 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRID-TWIN: An end-to-end pipeline for automatic face de-identification in videos
Paper and Code

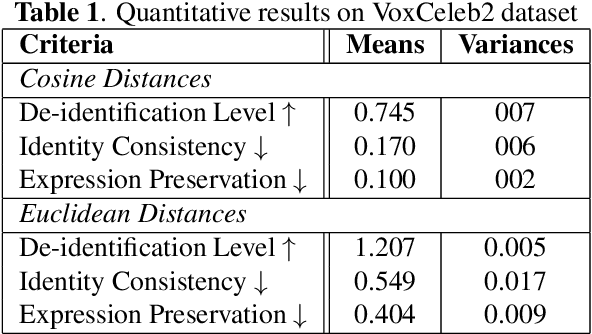
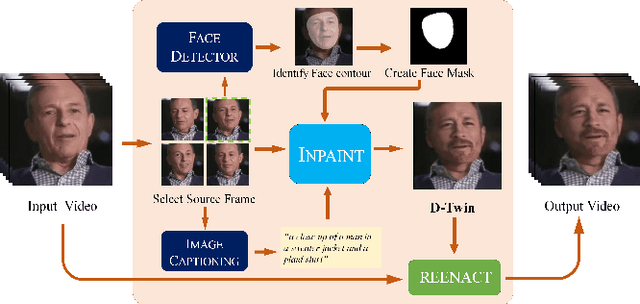
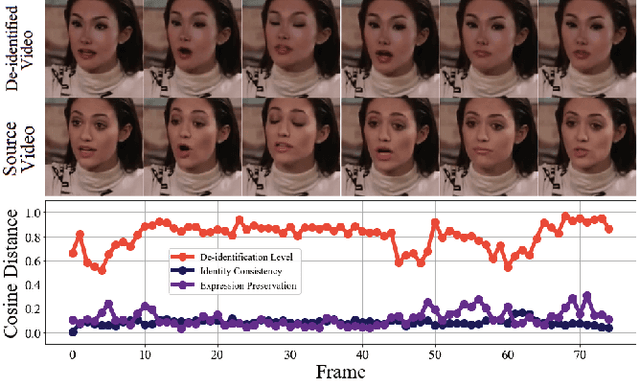
Face de-identification in videos is a challenging task in the domain of computer vision, primarily used in privacy-preserving applications. Despite the considerable progress achieved through generative vision models, there remain multiple challenges in the latest approaches. They lack a comprehensive discussion and evaluation of aspects such as realism, temporal coherence, and preservation of non-identifiable features. In our work, we propose RID-Twin: a novel pipeline that leverages the state-of-the-art generative models, and decouples identity from motion to perform automatic face de-identification in videos. We investigate the task from a holistic point of view and discuss how our approach addresses the pertinent existing challenges in this domain. We evaluate the performance of our methodology on the widely employed VoxCeleb2 dataset, and also a custom dataset designed to accommodate the limitations of certain behavioral variations absent in the VoxCeleb2 dataset. We discuss the implications and advantages of our work and suggest directions for future research.