 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot domain adaptation for semantic face editing of real world images using StyleALAE
Aug 31, 2021

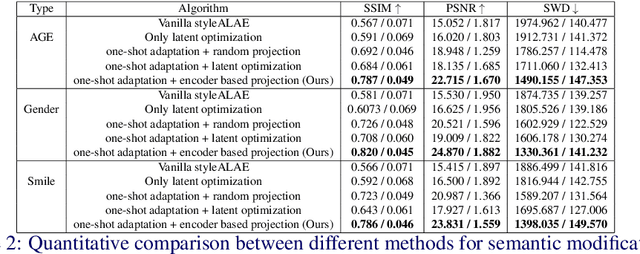

Semantic face editing of real world facial images is an important application of generative models. Recently, multiple works have explored possible techniques to generate such modifications using the latent structure of pre-trained GAN models. However, such approaches often require training an encoder network and that is typically a time-consuming and resource intensive process. A possible alternative to such a GAN-based architecture can be styleALAE, a latent-space based autoencoder that can generate photo-realistic images of high quality. Unfortunately, the reconstructed image in styleALAE does not preserve the identity of the input facial image. This limits the application of styleALAE for semantic face editing of images with known identities. In our work, we use a recent advancement in one-shot domain adaptation to address this problem. Our work ensures that the identity of the reconstructed image is the same as the given input image. We further generate semantic modifications over the reconstructed image by using the latent space of the pre-trained styleALAE model. Results show that our approach can generate semantic modifications on any real world facial image while preserving the identity.
Introducing various Semantic Models for Amharic: Experimentation and Evaluation with multiple Tasks and Datasets
Nov 02, 2020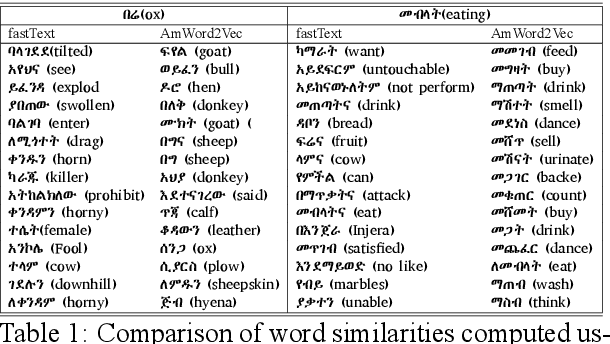
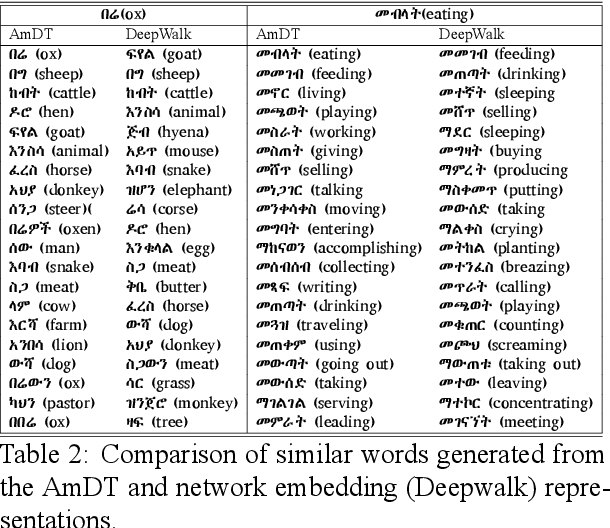
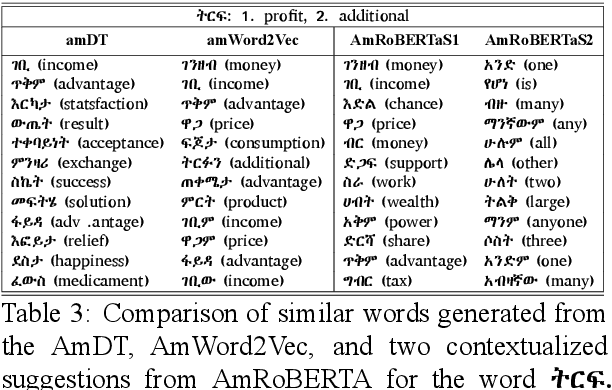
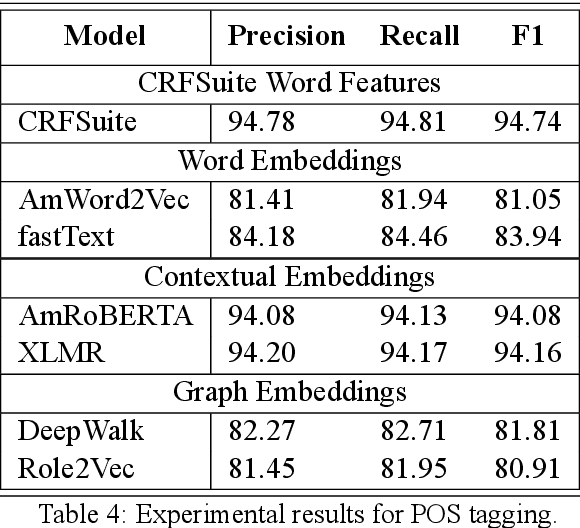
The availability of different pre-trained semantic models enabled the quick development of machine learning components for downstream applications. Despite the availability of abundant text data for low resource languages, only a few semantic models are publicly available. Publicly available pre-trained models are usually built as a multilingual version of semantic models that can not fit well for each language due to context variations. In this work, we introduce different semantic models for Amharic. After we experiment with the existing pre-trained semantic models, we trained and fine-tuned nine new different models using a monolingual text corpus. The models are build using word2Vec embeddings, distributional thesaurus (DT), contextual embeddings, and DT embeddings obtained via network embedding algorithms. Moreover, we employ these models for different NLP tasks and investigate their impact. We find that newly trained models perform better than pre-trained multilingual models. Furthermore, models based on contextual embeddings from RoBERTA perform better than the word2Vec models.
Learning a Deep Reinforcement Learning Policy Over the Latent Space of a Pre-trained GAN for Semantic Age Manipulation
Nov 02, 2020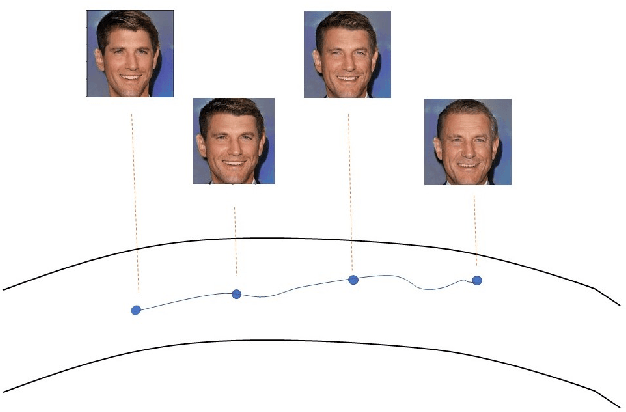


Learning a disentangled representation of the latent space has become one of the most fundamental problems studied in computer vision. Recently, many generative adversarial networks (GANs) have shown promising results in generating high fidelity images. However, studies to understand the semantic layout of the latent space of pre-trained models are still limited. Several works train conditional GANs to generate faces with required semantic attributes. Unfortunately, in these attempts often the generated output is not as photo-realistic as the state of the art models. Besides, they also require large computational resources and specific datasets to generate high fidelity images. In our work, we have formulated a Markov Decision Process (MDP) over the rich latent space of a pre-trained GAN model to learn a conditional policy for semantic manipulation along specific attributes under defined identity bounds. Further, we have defined a semantic age manipulation scheme using a locally linear approximation over the latent space. Results show that our learned policy can sample high fidelity images with required age variations, while at the same time preserve the identity of the person.
Automatic Compilation of Resources for Academic Writing and Evaluating with Informal Word Identification and Paraphrasing System
Mar 05, 2020
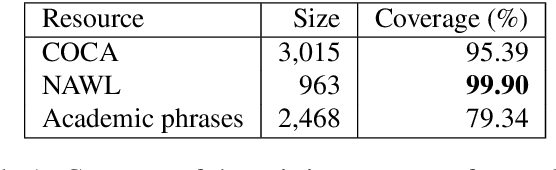
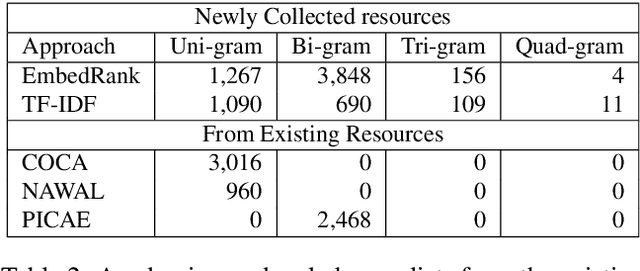
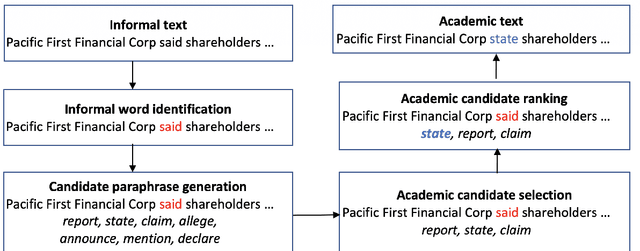
We present the first approach to automatically building resources for academic writing. The aim is to build a writing aid system that automatically edits a text so that it better adheres to the academic style of writing. On top of existing academic resources, such as the Corpus of Contemporary American English (COCA) academic Word List, the New Academic Word List, and the Academic Collocation List, we also explore how to dynamically build such resources that would be used to automatically identify informal or non-academic words or phrases. The resources are compiled using different generic approaches that can be extended for different domains and languages. We describe the evaluation of resources with a system implementation. The system consists of an informal word identification (IWI), academic candidate paraphrase generation, and paraphrase ranking components. To generate candidates and rank them in context, we have used the PPDB and WordNet paraphrase resources. We use the Concepts in Context (CoInCO) "All-Words" lexical substitution dataset both for the informal word identification and paraphrase generation experiments. Our informal word identification component achieves an F-1 score of 82%, significantly outperforming a stratified classifier baseline. The main contribution of this work is a domain-independent methodology to build targeted resources for writing aids.