 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision-Language Models Solve Visual Math Equations?
Sep 10, 2025Despite strong performance in visual understanding and language-based reasoning, Vision-Language Models (VLMs) struggle with tasks requiring integrated perception and symbolic computation. We study this limitation through visual equation solving, where mathematical equations are embedded in images, variables are represented by object icons, and coefficients must be inferred by counting. While VLMs perform well on textual equations, they fail on visually grounded counterparts. To understand this gap, we decompose the task into coefficient counting and variable recognition, and find that counting is the primary bottleneck, even when recognition is accurate. We also observe that composing recognition and reasoning introduces additional errors, highlighting challenges in multi-step visual reasoning. Finally, as equation complexity increases, symbolic reasoning itself becomes a limiting factor. These findings reveal key weaknesses in current VLMs and point toward future improvements in visually grounded mathematical reasoning.
* Monjoy Narayan Choudhury and Junling Wang contributed equally to this work. Accepted at EMNLP2025 main. Code and datasets are open-sourced with links in the paper
CASE: Curricular Data Pre-training for Building Generative and Discriminative Assistive Psychology Expert Models
Jun 01, 2024The limited availability of psychologists necessitates efficient identification of individuals requiring urgent mental healthcare. This study explores the use of Natural Language Processing (NLP) pipelines to analyze text data from online mental health forums used for consultations. By analyzing forum posts, these pipelines can flag users who may require immediate professional attention. A crucial challenge in this domain is data privacy and scarcity. To address this, we propose utilizing readily available curricular texts used in institutes specializing in mental health for pre-training the NLP pipelines. This helps us mimic the training process of a psychologist. Our work presents two models: a discriminative BERT-based model called CASE-BERT that flags potential mental health disorders based on forum text, and a generative model called CASE-Gemma that extracts key features for a preliminary diagnosis. CASE-BERT demonstrates superior performance compared to existing methods, achieving an f1 score of 0.91 for Depression and 0.88 for Anxiety, two of the most commonly reported mental health disorders. CASE-Gemma can achieve a BERT Score of 0.849 on generating diagnoses based on forum text. The effectiveness of CASE-Gemma is evaluated through both human evaluation and qualitative methods, with the collaboration of clinical psychologists who provide us with a set of annotated data for fine-tuning and evaluation. Our code is available at https://github.com/sarthakharne/CASE
RID-TWIN: An end-to-end pipeline for automatic face de-identification in videos
Mar 15, 2024
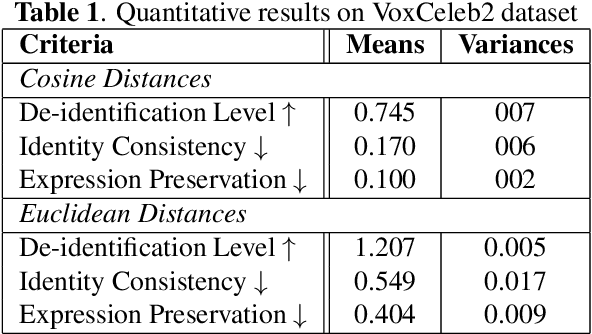
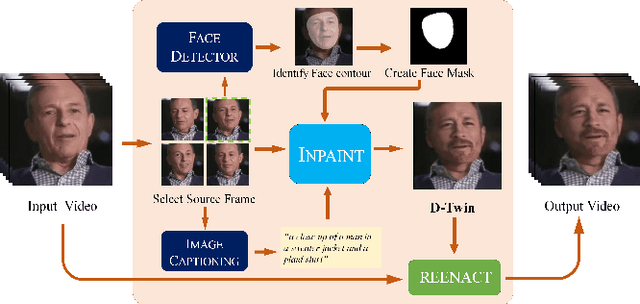
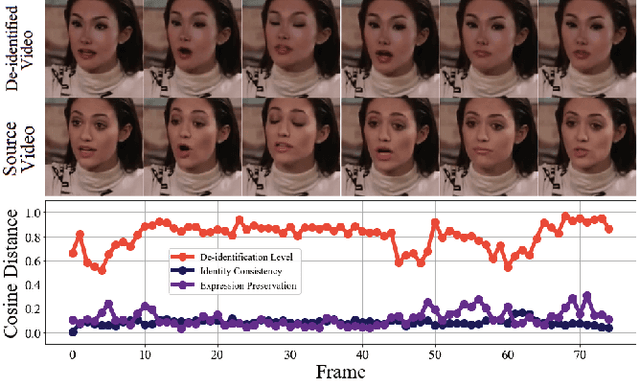
Face de-identification in videos is a challenging task in the domain of computer vision, primarily used in privacy-preserving applications. Despite the considerable progress achieved through generative vision models, there remain multiple challenges in the latest approaches. They lack a comprehensive discussion and evaluation of aspects such as realism, temporal coherence, and preservation of non-identifiable features. In our work, we propose RID-Twin: a novel pipeline that leverages the state-of-the-art generative models, and decouples identity from motion to perform automatic face de-identification in videos. We investigate the task from a holistic point of view and discuss how our approach addresses the pertinent existing challenges in this domain. We evaluate the performance of our methodology on the widely employed VoxCeleb2 dataset, and also a custom dataset designed to accommodate the limitations of certain behavioral variations absent in the VoxCeleb2 dataset. We discuss the implications and advantages of our work and suggest directions for future research.