 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemUV: Deep Learning based semantic manipulation over UV texture map of virtual human heads
Jun 28, 2024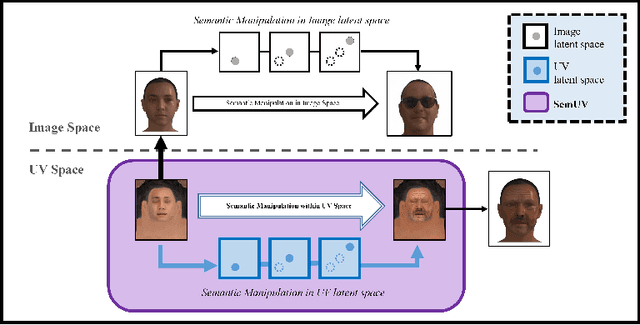

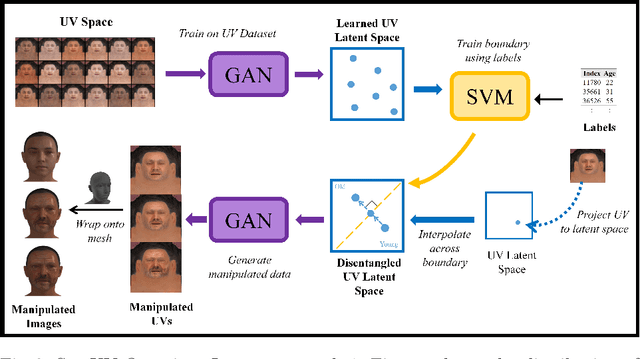

Designing and manipulating virtual human heads is essential across various applications, including AR, VR, gaming, human-computer interaction and VFX. Traditional graphic-based approaches require manual effort and resources to achieve accurate representation of human heads. While modern deep learning techniques can generate and edit highly photorealistic images of faces, their focus remains predominantly on 2D facial images. This limitation makes them less suitable for 3D applications. Recognizing the vital role of editing within the UV texture space as a key component in the 3D graphics pipeline, our work focuses on this aspect to benefit graphic designers by providing enhanced control and precision in appearance manipulation. Research on existing methods within the UV texture space is limited, complex, and poses challenges. In this paper, we introduce SemUV: a simple and effective approach using the FFHQ-UV dataset for semantic manipulation directly within the UV texture space. We train a StyleGAN model on the publicly available FFHQ-UV dataset, and subsequently train a boundary for interpolation and semantic feature manipulation. Through experiments comparing our method with 2D manipulation technique, we demonstrate its superior ability to preserve identity while effectively modifying semantic features such as age, gender, and facial hair. Our approach is simple, agnostic to other 3D components such as structure, lighting, and rendering, and also enables seamless integration into standard 3D graphics pipelines without demanding extensive domain expertise, time, or resources.
RID-TWIN: An end-to-end pipeline for automatic face de-identification in videos
Mar 15, 2024
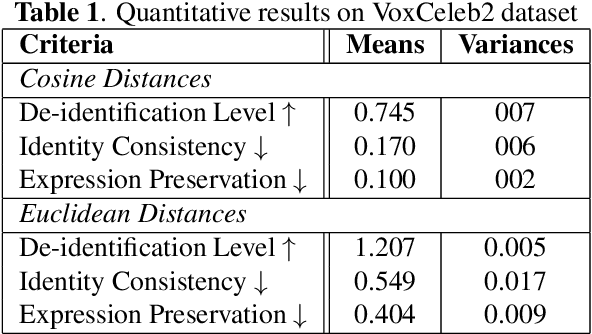
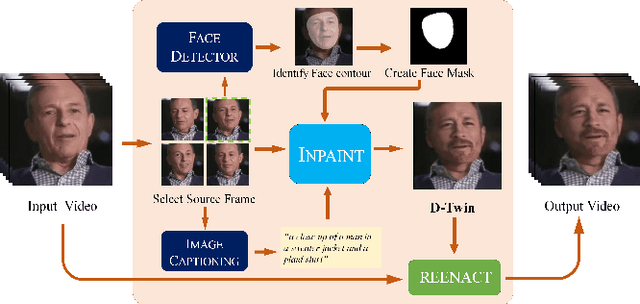
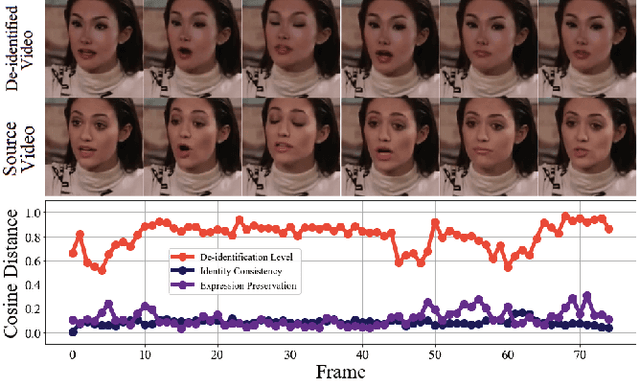
Face de-identification in videos is a challenging task in the domain of computer vision, primarily used in privacy-preserving applications. Despite the considerable progress achieved through generative vision models, there remain multiple challenges in the latest approaches. They lack a comprehensive discussion and evaluation of aspects such as realism, temporal coherence, and preservation of non-identifiable features. In our work, we propose RID-Twin: a novel pipeline that leverages the state-of-the-art generative models, and decouples identity from motion to perform automatic face de-identification in videos. We investigate the task from a holistic point of view and discuss how our approach addresses the pertinent existing challenges in this domain. We evaluate the performance of our methodology on the widely employed VoxCeleb2 dataset, and also a custom dataset designed to accommodate the limitations of certain behavioral variations absent in the VoxCeleb2 dataset. We discuss the implications and advantages of our work and suggest directions for future research.
Multi-objective Feature Selection in Remote Health Monitoring Applications
Jan 10, 2024Radio frequency (RF) signals have facilitated the development of non-contact human monitoring tasks, such as vital signs measurement, activity recognition, and user identification. In some specific scenarios, an RF signal analysis framework may prioritize the performance of one task over that of others. In response to this requirement, we employ a multi-objective optimization approach inspired by biological principles to select discriminative features that enhance the accuracy of breathing patterns recognition while simultaneously impeding the identification of individual users. This approach is validated using a novel vital signs dataset consisting of 50 subjects engaged in four distinct breathing patterns. Our findings indicate a remarkable result: a substantial divergence in accuracy between breathing recognition and user identification. As a complementary viewpoint, we present a contrariwise result to maximize user identification accuracy and minimize the system's capacity for breathing activity recognition.
Non-contact Multimodal Indoor Human Monitoring Systems: A Survey
Dec 11, 2023



Indoor human monitoring systems leverage a wide range of sensors, including cameras, radio devices, and inertial measurement units, to collect extensive data from users and the environment. These sensors contribute diverse data modalities, such as video feeds from cameras, received signal strength indicators and channel state information from WiFi devices, and three-axis acceleration data from inertial measurement units. In this context, we present a comprehensive survey of multimodal approaches for indoor human monitoring systems, with a specific focus on their relevance in elderly care. Our survey primarily highlights non-contact technologies, particularly cameras and radio devices, as key components in the development of indoor human monitoring systems. Throughout this article, we explore well-established techniques for extracting features from multimodal data sources. Our exploration extends to methodologies for fusing these features and harnessing multiple modalities to improve the accuracy and robustness of machine learning models. Furthermore, we conduct comparative analysis across different data modalities in diverse human monitoring tasks and undertake a comprehensive examination of existing multimodal datasets. This extensive survey not only highlights the significance of indoor human monitoring systems but also affirms their versatile applications. In particular, we emphasize their critical role in enhancing the quality of elderly care, offering valuable insights into the development of non-contact monitoring solutions applicable to the needs of aging populations.
Rehabilitation Exercise Repetition Segmentation and Counting using Skeletal Body Joints
Apr 19, 2023Physical exercise is an essential component of rehabilitation programs that improve quality of life and reduce mortality and re-hospitalization rates. In AI-driven virtual rehabilitation programs, patients complete their exercises independently at home, while AI algorithms analyze the exercise data to provide feedback to patients and report their progress to clinicians. To analyze exercise data, the first step is to segment it into consecutive repetitions. There has been a significant amount of research performed on segmenting and counting the repetitive activities of healthy individuals using raw video data, which raises concerns regarding privacy and is computationally intensive. Previous research on patients' rehabilitation exercise segmentation relied on data collected by multiple wearable sensors, which are difficult to use at home by rehabilitation patients. Compared to healthy individuals, segmenting and counting exercise repetitions in patients is more challenging because of the irregular repetition duration and the variation between repetitions. This paper presents a novel approach for segmenting and counting the repetitions of rehabilitation exercises performed by patients, based on their skeletal body joints. Skeletal body joints can be acquired through depth cameras or computer vision techniques applied to RGB videos of patients. Various sequential neural networks are designed to analyze the sequences of skeletal body joints and perform repetition segmentation and counting. Extensive experiments on three publicly available rehabilitation exercise datasets, KIMORE, UI-PRMD, and IntelliRehabDS, demonstrate the superiority of the proposed method compared to previous methods. The proposed method enables accurate exercise analysis while preserving privacy, facilitating the effective delivery of virtual rehabilitation programs.
Bag of States: A Non-sequential Approach to Video-based Engagement Measurement
Jan 17, 2023Automatic measurement of student engagement provides helpful information for instructors to meet learning program objectives and individualize program delivery. Students' behavioral and emotional states need to be analyzed at fine-grained time scales in order to measure their level of engagement. Many existing approaches have developed sequential and spatiotemporal models, such as recurrent neural networks, temporal convolutional networks, and three-dimensional convolutional neural networks, for measuring student engagement from videos. These models are trained to incorporate the order of behavioral and emotional states of students into video analysis and output their level of engagement. In this paper, backed by educational psychology, we question the necessity of modeling the order of behavioral and emotional states of students in measuring their engagement. We develop bag-of-words-based models in which only the occurrence of behavioral and emotional states of students is modeled and analyzed and not the order in which they occur. Behavioral and affective features are extracted from videos and analyzed by the proposed models to determine the level of engagement in an ordinal-output classification setting. Compared to the existing sequential and spatiotemporal approaches for engagement measurement, the proposed non-sequential approach improves the state-of-the-art results. According to experimental results, our method significantly improved engagement level classification accuracy on the IIITB Online SE dataset by 26% compared to sequential models and achieved engagement level classification accuracy as high as 66.58% on the DAiSEE student engagement dataset.
One-shot domain adaptation for semantic face editing of real world images using StyleALAE
Aug 31, 2021

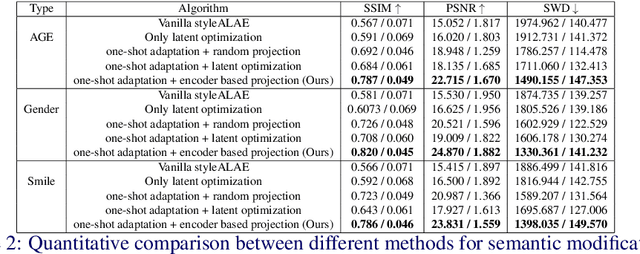

Semantic face editing of real world facial images is an important application of generative models. Recently, multiple works have explored possible techniques to generate such modifications using the latent structure of pre-trained GAN models. However, such approaches often require training an encoder network and that is typically a time-consuming and resource intensive process. A possible alternative to such a GAN-based architecture can be styleALAE, a latent-space based autoencoder that can generate photo-realistic images of high quality. Unfortunately, the reconstructed image in styleALAE does not preserve the identity of the input facial image. This limits the application of styleALAE for semantic face editing of images with known identities. In our work, we use a recent advancement in one-shot domain adaptation to address this problem. Our work ensures that the identity of the reconstructed image is the same as the given input image. We further generate semantic modifications over the reconstructed image by using the latent space of the pre-trained styleALAE model. Results show that our approach can generate semantic modifications on any real world facial image while preserving the identity.
Learning a Deep Reinforcement Learning Policy Over the Latent Space of a Pre-trained GAN for Semantic Age Manipulation
Nov 02, 2020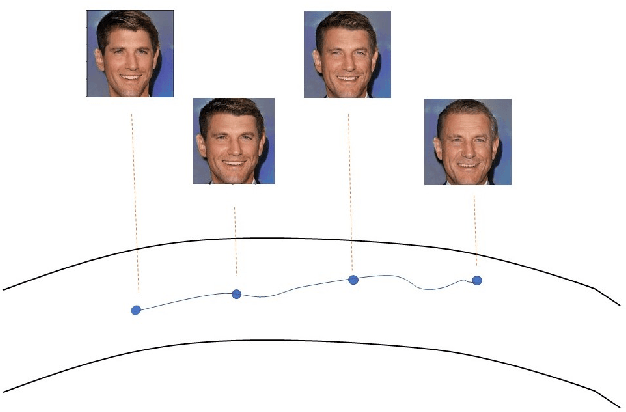


Learning a disentangled representation of the latent space has become one of the most fundamental problems studied in computer vision. Recently, many generative adversarial networks (GANs) have shown promising results in generating high fidelity images. However, studies to understand the semantic layout of the latent space of pre-trained models are still limited. Several works train conditional GANs to generate faces with required semantic attributes. Unfortunately, in these attempts often the generated output is not as photo-realistic as the state of the art models. Besides, they also require large computational resources and specific datasets to generate high fidelity images. In our work, we have formulated a Markov Decision Process (MDP) over the rich latent space of a pre-trained GAN model to learn a conditional policy for semantic manipulation along specific attributes under defined identity bounds. Further, we have defined a semantic age manipulation scheme using a locally linear approximation over the latent space. Results show that our learned policy can sample high fidelity images with required age variations, while at the same time preserve the identity of the person.
A Robust Lane Detection and Departure Warning System
Apr 28, 2015
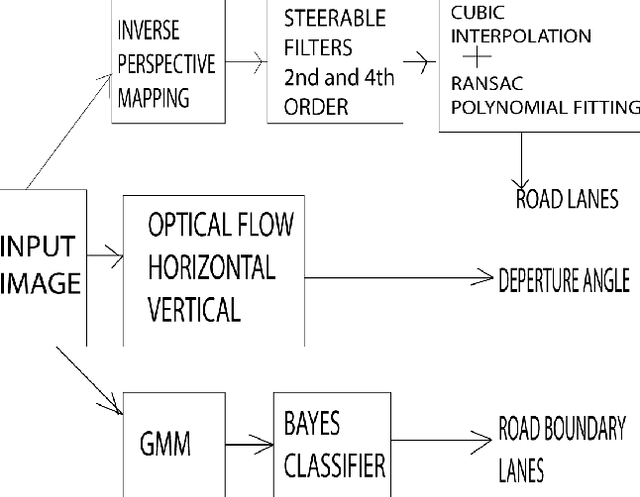
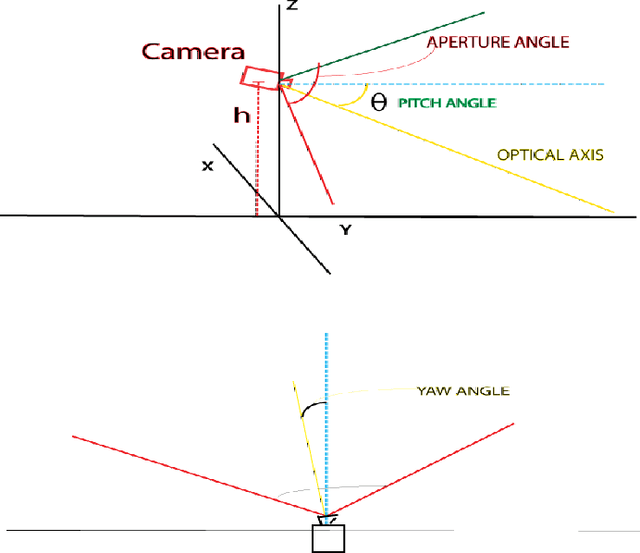
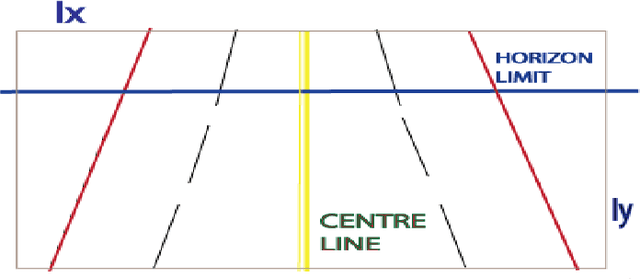
In this work, we have developed a robust lane detection and departure warning technique. Our system is based on single camera sensor. For lane detection a modified Inverse Perspective Mapping using only a few extrinsic camera parameters and illuminant Invariant techniques is used. Lane markings are represented using a combination of 2nd and 4th order steerable filters, robust to shadowing. Effect of shadowing and extra sun light are removed using Lab color space, and illuminant invariant representation. Lanes are assumed to be cubic curves and fitted using robust RANSAC. This method can reliably detect lanes of the road and its boundary. This method has been experimented in Indian road conditions under different challenging situations and the result obtained were very good. For lane departure angle an optical flow based method were used.
Vehicle Local Position Estimation System
Mar 23, 2015
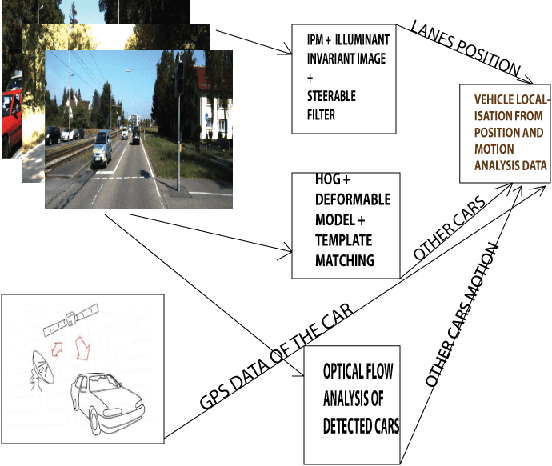
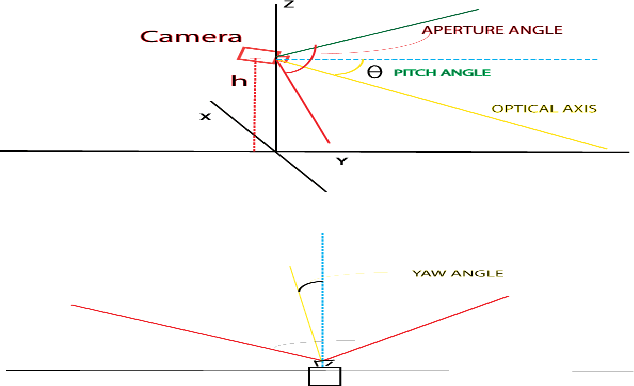
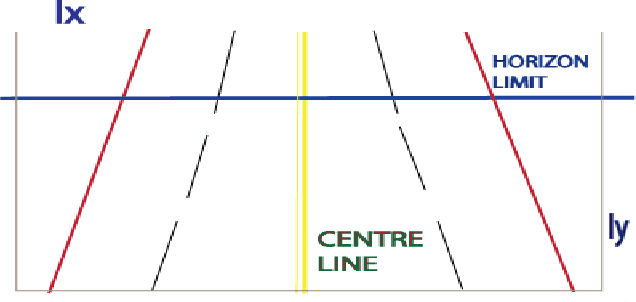
In this paper, a robust vehicle local position estimation with the help of single camera sensor and GPS is presented. A modified Inverse Perspective Mapping, illuminant Invariant techniques and object detection based approach is used to localize the vehicle in the road. Vehicles current lane, its position from road boundary and other cars are used to define its local position. For this purpose Lane markings are detected using a Laplacian edge feature, robust to shadowing. Effect of shadowing and extra sun light are removed using Lab color space and illuminant invariant techniques. Lanes are assumed to be as parabolic model and fitted using robust RANSAC. This method can reliably detect all lanes of the road, estimate lane departure angle and local position of vehicle relative to lanes, road boundary and other cars. Different type of obstacle like pedestrians, vehicles are detected using HOG feature based deformable part model.