 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangDAug: Langevin Data Augmentation for Multi-Source Domain Generalization in Medical Image Segmentation
May 26, 2025Medical image segmentation models often struggle to generalize across different domains due to various reasons. Domain Generalization (DG) methods overcome this either through representation learning or data augmentation (DAug). While representation learning methods seek domain-invariant features, they often rely on ad-hoc techniques and lack formal guarantees. DAug methods, which enrich model representations through synthetic samples, have shown comparable or superior performance to representation learning approaches. We propose LangDAug, a novel $\textbf{Lang}$evin $\textbf{D}$ata $\textbf{Aug}$mentation for multi-source domain generalization in 2D medical image segmentation. LangDAug leverages Energy-Based Models (EBMs) trained via contrastive divergence to traverse between source domains, generating intermediate samples through Langevin dynamics. Theoretical analysis shows that LangDAug induces a regularization effect, and for GLMs, it upper-bounds the Rademacher complexity by the intrinsic dimensionality of the data manifold. Through extensive experiments on Fundus segmentation and 2D MRI prostate segmentation benchmarks, we show that LangDAug outperforms state-of-the-art domain generalization methods and effectively complements existing domain-randomization approaches. The codebase for our method is available at https://github.com/backpropagator/LangDAug.
GOTHAM: Graph Class Incremental Learning Framework under Weak Supervision
Apr 07, 2025Graphs are growing rapidly, along with the number of distinct label categories associated with them. Applications like e-commerce, healthcare, recommendation systems, and various social media platforms are rapidly moving towards graph representation of data due to their ability to capture both structural and attribute information. One crucial task in graph analysis is node classification, where unlabeled nodes are categorized into predefined classes. In practice, novel classes appear incrementally sometimes with just a few labels (seen classes) or even without any labels (unseen classes), either because they are new or haven't been explored much. Traditional methods assume abundant labeled data for training, which isn't always feasible. We investigate a broader objective: \emph{Graph Class Incremental Learning under Weak Supervision (GCL)}, addressing this challenge by meta-training on base classes with limited labeled instances. During the incremental streams, novel classes can have few-shot or zero-shot representation. Our proposed framework GOTHAM efficiently accommodates these unlabeled nodes by finding the closest prototype representation, serving as class representatives in the attribute space. For Text-Attributed Graphs (TAGs), our framework additionally incorporates semantic information to enhance the representation. By employing teacher-student knowledge distillation to mitigate forgetting, GOTHAM achieves promising results across various tasks. Experiments on datasets such as Cora-ML, Amazon, and OBGN-Arxiv showcase the effectiveness of our approach in handling evolving graph data under limited supervision. The repository is available here: \href{https://github.com/adityashahane10/GOTHAM--Graph-based-Class-Incremental-Learning-Framework-under-Weak-Supervision}{\small \textcolor{blue}{Code}}
GraPE: A Generate-Plan-Edit Framework for Compositional T2I Synthesis
Dec 08, 2024
Text-to-image (T2I) generation has seen significant progress with diffusion models, enabling generation of photo-realistic images from text prompts. Despite this progress, existing methods still face challenges in following complex text prompts, especially those requiring compositional and multi-step reasoning. Given such complex instructions, SOTA models often make mistakes in faithfully modeling object attributes, and relationships among them. In this work, we present an alternate paradigm for T2I synthesis, decomposing the task of complex multi-step generation into three steps, (a) Generate: we first generate an image using existing diffusion models (b) Plan: we make use of Multi-Modal LLMs (MLLMs) to identify the mistakes in the generated image expressed in terms of individual objects and their properties, and produce a sequence of corrective steps required in the form of an edit-plan. (c) Edit: we make use of an existing text-guided image editing models to sequentially execute our edit-plan over the generated image to get the desired image which is faithful to the original instruction. Our approach derives its strength from the fact that it is modular in nature, is training free, and can be applied over any combination of image generation and editing models. As an added contribution, we also develop a model capable of compositional editing, which further helps improve the overall accuracy of our proposed approach. Our method flexibly trades inference time compute with performance on compositional text prompts. We perform extensive experimental evaluation across 3 benchmarks and 10 T2I models including DALLE-3 and the latest -- SD-3.5-Large. Our approach not only improves the performance of the SOTA models, by upto 3 points, it also reduces the performance gap between weaker and stronger models. $\href{https://dair-iitd.github.io/GraPE/}{https://dair-iitd.github.io/GraPE/}$
Partially Blinded Unlearning: Class Unlearning for Deep Networks a Bayesian Perspective
Mar 24, 2024In order to adhere to regulatory standards governing individual data privacy and safety, machine learning models must systematically eliminate information derived from specific subsets of a user's training data that can no longer be utilized. The emerging discipline of Machine Unlearning has arisen as a pivotal area of research, facilitating the process of selectively discarding information designated to specific sets or classes of data from a pre-trained model, thereby eliminating the necessity for extensive retraining from scratch. The principal aim of this study is to formulate a methodology tailored for the purposeful elimination of information linked to a specific class of data from a pre-trained classification network. This intentional removal is crafted to degrade the model's performance specifically concerning the unlearned data class while concurrently minimizing any detrimental impacts on the model's performance in other classes. To achieve this goal, we frame the class unlearning problem from a Bayesian perspective, which yields a loss function that minimizes the log-likelihood associated with the unlearned data with a stability regularization in parameter space. This stability regularization incorporates Mohalanobis distance with respect to the Fisher Information matrix and $l_2$ distance from the pre-trained model parameters. Our novel approach, termed \textbf{Partially-Blinded Unlearning (PBU)}, surpasses existing state-of-the-art class unlearning methods, demonstrating superior effectiveness. Notably, PBU achieves this efficacy without requiring awareness of the entire training dataset but only to the unlearned data points, marking a distinctive feature of its performance.
Adapt then Unlearn: Exploiting Parameter Space Semantics for Unlearning in Generative Adversarial Networks
Sep 25, 2023The increased attention to regulating the outputs of deep generative models, driven by growing concerns about privacy and regulatory compliance, has highlighted the need for effective control over these models. This necessity arises from instances where generative models produce outputs containing undesirable, offensive, or potentially harmful content. To tackle this challenge, the concept of machine unlearning has emerged, aiming to forget specific learned information or to erase the influence of undesired data subsets from a trained model. The objective of this work is to prevent the generation of outputs containing undesired features from a pre-trained GAN where the underlying training data set is inaccessible. Our approach is inspired by a crucial observation: the parameter space of GANs exhibits meaningful directions that can be leveraged to suppress specific undesired features. However, such directions usually result in the degradation of the quality of generated samples. Our proposed method, known as 'Adapt-then-Unlearn,' excels at unlearning such undesirable features while also maintaining the quality of generated samples. This method unfolds in two stages: in the initial stage, we adapt the pre-trained GAN using negative samples provided by the user, while in the subsequent stage, we focus on unlearning the undesired feature. During the latter phase, we train the pre-trained GAN using positive samples, incorporating a repulsion regularizer. This regularizer encourages the model's parameters to be away from the parameters associated with the adapted model from the first stage while also maintaining the quality of generated samples. To the best of our knowledge, our approach stands as first method addressing unlearning in GANs. We validate the effectiveness of our method through comprehensive experiments.
A Unified Framework for Discovering Discrete Symmetries
Sep 06, 2023



We consider the problem of learning a function respecting a symmetry from among a class of symmetries. We develop a unified framework that enables symmetry discovery across a broad range of subgroups including locally symmetric, dihedral and cyclic subgroups. At the core of the framework is a novel architecture composed of linear and tensor-valued functions that expresses functions invariant to these subgroups in a principled manner. The structure of the architecture enables us to leverage multi-armed bandit algorithms and gradient descent to efficiently optimize over the linear and the tensor-valued functions, respectively, and to infer the symmetry that is ultimately learnt. We also discuss the necessity of the tensor-valued functions in the architecture. Experiments on image-digit sum and polynomial regression tasks demonstrate the effectiveness of our approach.
GenSelfDiff-HIS: Generative Self-Supervision Using Diffusion for Histopathological Image Segmentation
Sep 04, 2023Histopathological image segmentation is a laborious and time-intensive task, often requiring analysis from experienced pathologists for accurate examinations. To reduce this burden, supervised machine-learning approaches have been adopted using large-scale annotated datasets for histopathological image analysis. However, in several scenarios, the availability of large-scale annotated data is a bottleneck while training such models. Self-supervised learning (SSL) is an alternative paradigm that provides some respite by constructing models utilizing only the unannotated data which is often abundant. The basic idea of SSL is to train a network to perform one or many pseudo or pretext tasks on unannotated data and use it subsequently as the basis for a variety of downstream tasks. It is seen that the success of SSL depends critically on the considered pretext task. While there have been many efforts in designing pretext tasks for classification problems, there haven't been many attempts on SSL for histopathological segmentation. Motivated by this, we propose an SSL approach for segmenting histopathological images via generative diffusion models in this paper. Our method is based on the observation that diffusion models effectively solve an image-to-image translation task akin to a segmentation task. Hence, we propose generative diffusion as the pretext task for histopathological image segmentation. We also propose a multi-loss function-based fine-tuning for the downstream task. We validate our method using several metrics on two publically available datasets along with a newly proposed head and neck (HN) cancer dataset containing hematoxylin and eosin (H\&E) stained images along with annotations. Codes will be made public at https://github.com/PurmaVishnuVardhanReddy/GenSelfDiff-HIS.git.
Constructing Bayesian Pseudo-Coresets using Contrastive Divergence
Mar 20, 2023



Bayesian Pseudo-Coreset (BPC) and Dataset Condensation are two parallel streams of work that construct a synthetic set such that, a model trained independently on this synthetic set, yields the same performance as training on the original training set. While dataset condensation methods use non-bayesian, heuristic ways to construct such a synthetic set, BPC methods take a bayesian approach and formulate the problem as divergence minimization between posteriors associated with original data and synthetic data. However, BPC methods generally rely on distributional assumptions on these posteriors which makes them less flexible and hinders their performance. In this work, we propose to solve these issues by modeling the posterior associated with synthetic data by an energy-based distribution. We derive a contrastive-divergence-like loss function to learn the synthetic set and show a simple and efficient way to estimate this loss. Further, we perform rigorous experiments pertaining to the proposed method. Our experiments on multiple datasets show that the proposed method not only outperforms previous BPC methods but also gives performance comparable to dataset condensation counterparts.
Systematic Generalization in Neural Networks-based Multivariate Time Series Forecasting Models
Mar 07, 2021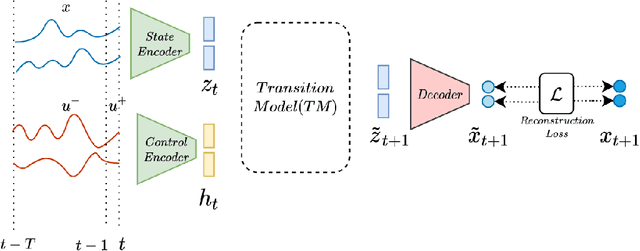
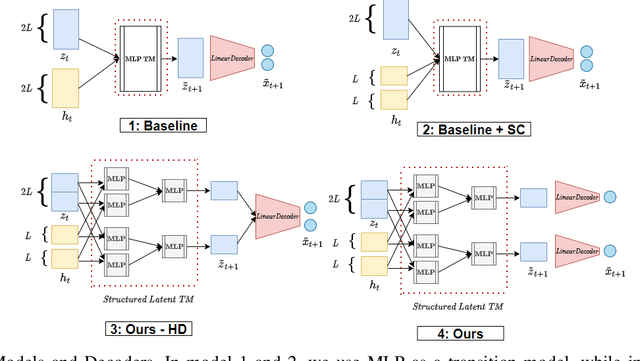
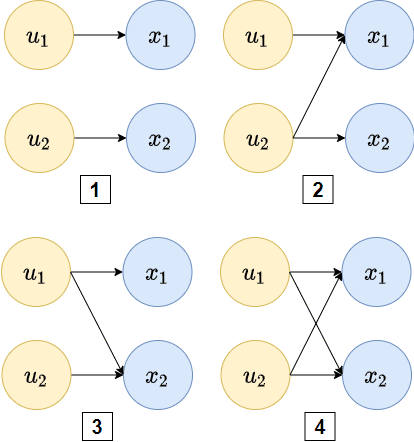
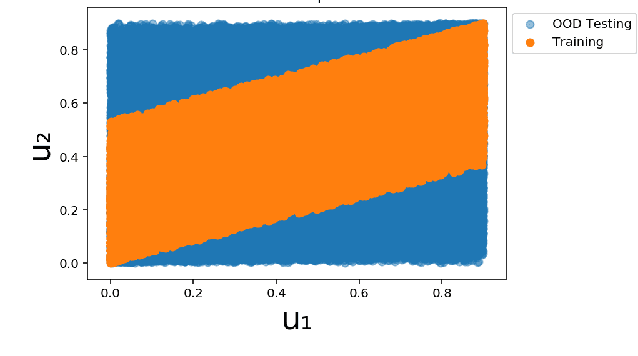
Systematic generalization aims to evaluate reasoning about novel combinations from known components, an intrinsic property of human cognition. In this work, we study systematic generalization of NNs in forecasting future time series of dependent variables in a dynamical system, conditioned on past time series of dependent variables, and past and future control variables. We focus on systematic generalization wherein the NN-based forecasting model should perform well on previously unseen combinations or regimes of control variables after being trained on a limited set of the possible regimes. For NNs to depict such out-of-distribution generalization, they should be able to disentangle the various dependencies between control variables and dependent variables. We hypothesize that a modular NN architecture guided by the readily-available knowledge of independence of control variables as a potentially useful inductive bias to this end. Through extensive empirical evaluation on a toy dataset and a simulated electric motor dataset, we show that our proposed modular NN architecture serves as a simple yet highly effective inductive bias that enabling better forecasting of the dependent variables up to large horizons in contrast to standard NNs, and indeed capture the true dependency relations between the dependent and the control variables.
RespVAD: Voice Activity Detection via Video-Extracted Respiration Patterns
Aug 21, 2020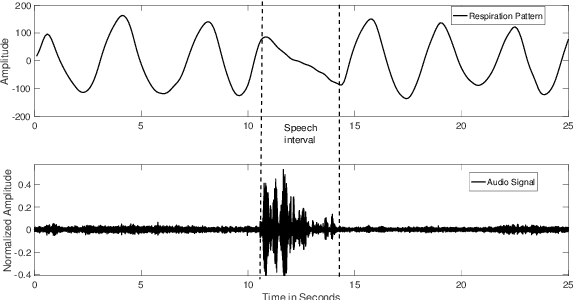

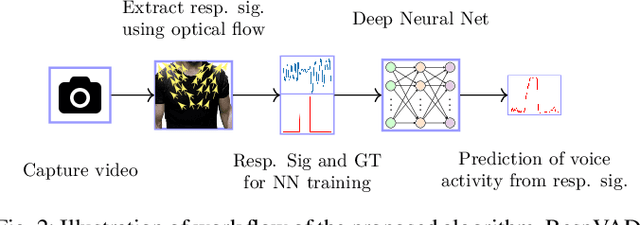

Voice Activity Detection (VAD) refers to the task of identification of regions of human speech in digital signals such as audio and video. While VAD is a necessary first step in many speech processing systems, it poses challenges when there are high levels of ambient noise during the audio recording. To improve the performance of VAD in such conditions, several methods utilizing the visual information extracted from the region surrounding the mouth/lip region of the speakers' video recording have been proposed. Even though these provide advantages over audio-only methods, they depend on faithful extraction of lip/mouth regions. Motivated by these, a new paradigm for VAD based on the fact that respiration forms the primary source of energy for speech production is proposed. Specifically, an audio-independent VAD technique using the respiration pattern extracted from the speakers' video is developed. The Respiration Pattern is first extracted from the video focusing on the abdominal-thoracic region of a speaker using an optical flow based method. Subsequently, voice activity is detected from the respiration pattern signal using neural sequence-to-sequence prediction models. The efficacy of the proposed method is demonstrated through experiments on a challenging dataset recorded in real acoustic environments and compared with four previous methods based on audio and visual cues.