 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermal Imaging for Contactless Cardiorespiratory and Sudomotor Response Monitoring
Feb 12, 2026Thermal infrared imaging captures skin temperature changes driven by autonomic regulation and can potentially provide contactless estimation of electrodermal activity (EDA), heart rate (HR), and breathing rate (BR). While visible-light methods address HR and BR, they cannot access EDA, a standard marker of sympathetic activation. This paper characterizes the extraction of these three biosignals from facial thermal video using a signal-processing pipeline that tracks anatomical regions, applies spatial aggregation, and separates slow sudomotor trends from faster cardiorespiratory components. For HR, we apply an orthogonal matrix image transformation (OMIT) decomposition across multiple facial regions of interest (ROIs), and for BR we average nasal and cheek signals before spectral peak detection. We evaluate 288 EDA configurations and the HR/BR pipeline on 31 sessions from the public SIMULATOR STUDY 1 (SIM1) driver monitoring dataset. The best fixed EDA configuration (nose region, exponential moving average) reaches a mean absolute correlation of $0.40 \pm 0.23$ against palm EDA, with individual sessions reaching 0.89. BR estimation achieves a mean absolute error of $3.1 \pm 1.1$ bpm, while HR estimation yields $13.8 \pm 7.5$ bpm MAE, limited by the low camera frame rate (7.5 Hz). We report signal polarity alternation across sessions, short thermodynamic latency for well-tracked signals, and condition-dependent and demographic effects on extraction quality. These results provide baseline performance bounds and design guidance for thermal contactless biosignal estimation.
Quality-Aware Framework for Video-Derived Respiratory Signals
Dec 16, 2025
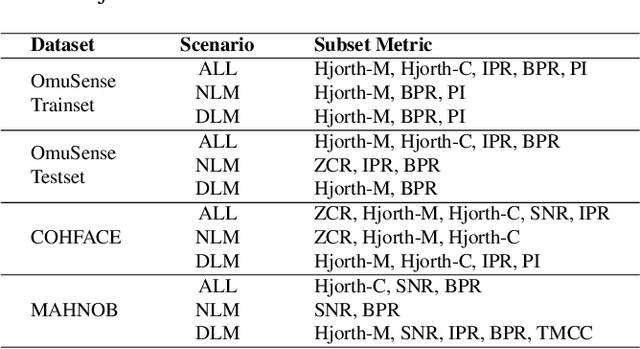
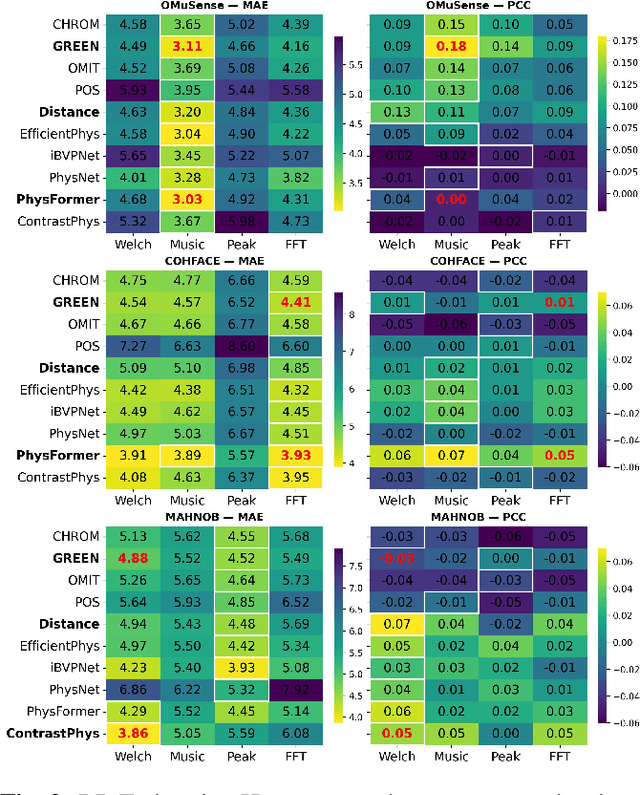
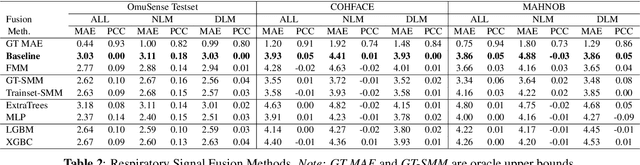
Video-based respiratory rate (RR) estimation is often unreliable due to inconsistent signal quality across extraction methods. We present a predictive, quality-aware framework that integrates heterogeneous signal sources with dynamic assessment of reliability. Ten signals are extracted from facial remote photoplethysmography (rPPG), upper-body motion, and deep learning pipelines, and analyzed using four spectral estimators: Welch's method, Multiple Signal Classification (MUSIC), Fast Fourier Transform (FFT), and peak detection. Segment-level quality indices are then used to train machine learning models that predict accuracy or select the most reliable signal. This enables adaptive signal fusion and quality-based segment filtering. Experiments on three public datasets (OMuSense-23, COHFACE, MAHNOB-HCI) show that the proposed framework achieves lower RR estimation errors than individual methods in most cases, with performance gains depending on dataset characteristics. These findings highlight the potential of quality-driven predictive modeling to deliver scalable and generalizable video-based respiratory monitoring solutions.
Black Box Causal Inference: Effect Estimation via Meta Prediction
Mar 07, 2025



Causal inference and the estimation of causal effects plays a central role in decision-making across many areas, including healthcare and economics. Estimating causal effects typically requires an estimator that is tailored to each problem of interest. But developing estimators can take significant effort for even a single causal inference setting. For example, algorithms for regression-based estimators, propensity score methods, and doubly robust methods were designed across several decades to handle causal estimation with observed confounders. Similarly, several estimators have been developed to exploit instrumental variables (IVs), including two-stage least-squares (TSLS), control functions, and the method-of-moments. In this work, we instead frame causal inference as a dataset-level prediction problem, offloading algorithm design to the learning process. The approach we introduce, called black box causal inference (BBCI), builds estimators in a black-box manner by learning to predict causal effects from sampled dataset-effect pairs. We demonstrate accurate estimation of average treatment effects (ATEs) and conditional average treatment effects (CATEs) with BBCI across several causal inference problems with known identification, including problems with less developed estimators.
Explanations that reveal all through the definition of encoding
Nov 04, 2024



Feature attributions attempt to highlight what inputs drive predictive power. Good attributions or explanations are thus those that produce inputs that retain this predictive power; accordingly, evaluations of explanations score their quality of prediction. However, evaluations produce scores better than what appears possible from the values in the explanation for a class of explanations, called encoding explanations. Probing for encoding remains a challenge because there is no general characterization of what gives the extra predictive power. We develop a definition of encoding that identifies this extra predictive power via conditional dependence and show that the definition fits existing examples of encoding. This definition implies, in contrast to encoding explanations, that non-encoding explanations contain all the informative inputs used to produce the explanation, giving them a "what you see is what you get" property, which makes them transparent and simple to use. Next, we prove that existing scores (ROAR, FRESH, EVAL-X) do not rank non-encoding explanations above encoding ones, and develop STRIPE-X which ranks them correctly. After empirically demonstrating the theoretical insights, we use STRIPE-X to uncover encoding in LLM-generated explanations for predicting the sentiment in movie reviews.
* 35 pages, 7 figures, 6 tables, 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
Demo: SGCode: A Flexible Prompt-Optimizing System for Secure Generation of Code
Sep 11, 2024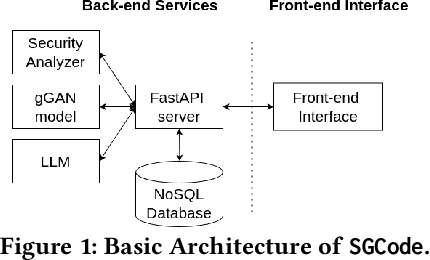
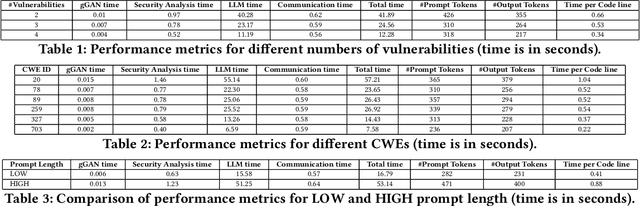
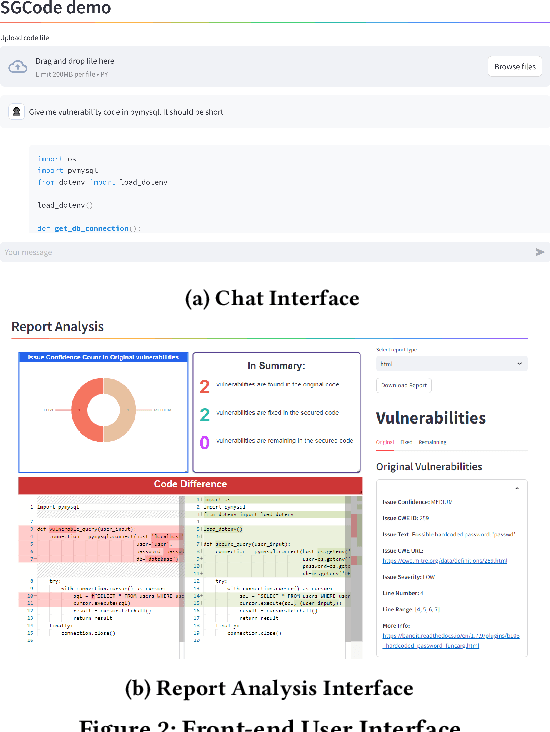
This paper introduces SGCode, a flexible prompt-optimizing system to generate secure code with large language models (LLMs). SGCode integrates recent prompt-optimization approaches with LLMs in a unified system accessible through front-end and back-end APIs, enabling users to 1) generate secure code, which is free of vulnerabilities, 2) review and share security analysis, and 3) easily switch from one prompt optimization approach to another, while providing insights on model and system performance. We populated SGCode on an AWS server with PromSec, an approach that optimizes prompts by combining an LLM and security tools with a lightweight generative adversarial graph neural network to detect and fix security vulnerabilities in the generated code. Extensive experiments show that SGCode is practical as a public tool to gain insights into the trade-offs between model utility, secure code generation, and system cost. SGCode has only a marginal cost compared with prompting LLMs. SGCode is available at: http://3.131.141.63:8501/.
Evaluation of Video-Based rPPG in Challenging Environments: Artifact Mitigation and Network Resilience
May 02, 2024Video-based remote photoplethysmography (rPPG) has emerged as a promising technology for non-contact vital sign monitoring, especially under controlled conditions. However, the accurate measurement of vital signs in real-world scenarios faces several challenges, including artifacts induced by videocodecs, low-light noise, degradation, low dynamic range, occlusions, and hardware and network constraints. In this article, we systematically investigate comprehensive investigate these issues, measuring their detrimental effects on the quality of rPPG measurements. Additionally, we propose practical strategies for mitigating these challenges to improve the dependability and resilience of video-based rPPG systems. We detail methods for effective biosignal recovery in the presence of network limitations and present denoising and inpainting techniques aimed at preserving video frame integrity. Through extensive evaluations and direct comparisons, we demonstrate the effectiveness of the approaches in enhancing rPPG measurements under challenging environments, contributing to the development of more reliable and effective remote vital sign monitoring technologies.
Multi-objective Feature Selection in Remote Health Monitoring Applications
Jan 10, 2024Radio frequency (RF) signals have facilitated the development of non-contact human monitoring tasks, such as vital signs measurement, activity recognition, and user identification. In some specific scenarios, an RF signal analysis framework may prioritize the performance of one task over that of others. In response to this requirement, we employ a multi-objective optimization approach inspired by biological principles to select discriminative features that enhance the accuracy of breathing patterns recognition while simultaneously impeding the identification of individual users. This approach is validated using a novel vital signs dataset consisting of 50 subjects engaged in four distinct breathing patterns. Our findings indicate a remarkable result: a substantial divergence in accuracy between breathing recognition and user identification. As a complementary viewpoint, we present a contrariwise result to maximize user identification accuracy and minimize the system's capacity for breathing activity recognition.
A Flow Artist for High-Dimensional Cellular Data
Jul 31, 2023We consider the problem of embedding point cloud data sampled from an underlying manifold with an associated flow or velocity. Such data arises in many contexts where static snapshots of dynamic entities are measured, including in high-throughput biology such as single-cell transcriptomics. Existing embedding techniques either do not utilize velocity information or embed the coordinates and velocities independently, i.e., they either impose velocities on top of an existing point embedding or embed points within a prescribed vector field. Here we present FlowArtist, a neural network that embeds points while jointly learning a vector field around the points. The combination allows FlowArtist to better separate and visualize velocity-informed structures. Our results, on toy datasets and single-cell RNA velocity data, illustrate the value of utilizing coordinate and velocity information in tandem for embedding and visualizing high-dimensional data.
Non-Contact Heart Rate Measurement from Deteriorated Videos
Apr 28, 2023Remote photoplethysmography (rPPG) offers a state-of-the-art, non-contact methodology for estimating human pulse by analyzing facial videos. Despite its potential, rPPG methods can be susceptible to various artifacts, such as noise, occlusions, and other obstructions caused by sunglasses, masks, or even involuntary facial contact, such as individuals inadvertently touching their faces. In this study, we apply image processing transformations to intentionally degrade video quality, mimicking these challenging conditions, and subsequently evaluate the performance of both non-learning and learning-based rPPG methods on the deteriorated data. Our results reveal a significant decrease in accuracy in the presence of these artifacts, prompting us to propose the application of restoration techniques, such as denoising and inpainting, to improve heart-rate estimation outcomes. By addressing these challenging conditions and occlusion artifacts, our approach aims to make rPPG methods more robust and adaptable to real-world situations. To assess the effectiveness of our proposed methods, we undertake comprehensive experiments on three publicly available datasets, encompassing a wide range of scenarios and artifact types. Our findings underscore the potential to construct a robust rPPG system by employing an optimal combination of restoration algorithms and rPPG techniques. Moreover, our study contributes to the advancement of privacy-conscious rPPG methodologies, thereby bolstering the overall utility and impact of this innovative technology in the field of remote heart-rate estimation under realistic and diverse conditions.
AMPNet: Attention as Message Passing for Graph Neural Networks
Oct 17, 2022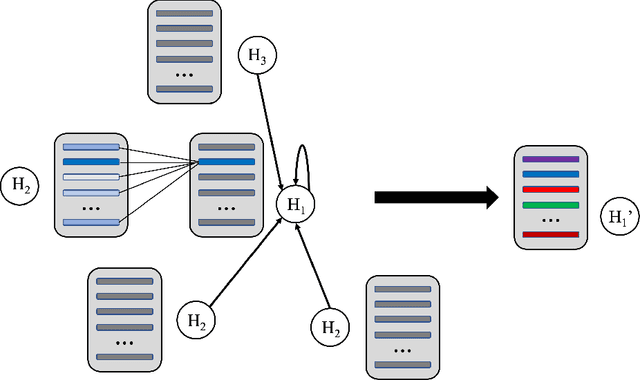
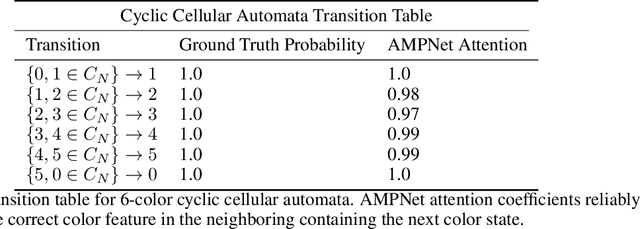
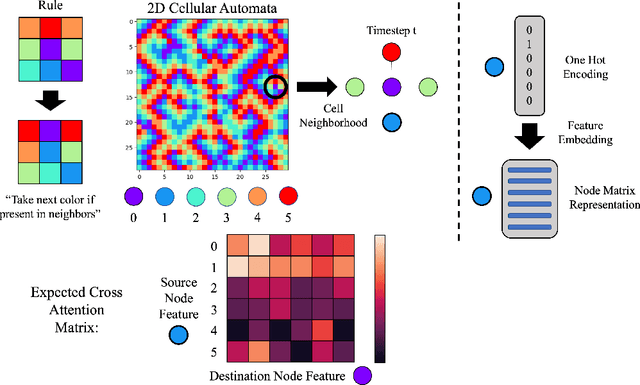
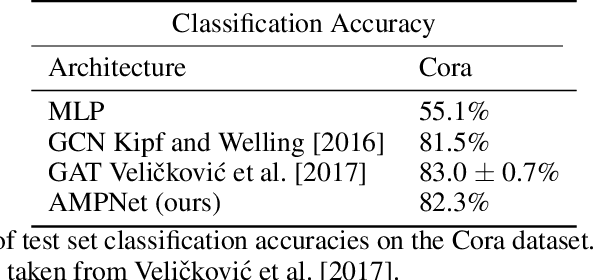
Feature-level interactions between nodes can carry crucial information for understanding complex interactions in graph-structured data. Current interpretability techniques, however, are limited in their ability to capture feature-level interactions between different nodes. In this work, we propose AMPNet, a general Graph Neural Network (GNN) architecture for uncovering feature-level interactions between different spatial locations within graph-structured data. Our framework applies a multiheaded attention operation during message-passing to contextualize messages based on the feature interactions between different nodes. We evaluate AMPNet on several benchmark and real-world datasets, and develop a synthetic benchmark based on cyclic cellular automata to test the ability of our framework to recover cyclic patterns in node states based on feature-interactions. We also propose several methods for addressing the scalability of our architecture to large graphs, including subgraph sampling during training and node feature downsampling.