 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI based approach to Trailer Generation for Online Educational Courses
Jan 10, 2023



In this paper, we propose an AI based approach to Trailer Generation in the form of short videos for online educational courses. Trailers give an overview of the course to the learners and help them make an informed choice about the courses they want to learn. It also helps to generate curiosity and interest among the learners and encourages them to pursue a course. While it is possible to manually generate the trailers, it requires extensive human efforts and skills over a broad spectrum of design, span selection, video editing, domain knowledge, etc., thus making it time-consuming and expensive, especially in an academic setting. The framework we propose in this work is a template based method for video trailer generation, where most of the textual content of the trailer is auto-generated and the trailer video is automatically generated, by leveraging Machine Learning and Natural Language Processing techniques. The proposed trailer is in the form of a timeline consisting of various fragments created by selecting, para-phrasing or generating content using various proposed techniques. The fragments are further enhanced by adding voice-over text, subtitles, animations, etc., to create a holistic experience. Finally, we perform user evaluation with 63 human evaluators for evaluating the trailers generated by our system and the results obtained were encouraging.
Why Settle for Just One? Extending EL++ Ontology Embeddings with Many-to-Many Relationships
Oct 20, 2021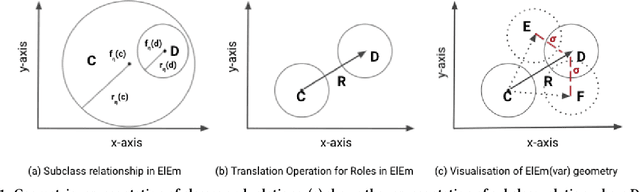
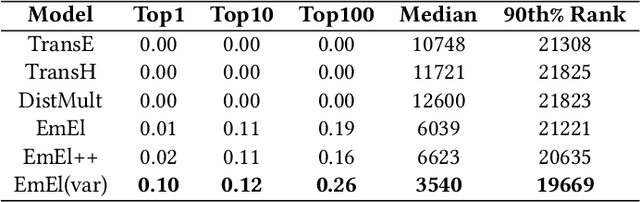
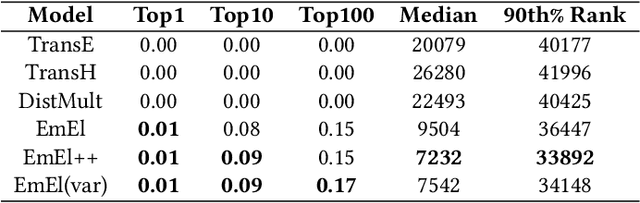
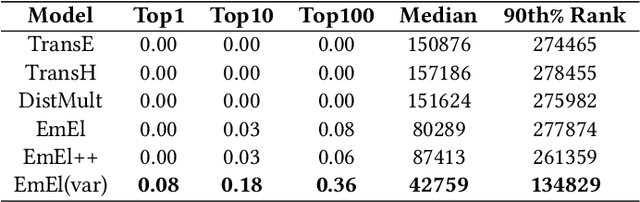
Knowledge Graph (KG) embeddings provide a low-dimensional representation of entities and relations of a Knowledge Graph and are used successfully for various applications such as question answering and search, reasoning, inference, and missing link prediction. However, most of the existing KG embeddings only consider the network structure of the graph and ignore the semantics and the characteristics of the underlying ontology that provides crucial information about relationships between entities in the KG. Recent efforts in this direction involve learning embeddings for a Description Logic (logical underpinning for ontologies) named EL++. However, such methods consider all the relations defined in the ontology to be one-to-one which severely limits their performance and applications. We provide a simple and effective solution to overcome this shortcoming that allows such methods to consider many-to-many relationships while learning embedding representations. Experiments conducted using three different EL++ ontologies show substantial performance improvement over five baselines. Our proposed solution also paves the way for learning embedding representations for even more expressive description logics such as SROIQ.
Unsupervised Contextual Paraphrase Generation using Lexical Control and Reinforcement Learning
Mar 23, 2021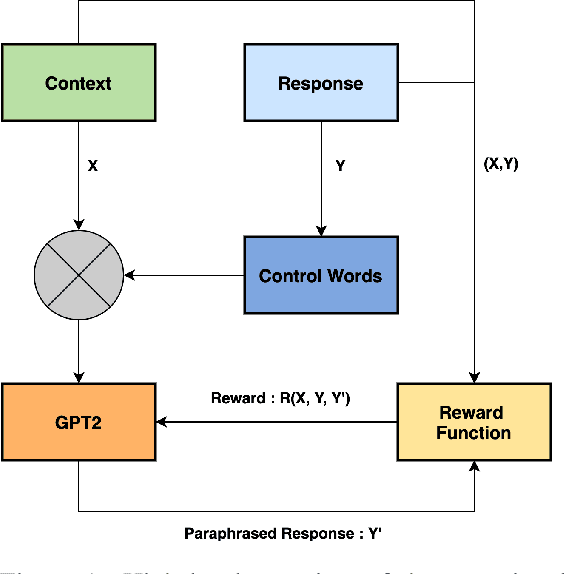



Customer support via chat requires agents to resolve customer queries with minimum wait time and maximum customer satisfaction. Given that the agents as well as the customers can have varying levels of literacy, the overall quality of responses provided by the agents tend to be poor if they are not predefined. But using only static responses can lead to customer detraction as the customers tend to feel that they are no longer interacting with a human. Hence, it is vital to have variations of the static responses to reduce monotonicity of the responses. However, maintaining a list of such variations can be expensive. Given the conversation context and the agent response, we propose an unsupervised frame-work to generate contextual paraphrases using autoregressive models. We also propose an automated metric based on Semantic Similarity, Textual Entailment, Expression Diversity and Fluency to evaluate the quality of contextual paraphrases and demonstrate performance improvement with Reinforcement Learning (RL) fine-tuning using the automated metric as the reward function.
Learning a Deep Reinforcement Learning Policy Over the Latent Space of a Pre-trained GAN for Semantic Age Manipulation
Nov 02, 2020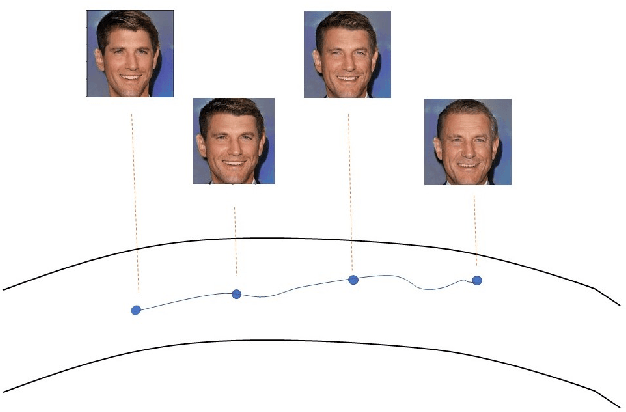


Learning a disentangled representation of the latent space has become one of the most fundamental problems studied in computer vision. Recently, many generative adversarial networks (GANs) have shown promising results in generating high fidelity images. However, studies to understand the semantic layout of the latent space of pre-trained models are still limited. Several works train conditional GANs to generate faces with required semantic attributes. Unfortunately, in these attempts often the generated output is not as photo-realistic as the state of the art models. Besides, they also require large computational resources and specific datasets to generate high fidelity images. In our work, we have formulated a Markov Decision Process (MDP) over the rich latent space of a pre-trained GAN model to learn a conditional policy for semantic manipulation along specific attributes under defined identity bounds. Further, we have defined a semantic age manipulation scheme using a locally linear approximation over the latent space. Results show that our learned policy can sample high fidelity images with required age variations, while at the same time preserve the identity of the person.
Human Trajectory Prediction using Spatially aware Deep Attention Models
May 26, 2017
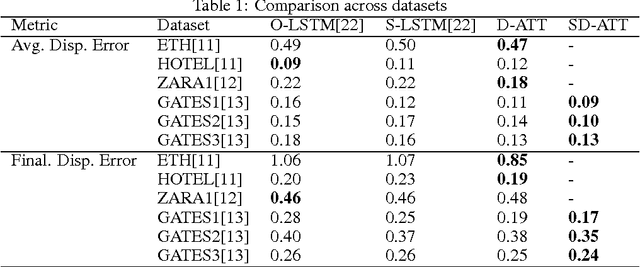


Trajectory Prediction of dynamic objects is a widely studied topic in the field of artificial intelligence. Thanks to a large number of applications like predicting abnormal events, navigation system for the blind, etc. there have been many approaches to attempt learning patterns of motion directly from data using a wide variety of techniques ranging from hand-crafted features to sophisticated deep learning models for unsupervised feature learning. All these approaches have been limited by problems like inefficient features in the case of hand crafted features, large error propagation across the predicted trajectory and no information of static artefacts around the dynamic moving objects. We propose an end to end deep learning model to learn the motion patterns of humans using different navigational modes directly from data using the much popular sequence to sequence model coupled with a soft attention mechanism. We also propose a novel approach to model the static artefacts in a scene and using these to predict the dynamic trajectories. The proposed method, tested on trajectories of pedestrians, consistently outperforms previously proposed state of the art approaches on a variety of large scale data sets. We also show how our architecture can be naturally extended to handle multiple modes of movement (say pedestrians, skaters, bikers and buses) simultaneously.