 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOIR: Privacy-Preserving Generation of Code with Open-Source LLMs
Jan 22, 2026Although boosting software development performance, large language model (LLM)-powered code generation introduces intellectual property and data security risks rooted in the fact that a service provider (cloud) observes a client's prompts and generated code, which can be proprietary in commercial systems. To mitigate this problem, we propose NOIR, the first framework to protect the client's prompts and generated code from the cloud. NOIR uses an encoder and a decoder at the client to encode and send the prompts' embeddings to the cloud to get enriched embeddings from the LLM, which are then decoded to generate the code locally at the client. Since the cloud can use the embeddings to infer the prompt and the generated code, NOIR introduces a new mechanism to achieve indistinguishability, a local differential privacy protection at the token embedding level, in the vocabulary used in the prompts and code, and a data-independent and randomized tokenizer on the client side. These components effectively defend against reconstruction and frequency analysis attacks by an honest-but-curious cloud. Extensive analysis and results using open-source LLMs show that NOIR significantly outperforms existing baselines on benchmarks, including the Evalplus (MBPP and HumanEval, Pass@1 of 76.7 and 77.4), and BigCodeBench (Pass@1 of 38.7, only a 1.77% drop from the original LLM) under strong privacy against attacks.
ViGText: Deepfake Image Detection with Vision-Language Model Explanations and Graph Neural Networks
Jul 24, 2025The rapid rise of deepfake technology, which produces realistic but fraudulent digital content, threatens the authenticity of media. Traditional deepfake detection approaches often struggle with sophisticated, customized deepfakes, especially in terms of generalization and robustness against malicious attacks. This paper introduces ViGText, a novel approach that integrates images with Vision Large Language Model (VLLM) Text explanations within a Graph-based framework to improve deepfake detection. The novelty of ViGText lies in its integration of detailed explanations with visual data, as it provides a more context-aware analysis than captions, which often lack specificity and fail to reveal subtle inconsistencies. ViGText systematically divides images into patches, constructs image and text graphs, and integrates them for analysis using Graph Neural Networks (GNNs) to identify deepfakes. Through the use of multi-level feature extraction across spatial and frequency domains, ViGText captures details that enhance its robustness and accuracy to detect sophisticated deepfakes. Extensive experiments demonstrate that ViGText significantly enhances generalization and achieves a notable performance boost when it detects user-customized deepfakes. Specifically, average F1 scores rise from 72.45% to 98.32% under generalization evaluation, and reflects the model's superior ability to generalize to unseen, fine-tuned variations of stable diffusion models. As for robustness, ViGText achieves an increase of 11.1% in recall compared to other deepfake detection approaches. When facing targeted attacks that exploit its graph-based architecture, ViGText limits classification performance degradation to less than 4%. ViGText uses detailed visual and textual analysis to set a new standard for detecting deepfakes, helping ensure media authenticity and information integrity.
CAMME: Adaptive Deepfake Image Detection with Multi-Modal Cross-Attention
May 23, 2025



The proliferation of sophisticated AI-generated deepfakes poses critical challenges for digital media authentication and societal security. While existing detection methods perform well within specific generative domains, they exhibit significant performance degradation when applied to manipulations produced by unseen architectures--a fundamental limitation as generative technologies rapidly evolve. We propose CAMME (Cross-Attention Multi-Modal Embeddings), a framework that dynamically integrates visual, textual, and frequency-domain features through a multi-head cross-attention mechanism to establish robust cross-domain generalization. Extensive experiments demonstrate CAMME's superiority over state-of-the-art methods, yielding improvements of 12.56% on natural scenes and 13.25% on facial deepfakes. The framework demonstrates exceptional resilience, maintaining (over 91%) accuracy under natural image perturbations and achieving 89.01% and 96.14% accuracy against PGD and FGSM adversarial attacks, respectively. Our findings validate that integrating complementary modalities through cross-attention enables more effective decision boundary realignment for reliable deepfake detection across heterogeneous generative architectures.
CapsFake: A Multimodal Capsule Network for Detecting Instruction-Guided Deepfakes
Apr 27, 2025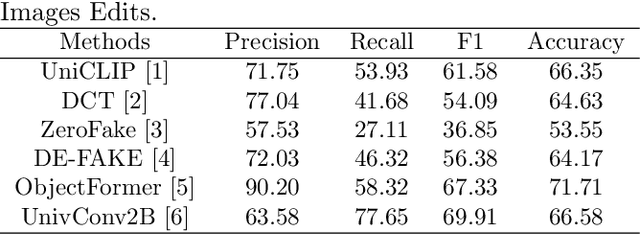

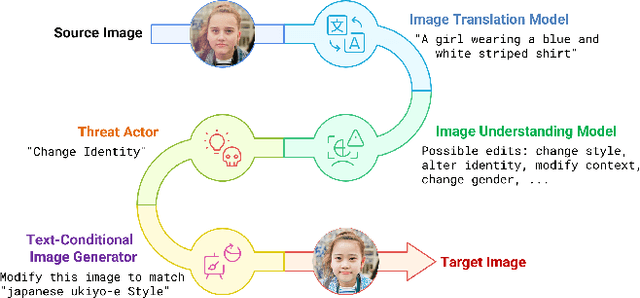
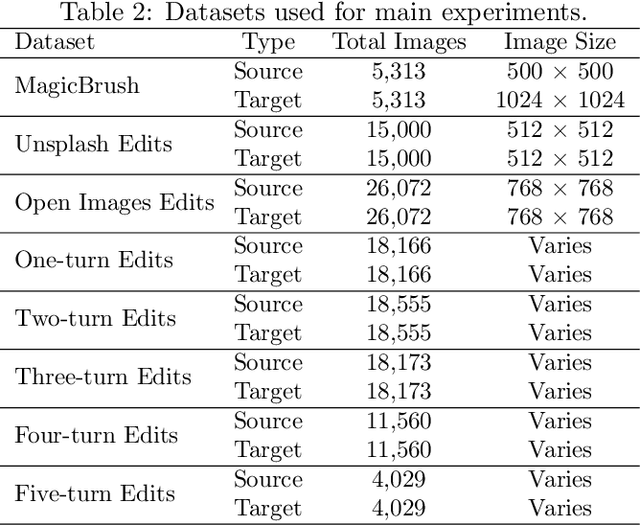
The rapid evolution of deepfake technology, particularly in instruction-guided image editing, threatens the integrity of digital images by enabling subtle, context-aware manipulations. Generated conditionally from real images and textual prompts, these edits are often imperceptible to both humans and existing detection systems, revealing significant limitations in current defenses. We propose a novel multimodal capsule network, CapsFake, designed to detect such deepfake image edits by integrating low-level capsules from visual, textual, and frequency-domain modalities. High-level capsules, predicted through a competitive routing mechanism, dynamically aggregate local features to identify manipulated regions with precision. Evaluated on diverse datasets, including MagicBrush, Unsplash Edits, Open Images Edits, and Multi-turn Edits, CapsFake outperforms state-of-the-art methods by up to 20% in detection accuracy. Ablation studies validate its robustness, achieving detection rates above 94% under natural perturbations and 96% against adversarial attacks, with excellent generalization to unseen editing scenarios. This approach establishes a powerful framework for countering sophisticated image manipulations.
aiXamine: Simplified LLM Safety and Security
Apr 23, 2025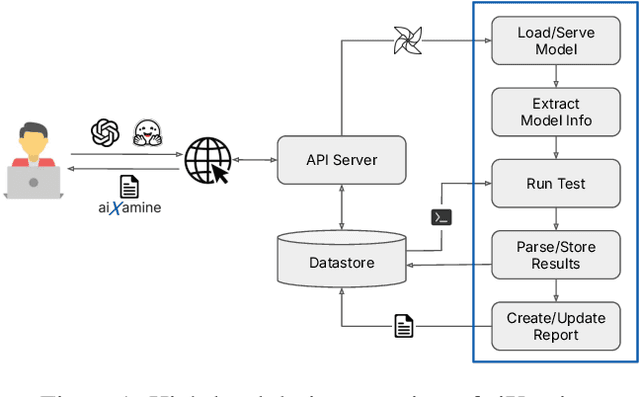



Evaluating Large Language Models (LLMs) for safety and security remains a complex task, often requiring users to navigate a fragmented landscape of ad hoc benchmarks, datasets, metrics, and reporting formats. To address this challenge, we present aiXamine, a comprehensive black-box evaluation platform for LLM safety and security. aiXamine integrates over 40 tests (i.e., benchmarks) organized into eight key services targeting specific dimensions of safety and security: adversarial robustness, code security, fairness and bias, hallucination, model and data privacy, out-of-distribution (OOD) robustness, over-refusal, and safety alignment. The platform aggregates the evaluation results into a single detailed report per model, providing a detailed breakdown of model performance, test examples, and rich visualizations. We used aiXamine to assess over 50 publicly available and proprietary LLMs, conducting over 2K examinations. Our findings reveal notable vulnerabilities in leading models, including susceptibility to adversarial attacks in OpenAI's GPT-4o, biased outputs in xAI's Grok-3, and privacy weaknesses in Google's Gemini 2.0. Additionally, we observe that open-source models can match or exceed proprietary models in specific services such as safety alignment, fairness and bias, and OOD robustness. Finally, we identify trade-offs between distillation strategies, model size, training methods, and architectural choices.
aiXamine: LLM Safety and Security Simplified
Apr 21, 2025Evaluating Large Language Models (LLMs) for safety and security remains a complex task, often requiring users to navigate a fragmented landscape of ad hoc benchmarks, datasets, metrics, and reporting formats. To address this challenge, we present aiXamine, a comprehensive black-box evaluation platform for LLM safety and security. aiXamine integrates over 40 tests (i.e., benchmarks) organized into eight key services targeting specific dimensions of safety and security: adversarial robustness, code security, fairness and bias, hallucination, model and data privacy, out-of-distribution (OOD) robustness, over-refusal, and safety alignment. The platform aggregates the evaluation results into a single detailed report per model, providing a detailed breakdown of model performance, test examples, and rich visualizations. We used aiXamine to assess over 50 publicly available and proprietary LLMs, conducting over 2K examinations. Our findings reveal notable vulnerabilities in leading models, including susceptibility to adversarial attacks in OpenAI's GPT-4o, biased outputs in xAI's Grok-3, and privacy weaknesses in Google's Gemini 2.0. Additionally, we observe that open-source models can match or exceed proprietary models in specific services such as safety alignment, fairness and bias, and OOD robustness. Finally, we identify trade-offs between distillation strategies, model size, training methods, and architectural choices.
A Client-level Assessment of Collaborative Backdoor Poisoning in Non-IID Federated Learning
Apr 21, 2025Federated learning (FL) enables collaborative model training using decentralized private data from multiple clients. While FL has shown robustness against poisoning attacks with basic defenses, our research reveals new vulnerabilities stemming from non-independent and identically distributed (non-IID) data among clients. These vulnerabilities pose a substantial risk of model poisoning in real-world FL scenarios. To demonstrate such vulnerabilities, we develop a novel collaborative backdoor poisoning attack called CollaPois. In this attack, we distribute a single pre-trained model infected with a Trojan to a group of compromised clients. These clients then work together to produce malicious gradients, causing the FL model to consistently converge towards a low-loss region centered around the Trojan-infected model. Consequently, the impact of the Trojan is amplified, especially when the benign clients have diverse local data distributions and scattered local gradients. CollaPois stands out by achieving its goals while involving only a limited number of compromised clients, setting it apart from existing attacks. Also, CollaPois effectively avoids noticeable shifts or degradation in the FL model's performance on legitimate data samples, allowing it to operate stealthily and evade detection by advanced robust FL algorithms. Thorough theoretical analysis and experiments conducted on various benchmark datasets demonstrate the superiority of CollaPois compared to state-of-the-art backdoor attacks. Notably, CollaPois bypasses existing backdoor defenses, especially in scenarios where clients possess diverse data distributions. Moreover, the results show that CollaPois remains effective even when involving a small number of compromised clients. Notably, clients whose local data is closely aligned with compromised clients experience higher risks of backdoor infections.
DeBackdoor: A Deductive Framework for Detecting Backdoor Attacks on Deep Models with Limited Data
Mar 27, 2025


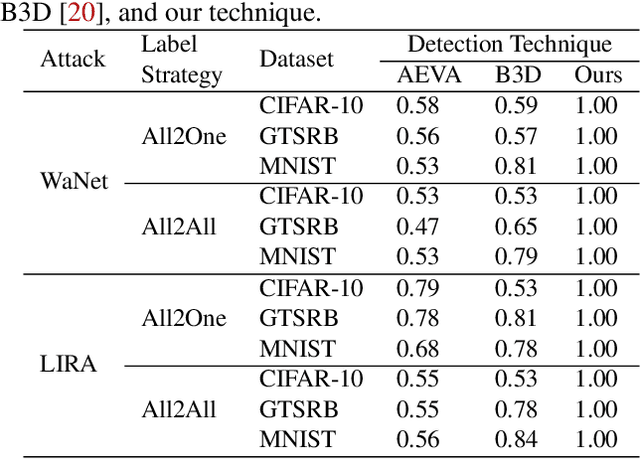
Backdoor attacks are among the most effective, practical, and stealthy attacks in deep learning. In this paper, we consider a practical scenario where a developer obtains a deep model from a third party and uses it as part of a safety-critical system. The developer wants to inspect the model for potential backdoors prior to system deployment. We find that most existing detection techniques make assumptions that are not applicable to this scenario. In this paper, we present a novel framework for detecting backdoors under realistic restrictions. We generate candidate triggers by deductively searching over the space of possible triggers. We construct and optimize a smoothed version of Attack Success Rate as our search objective. Starting from a broad class of template attacks and just using the forward pass of a deep model, we reverse engineer the backdoor attack. We conduct extensive evaluation on a wide range of attacks, models, and datasets, with our technique performing almost perfectly across these settings.
StructTransform: A Scalable Attack Surface for Safety-Aligned Large Language Models
Feb 17, 2025



In this work, we present a series of structure transformation attacks on LLM alignment, where we encode natural language intent using diverse syntax spaces, ranging from simple structure formats and basic query languages (e.g. SQL) to new novel spaces and syntaxes created entirely by LLMs. Our extensive evaluation shows that our simplest attacks can achieve close to 90% success rate, even on strict LLMs (such as Claude 3.5 Sonnet) using SOTA alignment mechanisms. We improve the attack performance further by using an adaptive scheme that combines structure transformations along with existing \textit{content transformations}, resulting in over 96% ASR with 0% refusals. To generalize our attacks, we explore numerous structure formats, including syntaxes purely generated by LLMs. Our results indicate that such novel syntaxes are easy to generate and result in a high ASR, suggesting that defending against our attacks is not a straightforward process. Finally, we develop a benchmark and evaluate existing safety-alignment defenses against it, showing that most of them fail with 100% ASR. Our results show that existing safety alignment mostly relies on token-level patterns without recognizing harmful concepts, highlighting and motivating the need for serious research efforts in this direction. As a case study, we demonstrate how attackers can use our attack to easily generate a sample malware, and a corpus of fraudulent SMS messages, which perform well in bypassing detection.
Demo: SGCode: A Flexible Prompt-Optimizing System for Secure Generation of Code
Sep 11, 2024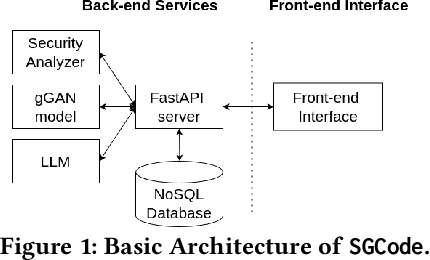
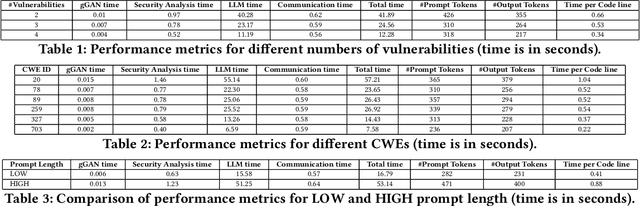
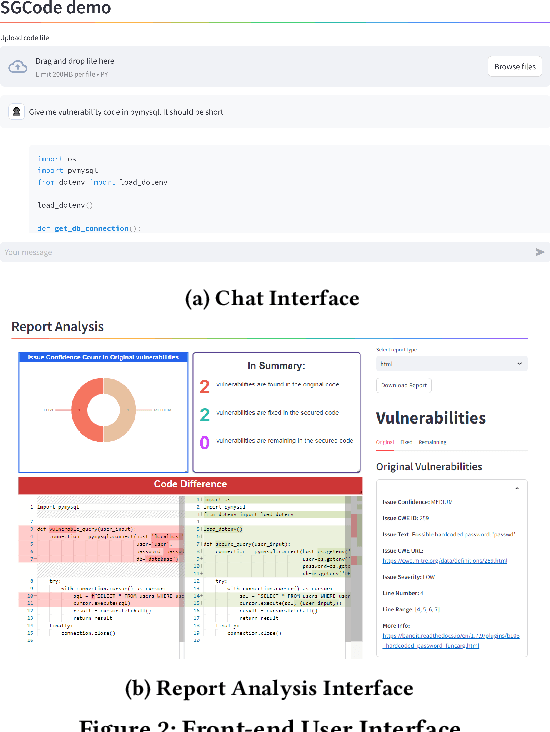
This paper introduces SGCode, a flexible prompt-optimizing system to generate secure code with large language models (LLMs). SGCode integrates recent prompt-optimization approaches with LLMs in a unified system accessible through front-end and back-end APIs, enabling users to 1) generate secure code, which is free of vulnerabilities, 2) review and share security analysis, and 3) easily switch from one prompt optimization approach to another, while providing insights on model and system performance. We populated SGCode on an AWS server with PromSec, an approach that optimizes prompts by combining an LLM and security tools with a lightweight generative adversarial graph neural network to detect and fix security vulnerabilities in the generated code. Extensive experiments show that SGCode is practical as a public tool to gain insights into the trade-offs between model utility, secure code generation, and system cost. SGCode has only a marginal cost compared with prompting LLMs. SGCode is available at: http://3.131.141.63:8501/.