in different aspects of our daily lives. The underlying assumption is that these models are generated and used in attack free scenarios. However, it has been shown that neural network based classifiers are vulnerable to adversarial examples. Adversarial examples are inputs with special perturbations that are ignored by human eyes while can mislead NN classifiers. Most of the existing methods for generating such perturbations require a certain level of knowledge about the target classifier, which makes them not very practical. For example, some generators require knowledge of pre-softmax logits while others utilize prediction scores. In this paper, we design a practical black-box adversarial example generator, dubbed ManiGen. ManiGen does not require any knowledge of the inner state of the target classifier. It generates adversarial examples by searching along the manifold, which is a concise representation of input data. Through extensive set of experiments on different datasets, we show that (1) adversarial examples generated by ManiGen can mislead standalone classifiers by being as successful as the state-of-the-art white-box generator, Carlini, and (2) adversarial examples generated by ManiGen can more effectively attack classifiers with state-of-the-art defenses.
Using Single-Step Adversarial Training to Defend Iterative Adversarial Examples
Feb 27, 2020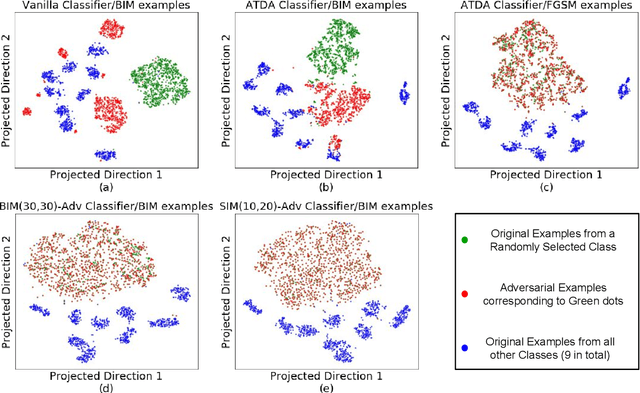
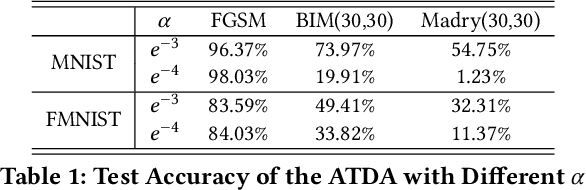
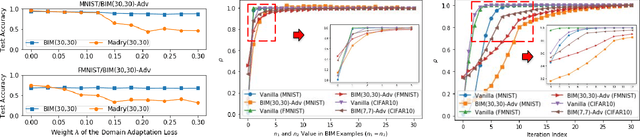

Adversarial examples have become one of the largest challenges that machine learning models, especially neural network classifiers, face. These adversarial examples break the assumption of attack-free scenario and fool state-of-the-art (SOTA) classifiers with insignificant perturbations to human. So far, researchers achieved great progress in utilizing adversarial training as a defense. However, the overwhelming computational cost degrades its applicability and little has been done to overcome this issue. Single-Step adversarial training methods have been proposed as computationally viable solutions, however they still fail to defend against iterative adversarial examples. In this work, we first experimentally analyze several different SOTA defense methods against adversarial examples. Then, based on observations from experiments, we propose a novel single-step adversarial training method which can defend against both single-step and iterative adversarial examples. Lastly, through extensive evaluations, we demonstrate that our proposed method outperforms the SOTA single-step and iterative adversarial training defense. Compared with ATDA (single-step method) on CIFAR10 dataset, our proposed method achieves 35.67% enhancement in test accuracy and 19.14% reduction in training time. When compared with methods that use BIM or Madry examples (iterative methods) on CIFAR10 dataset, it saves up to 76.03% in training time with less than 3.78% degeneration in test accuracy.
CheXclusion: Fairness gaps in deep chest X-ray classifiers
Feb 14, 2020
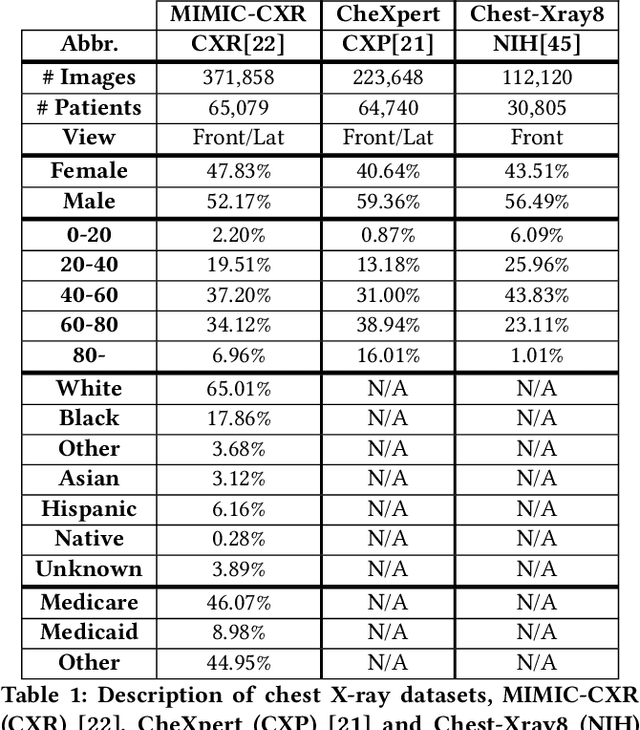
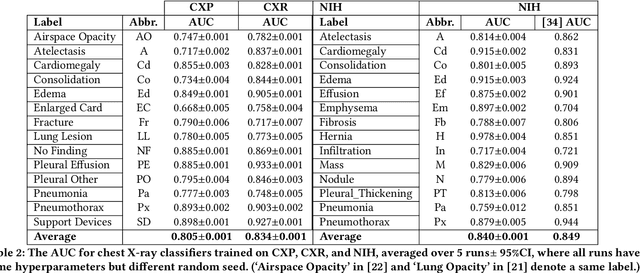
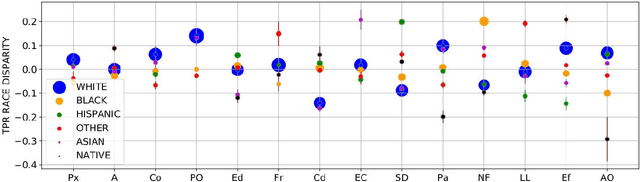
Machine learning systems have received much attention recently for their ability to achieve expert-level performance on clinical tasks, particularly in medical imaging. Here, we examine the extent to which state-of-the-art deep learning classifiers trained to yield diagnostic labels from X-ray images are biased with respect to protected attributes. We train convolution neural networks to predict 14 diagnostic labels in three prominent public chest X-ray datasets: MIMIC-CXR, Chest-Xray8, and CheXpert. We then evaluate the TPR disparity - the difference in true positive rates (TPR) and - underdiagnosis rate - the false positive rate of a non-diagnosis - among different protected attributes such as patient sex, age, race, and insurance type. We demonstrate that TPR disparities exist in the state-of-the-art classifiers in all datasets, for all clinical tasks, and all subgroups. We find that TPR disparities are most commonly not significantly correlated with a subgroup's proportional disease burden; further, we find that some subgroups and subsection of the population are chronically underdiagnosed. Such performance disparities have real consequences as models move from papers to products, and should be carefully audited prior to deployment.
Using Intuition from Empirical Properties to Simplify Adversarial Training Defense
Jun 27, 2019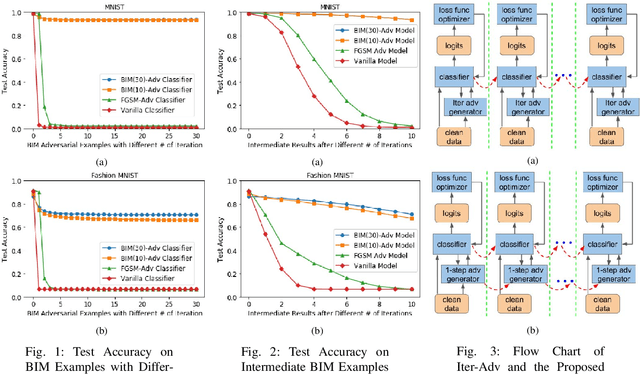

Due to the surprisingly good representation power of complex distributions, neural network (NN) classifiers are widely used in many tasks which include natural language processing, computer vision and cyber security. In recent works, people noticed the existence of adversarial examples. These adversarial examples break the NN classifiers' underlying assumption that the environment is attack free and can easily mislead fully trained NN classifier without noticeable changes. Among defensive methods, adversarial training is a popular choice. However, original adversarial training with single-step adversarial examples (Single-Adv) can not defend against iterative adversarial examples. Although adversarial training with iterative adversarial examples (Iter-Adv) can defend against iterative adversarial examples, it consumes too much computational power and hence is not scalable. In this paper, we analyze Iter-Adv techniques and identify two of their empirical properties. Based on these properties, we propose modifications which enhance Single-Adv to perform competitively as Iter-Adv. Through preliminary evaluation, we show that the proposed method enhances the test accuracy of state-of-the-art (SOTA) Single-Adv defensive method against iterative adversarial examples by up to 16.93% while reducing its training cost by 28.75%.
ZK-GanDef: A GAN based Zero Knowledge Adversarial Training Defense for Neural Networks
Apr 17, 2019

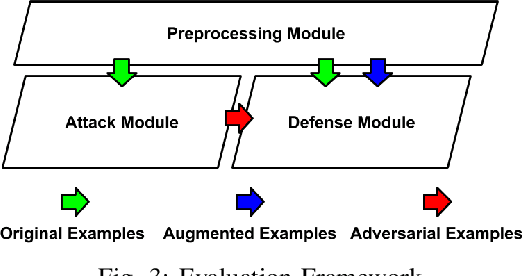
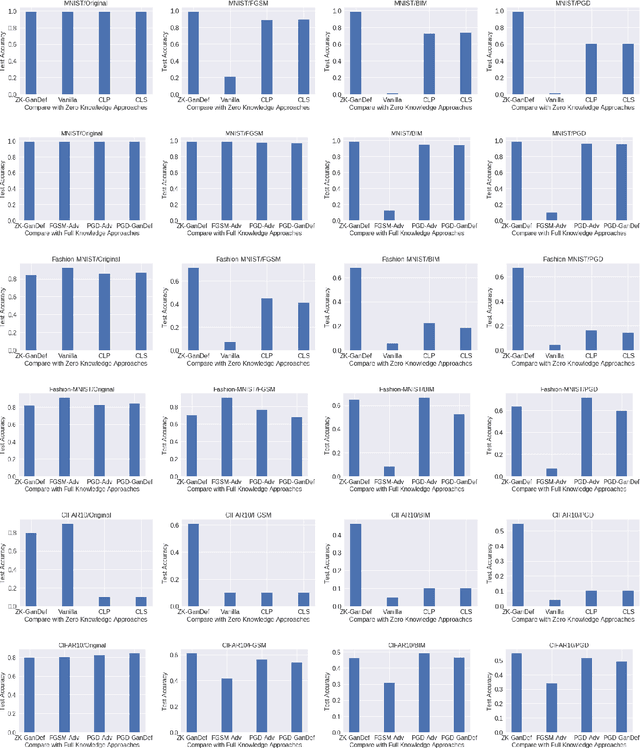
Neural Network classifiers have been used successfully in a wide range of applications. However, their underlying assumption of attack free environment has been defied by adversarial examples. Researchers tried to develop defenses; however, existing approaches are still far from providing effective solutions to this evolving problem. In this paper, we design a generative adversarial net (GAN) based zero knowledge adversarial training defense, dubbed ZK-GanDef, which does not consume adversarial examples during training. Therefore, ZK-GanDef is not only efficient in training but also adaptive to new adversarial examples. This advantage comes at the cost of small degradation in test accuracy compared to full knowledge approaches. Our experiments show that ZK-GanDef enhances test accuracy on adversarial examples by up-to 49.17% compared to zero knowledge approaches. More importantly, its test accuracy is close to that of the state-of-the-art full knowledge approaches (maximum degradation of 8.46%), while taking much less training time.
Clinically Accurate Chest X-Ray Report Generation
Apr 04, 2019
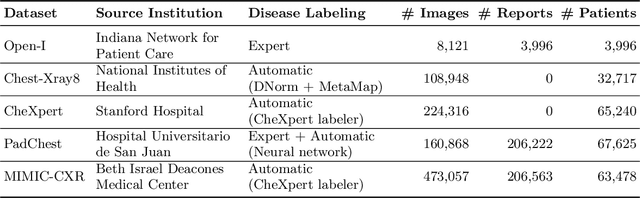
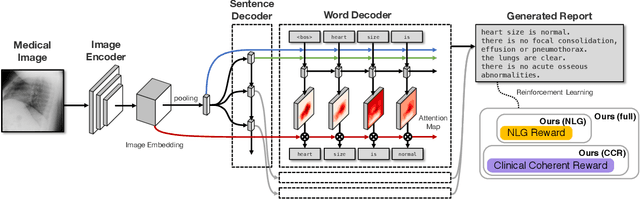
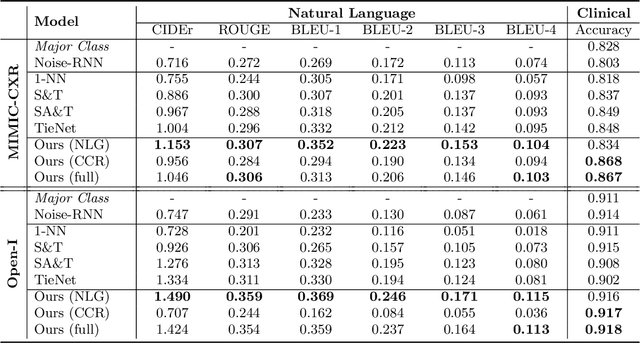
The automatic generation of radiology reports given medical radiographs has significant potential to operationally and clinically improve patient care. A number of prior works have focused on this problem, employing advanced methods from computer vision and natural language generation to produce readable reports. However, these works often fail to account for the particular nuances of the radiology domain, and, in particular, the critical importance of clinical accuracy in the resulting generated reports. In this work, we present a domain-aware automatic chest X-Ray radiology report generation system which first predicts what topics will be discussed in the report, then conditionally generates sentences corresponding to these topics. The resulting system is fine-tuned using reinforcement learning, considering both readability and clinical accuracy, as assessed by the proposed Clinically Coherent Reward. We verify this system on two datasets, Open-I and MIMIC-CXR, and demonstrate that our model offers marked improvements on both language generation metrics and CheXpert assessed accuracy over a variety of competitive baselines.