 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Data Symmetries to Select an Optimal Subset of Training Data under Label Noise
May 03, 2026The performance of machine learning models often relies on large labeled datasets; however, data collected from diverse sources can contain label noise. Recent work has shown that, in noisy settings, there may exist a subset of the training data on which models can achieve performance comparable to training on a noise-free dataset. A widely used method for identifying such subsets is cutstats, which employs k-nearest neighbors (k-NN) to detect low-noise samples. However, its performance on high-dimensional data remains largely unexplored. In this work, we formally establish that the performance of a classifier trained on a subset of a noisy dataset selected via cutstats is influenced by the accuracy of k-NN. We further demonstrate that, in noisy environments, exploiting data invariance and knowledge of underlying symmetries can significantly enhance the performance of k-NN, bringing it closer to the Bayes optimal classifier even in high-dimensional regimes. Finally, we show that for real-world scenarios, where information about the underlying invariance is only partially known, learnt invariant representations can still facilitate the identification of near-optimal subsets.
From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents
Apr 21, 2026Personalized agents that interact with users over long periods must maintain persistent memory across sessions and update it as circumstances change. However, existing benchmarks predominantly frame long-term memory evaluation as fact retrieval from past conversations, providing limited insight into agents' ability to consolidate memory over time or handle frequent knowledge updates. We introduce Memora, a long-term memory benchmark spanning weeks to months long user conversations. The benchmark evaluates three memory-grounded tasks: remembering, reasoning, and recommending. To ensure data quality, we employ automated memory-grounding checks and human evaluation. We further introduce Forgetting-Aware Memory Accuracy (FAMA), a metric that penalizes reliance on obsolete or invalidated memory when evaluating long-term memory. Evaluations of four LLMs and six memory agents reveal frequent reuse of invalid memories and failures to reconcile evolving memories. Memory agents offer marginal improvements, exposing shortcomings in long-term memory for personalized agents.
WISER: Weak supervISion and supErvised Representation learning to improve drug response prediction in cancer
May 07, 2024Cancer, a leading cause of death globally, occurs due to genomic changes and manifests heterogeneously across patients. To advance research on personalized treatment strategies, the effectiveness of various drugs on cells derived from cancers (`cell lines') is experimentally determined in laboratory settings. Nevertheless, variations in the distribution of genomic data and drug responses between cell lines and humans arise due to biological and environmental differences. Moreover, while genomic profiles of many cancer patients are readily available, the scarcity of corresponding drug response data limits the ability to train machine learning models that can predict drug response in patients effectively. Recent cancer drug response prediction methods have largely followed the paradigm of unsupervised domain-invariant representation learning followed by a downstream drug response classification step. Introducing supervision in both stages is challenging due to heterogeneous patient response to drugs and limited drug response data. This paper addresses these challenges through a novel representation learning method in the first phase and weak supervision in the second. Experimental results on real patient data demonstrate the efficacy of our method (WISER) over state-of-the-art alternatives on predicting personalized drug response.
Fusing Conditional Submodular GAN and Programmatic Weak Supervision
Dec 16, 2023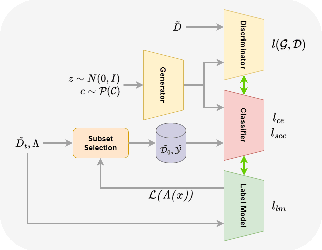
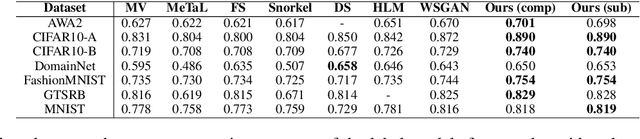
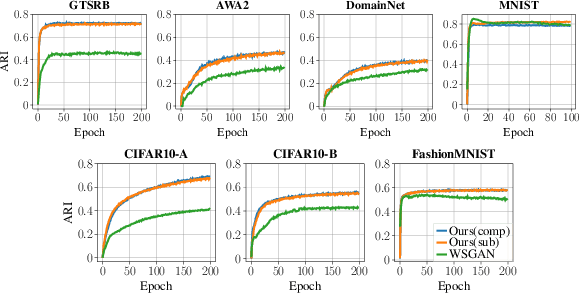
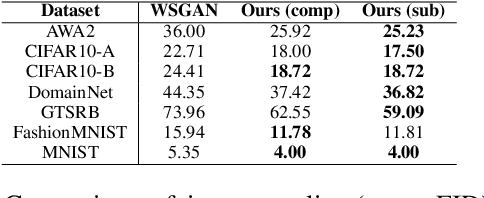
Programmatic Weak Supervision (PWS) and generative models serve as crucial tools that enable researchers to maximize the utility of existing datasets without resorting to laborious data gathering and manual annotation processes. PWS uses various weak supervision techniques to estimate the underlying class labels of data, while generative models primarily concentrate on sampling from the underlying distribution of the given dataset. Although these methods have the potential to complement each other, they have mostly been studied independently. Recently, WSGAN proposed a mechanism to fuse these two models. Their approach utilizes the discrete latent factors of InfoGAN to train the label model and leverages the class-dependent information of the label model to generate images of specific classes. However, the disentangled latent factors learned by InfoGAN might not necessarily be class-specific and could potentially affect the label model's accuracy. Moreover, prediction made by the label model is often noisy in nature and can have a detrimental impact on the quality of images generated by GAN. In our work, we address these challenges by (i) implementing a noise-aware classifier using the pseudo labels generated by the label model (ii) utilizing the noise-aware classifier's prediction to train the label model and generate class-conditional images. Additionally, we also investigate the effect of training the classifier with a subset of the dataset within a defined uncertainty budget on pseudo labels. We accomplish this by formalizing the subset selection problem as a submodular maximization objective with a knapsack constraint on the entropy of pseudo labels. We conduct experiments on multiple datasets and demonstrate the efficacy of our methods on several tasks vis-a-vis the current state-of-the-art methods.
Constructing Bayesian Pseudo-Coresets using Contrastive Divergence
Mar 20, 2023



Bayesian Pseudo-Coreset (BPC) and Dataset Condensation are two parallel streams of work that construct a synthetic set such that, a model trained independently on this synthetic set, yields the same performance as training on the original training set. While dataset condensation methods use non-bayesian, heuristic ways to construct such a synthetic set, BPC methods take a bayesian approach and formulate the problem as divergence minimization between posteriors associated with original data and synthetic data. However, BPC methods generally rely on distributional assumptions on these posteriors which makes them less flexible and hinders their performance. In this work, we propose to solve these issues by modeling the posterior associated with synthetic data by an energy-based distribution. We derive a contrastive-divergence-like loss function to learn the synthetic set and show a simple and efficient way to estimate this loss. Further, we perform rigorous experiments pertaining to the proposed method. Our experiments on multiple datasets show that the proposed method not only outperforms previous BPC methods but also gives performance comparable to dataset condensation counterparts.
One-shot domain adaptation for semantic face editing of real world images using StyleALAE
Aug 31, 2021

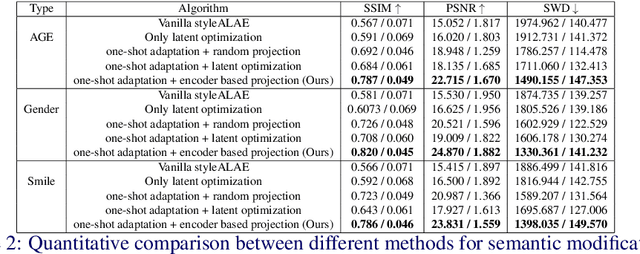

Semantic face editing of real world facial images is an important application of generative models. Recently, multiple works have explored possible techniques to generate such modifications using the latent structure of pre-trained GAN models. However, such approaches often require training an encoder network and that is typically a time-consuming and resource intensive process. A possible alternative to such a GAN-based architecture can be styleALAE, a latent-space based autoencoder that can generate photo-realistic images of high quality. Unfortunately, the reconstructed image in styleALAE does not preserve the identity of the input facial image. This limits the application of styleALAE for semantic face editing of images with known identities. In our work, we use a recent advancement in one-shot domain adaptation to address this problem. Our work ensures that the identity of the reconstructed image is the same as the given input image. We further generate semantic modifications over the reconstructed image by using the latent space of the pre-trained styleALAE model. Results show that our approach can generate semantic modifications on any real world facial image while preserving the identity.
Weakly-Supervised Classification and Detection of Bird Sounds in the Wild. A BirdCLEF 2021 Solution
Jul 10, 2021
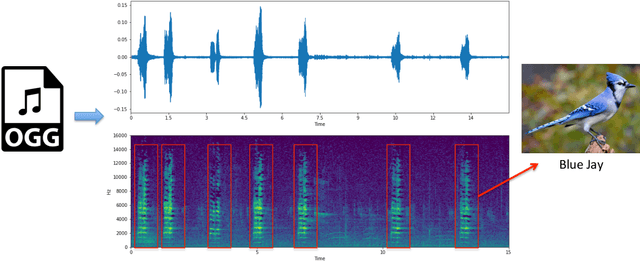
It is easier to hear birds than see them, however, they still play an essential role in nature and they are excellent indicators of deteriorating environmental quality and pollution. Recent advances in Machine Learning and Convolutional Neural Networks allow us to detect and classify bird sounds, by doing this, we can assist researchers in monitoring the status and trends of bird populations and biodiversity in ecosystems. We propose a sound detection and classification pipeline for analyzing complex soundscape recordings and identify birdcalls in the background. Our pipeline learns from weak labels, classifies fine-grained bird vocalizations in the wild, and is robust against background sounds (e.g., airplanes, rain, etc). Our solution achieved 10th place of 816 teams at the BirdCLEF 2021 Challenge hosted on Kaggle.
Learning a Deep Reinforcement Learning Policy Over the Latent Space of a Pre-trained GAN for Semantic Age Manipulation
Nov 02, 2020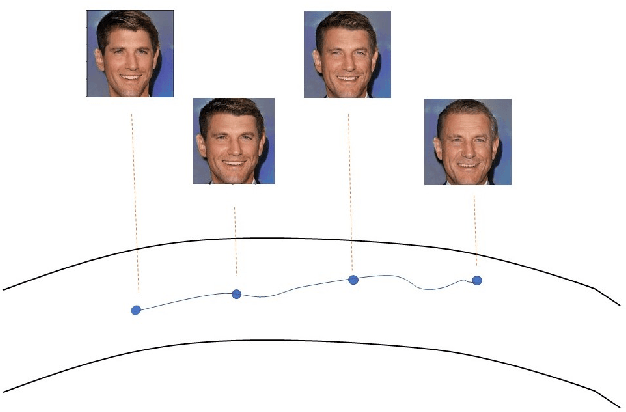


Learning a disentangled representation of the latent space has become one of the most fundamental problems studied in computer vision. Recently, many generative adversarial networks (GANs) have shown promising results in generating high fidelity images. However, studies to understand the semantic layout of the latent space of pre-trained models are still limited. Several works train conditional GANs to generate faces with required semantic attributes. Unfortunately, in these attempts often the generated output is not as photo-realistic as the state of the art models. Besides, they also require large computational resources and specific datasets to generate high fidelity images. In our work, we have formulated a Markov Decision Process (MDP) over the rich latent space of a pre-trained GAN model to learn a conditional policy for semantic manipulation along specific attributes under defined identity bounds. Further, we have defined a semantic age manipulation scheme using a locally linear approximation over the latent space. Results show that our learned policy can sample high fidelity images with required age variations, while at the same time preserve the identity of the person.