 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROSS-JEM: Accurate and Efficient Cross-encoders for Short-text Ranking Tasks
Sep 15, 2024Ranking a set of items based on their relevance to a given query is a core problem in search and recommendation. Transformer-based ranking models are the state-of-the-art approaches for such tasks, but they score each query-item independently, ignoring the joint context of other relevant items. This leads to sub-optimal ranking accuracy and high computational costs. In response, we propose Cross-encoders with Joint Efficient Modeling (CROSS-JEM), a novel ranking approach that enables transformer-based models to jointly score multiple items for a query, maximizing parameter utilization. CROSS-JEM leverages (a) redundancies and token overlaps to jointly score multiple items, that are typically short-text phrases arising in search and recommendations, and (b) a novel training objective that models ranking probabilities. CROSS-JEM achieves state-of-the-art accuracy and over 4x lower ranking latency over standard cross-encoders. Our contributions are threefold: (i) we highlight the gap between the ranking application's need for scoring thousands of items per query and the limited capabilities of current cross-encoders; (ii) we introduce CROSS-JEM for joint efficient scoring of multiple items per query; and (iii) we demonstrate state-of-the-art accuracy on standard public datasets and a proprietary dataset. CROSS-JEM opens up new directions for designing tailored early-attention-based ranking models that incorporate strict production constraints such as item multiplicity and latency.
UniDEC : Unified Dual Encoder and Classifier Training for Extreme Multi-Label Classification
May 04, 2024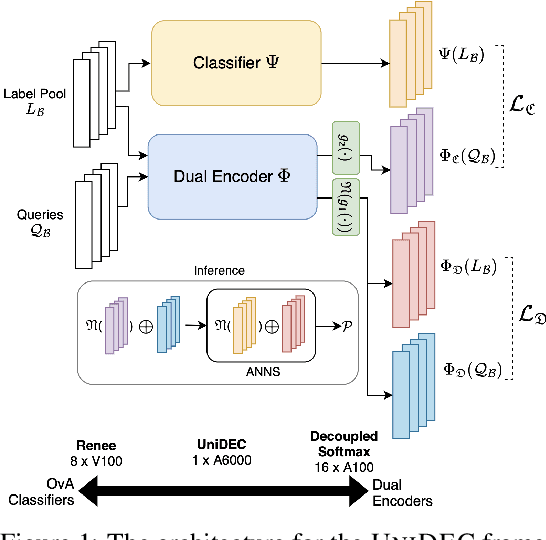
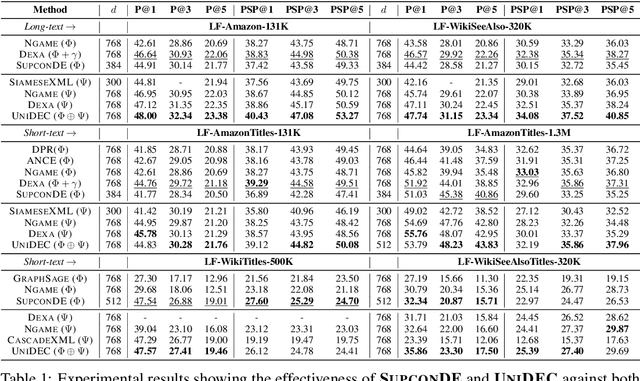
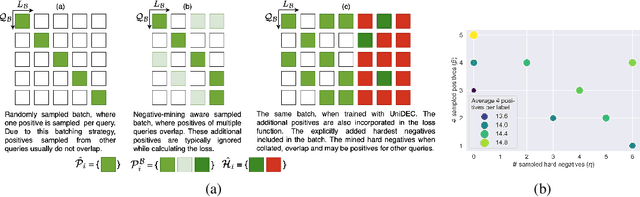
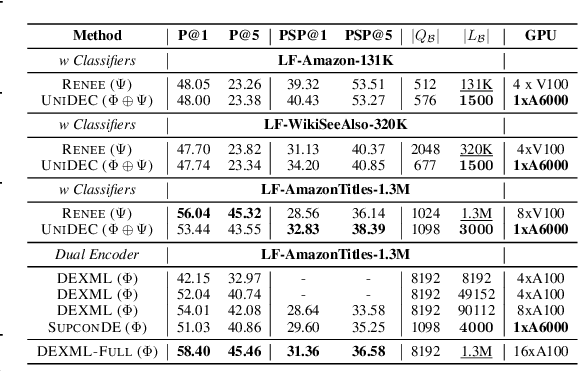
Extreme Multi-label Classification (XMC) involves predicting a subset of relevant labels from an extremely large label space, given an input query and labels with textual features. Models developed for this problem have conventionally used modular approach with (i) a Dual Encoder (DE) to embed the queries and label texts, (ii) a One-vs-All classifier to rerank the shortlisted labels mined through meta-classifier training. While such methods have shown empirical success, we observe two key uncharted aspects, (i) DE training typically uses only a single positive relation even for datasets which offer more, (ii) existing approaches fixate on using only OvA reduction of the multi-label problem. This work aims to explore these aspects by proposing UniDEC, a novel end-to-end trainable framework which trains the dual encoder and classifier in together in a unified fashion using a multi-class loss. For the choice of multi-class loss, the work proposes a novel pick-some-label (PSL) reduction of the multi-label problem with leverages multiple (in come cases, all) positives. The proposed framework achieves state-of-the-art results on a single GPU, while achieving on par results with respect to multi-GPU SOTA methods on various XML benchmark datasets, all while using 4-16x lesser compute and being practically scalable even beyond million label scale datasets.
Continual Learning for Multivariate Time Series Tasks with Variable Input Dimensions
Mar 14, 2022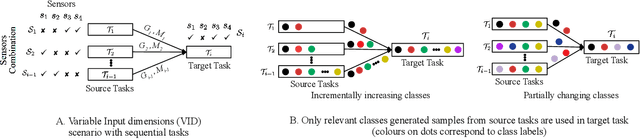
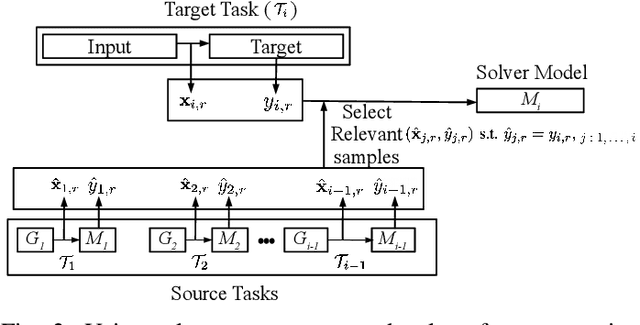
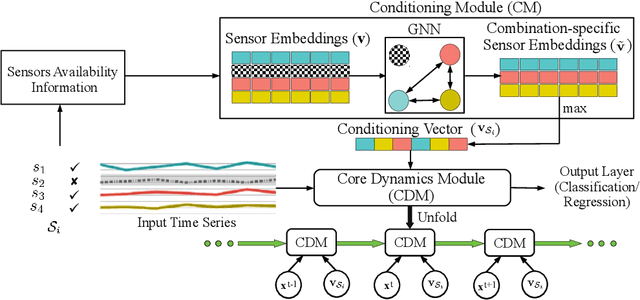
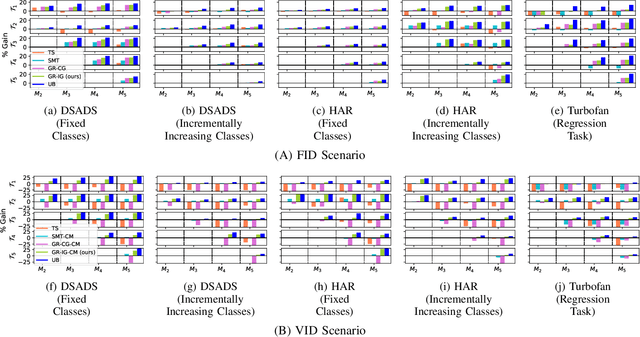
We consider a sequence of related multivariate time series learning tasks, such as predicting failures for different instances of a machine from time series of multi-sensor data, or activity recognition tasks over different individuals from multiple wearable sensors. We focus on two under-explored practical challenges arising in such settings: (i) Each task may have a different subset of sensors, i.e., providing different partial observations of the underlying 'system'. This restriction can be due to different manufacturers in the former case, and people wearing more or less measurement devices in the latter (ii) We are not allowed to store or re-access data from a task once it has been observed at the task level. This may be due to privacy considerations in the case of people, or legal restrictions placed by machine owners. Nevertheless, we would like to (a) improve performance on subsequent tasks using experience from completed tasks as well as (b) continue to perform better on past tasks, e.g., update the model and improve predictions on even the first machine after learning from subsequently observed ones. We note that existing continual learning methods do not take into account variability in input dimensions arising due to different subsets of sensors being available across tasks, and struggle to adapt to such variable input dimensions (VID) tasks. In this work, we address this shortcoming of existing methods. To this end, we learn task-specific generative models and classifiers, and use these to augment data for target tasks. Since the input dimensions across tasks vary, we propose a novel conditioning module based on graph neural networks to aid a standard recurrent neural network. We evaluate the efficacy of the proposed approach on three publicly available datasets corresponding to two activity recognition tasks (classification) and one prognostics task (regression).
Learning to Liquidate Forex: Optimal Stopping via Adaptive Top-K Regression
Feb 25, 2022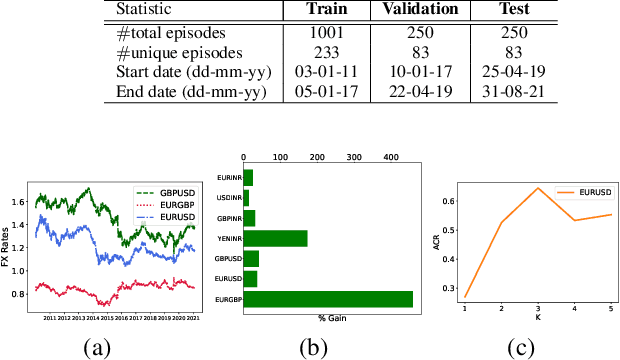
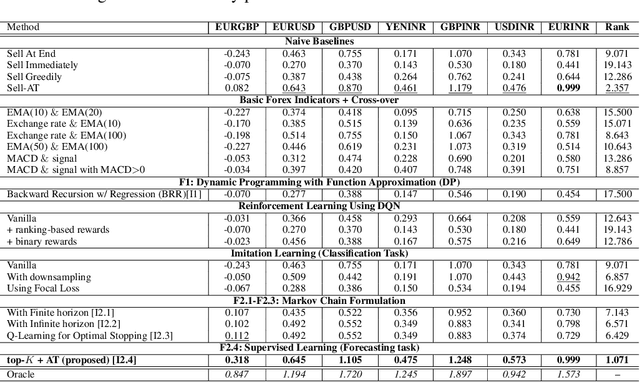
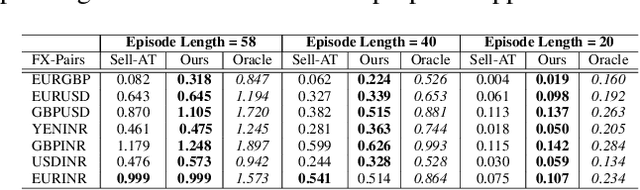
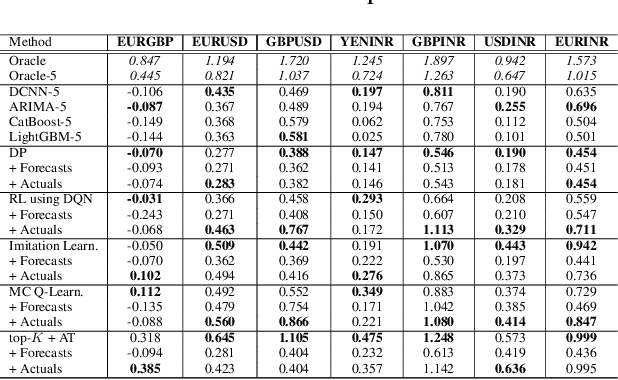
We consider learning a trading agent acting on behalf of the treasury of a firm earning revenue in a foreign currency (FC) and incurring expenses in the home currency (HC). The goal of the agent is to maximize the expected HC at the end of the trading episode by deciding to hold or sell the FC at each time step in the trading episode. We pose this as an optimization problem, and consider a broad spectrum of approaches with the learning component ranging from supervised to imitation to reinforcement learning. We observe that most of the approaches considered struggle to improve upon simple heuristic baselines. We identify two key aspects of the problem that render standard solutions ineffective - i) while good forecasts of future FX rates can be highly effective in guiding good decisions, forecasting FX rates is difficult, and erroneous estimates tend to degrade the performance of trading agents instead of improving it, ii) the inherent non-stationary nature of FX rates renders a fixed decision-threshold highly ineffective. To address these problems, we propose a novel supervised learning approach that learns to forecast the top-K future FX rates instead of forecasting all the future FX rates, and bases the hold-versus-sell decision on the forecasts (e.g. hold if future FX rate is higher than current FX rate, sell otherwise). Furthermore, to handle the non-stationarity in the FX rates data which poses challenges to the i.i.d. assumption in supervised learning methods, we propose to adaptively learn decision-thresholds based on recent historical episodes. Through extensive empirical evaluation, we show that our approach is the only approach which is able to consistently improve upon a simple heuristic baseline. Further experiments show the inefficacy of state-of-the-art statistical and deep-learning-based forecasting methods as they degrade the performance of the trading agent.
Electricity Consumption Forecasting for Out-of-distribution Time-of-Use Tariffs
Feb 11, 2022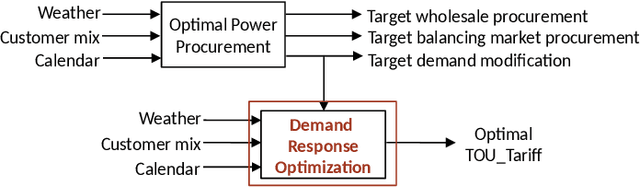

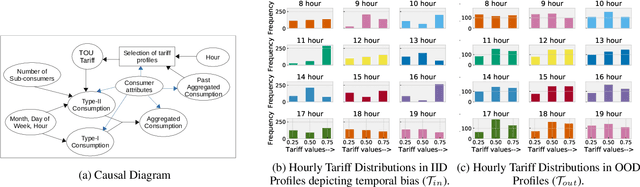

In electricity markets, retailers or brokers want to maximize profits by allocating tariff profiles to end consumers. One of the objectives of such demand response management is to incentivize the consumers to adjust their consumption so that the overall electricity procurement in the wholesale markets is minimized, e.g. it is desirable that consumers consume less during peak hours when cost of procurement for brokers from wholesale markets are high. We consider a greedy solution to maximize the overall profit for brokers by optimal tariff profile allocation. This in-turn requires forecasting electricity consumption for each user for all tariff profiles. This forecasting problem is challenging compared to standard forecasting problems due to following reasons: i. the number of possible combinations of hourly tariffs is high and retailers may not have considered all combinations in the past resulting in a biased set of tariff profiles tried in the past, ii. the profiles allocated in the past to each user is typically based on certain policy. These reasons violate the standard i.i.d. assumptions, as there is a need to evaluate new tariff profiles on existing customers and historical data is biased by the policies used in the past for tariff allocation. In this work, we consider several scenarios for forecasting and optimization under these conditions. We leverage the underlying structure of how consumers respond to variable tariff rates by comparing tariffs across hours and shifting loads, and propose suitable inductive biases in the design of deep neural network based architectures for forecasting under such scenarios. More specifically, we leverage attention mechanisms and permutation equivariant networks that allow desirable processing of tariff profiles to learn tariff representations that are insensitive to the biases in the data and still representative of the task.
Systematic Generalization in Neural Networks-based Multivariate Time Series Forecasting Models
Mar 07, 2021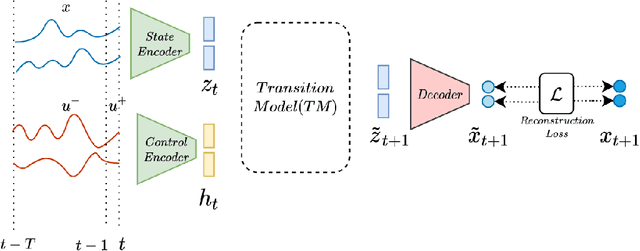
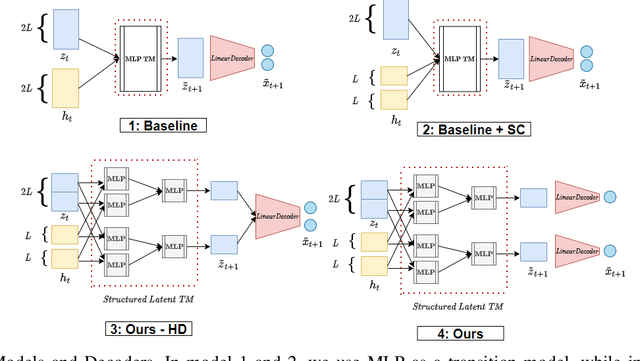
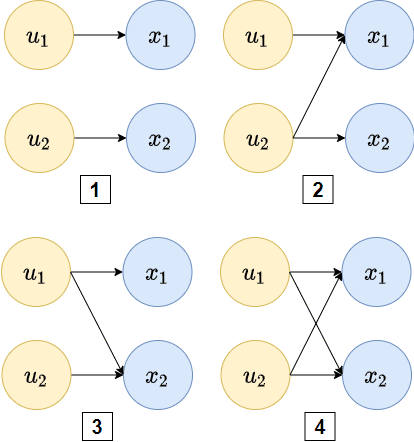
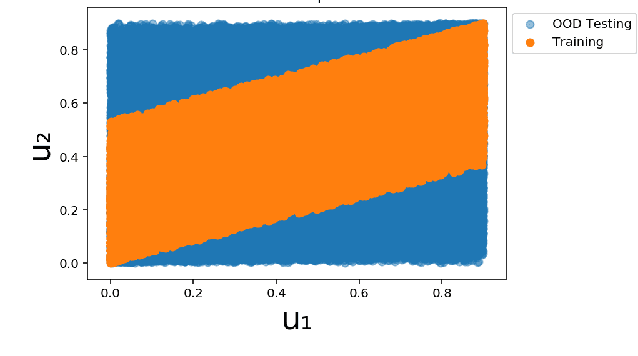
Systematic generalization aims to evaluate reasoning about novel combinations from known components, an intrinsic property of human cognition. In this work, we study systematic generalization of NNs in forecasting future time series of dependent variables in a dynamical system, conditioned on past time series of dependent variables, and past and future control variables. We focus on systematic generalization wherein the NN-based forecasting model should perform well on previously unseen combinations or regimes of control variables after being trained on a limited set of the possible regimes. For NNs to depict such out-of-distribution generalization, they should be able to disentangle the various dependencies between control variables and dependent variables. We hypothesize that a modular NN architecture guided by the readily-available knowledge of independence of control variables as a potentially useful inductive bias to this end. Through extensive empirical evaluation on a toy dataset and a simulated electric motor dataset, we show that our proposed modular NN architecture serves as a simple yet highly effective inductive bias that enabling better forecasting of the dependent variables up to large horizons in contrast to standard NNs, and indeed capture the true dependency relations between the dependent and the control variables.
Batch-Constrained Distributional Reinforcement Learning for Session-based Recommendation
Dec 16, 2020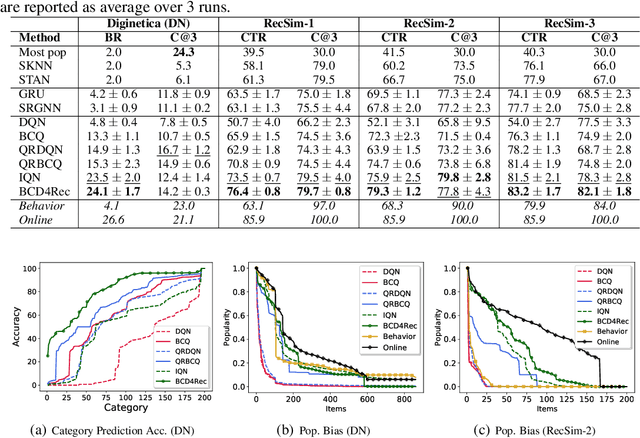
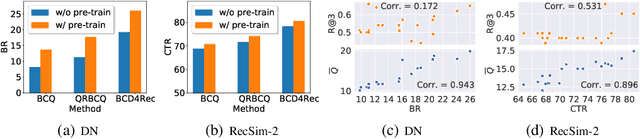

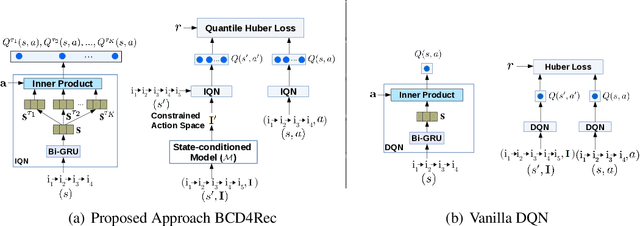
Most of the existing deep reinforcement learning (RL) approaches for session-based recommendations either rely on costly online interactions with real users, or rely on potentially biased rule-based or data-driven user-behavior models for learning. In this work, we instead focus on learning recommendation policies in the pure batch or offline setting, i.e. learning policies solely from offline historical interaction logs or batch data generated from an unknown and sub-optimal behavior policy, without further access to data from the real-world or user-behavior models. We propose BCD4Rec: Batch-Constrained Distributional RL for Session-based Recommendations. BCD4Rec builds upon the recent advances in batch (offline) RL and distributional RL to learn from offline logs while dealing with the intrinsically stochastic nature of rewards from the users due to varied latent interest preferences (environments). We demonstrate that BCD4Rec significantly improves upon the behavior policy as well as strong RL and non-RL baselines in the batch setting in terms of standard performance metrics like Click Through Rates or Buy Rates. Other useful properties of BCD4Rec include: i. recommending items from the correct latent categories indicating better value estimates despite large action space (of the order of number of items), and ii. overcoming popularity bias in clicked or bought items typically present in the offline logs.
Handling Variable-Dimensional Time Series with Graph Neural Networks
Jul 07, 2020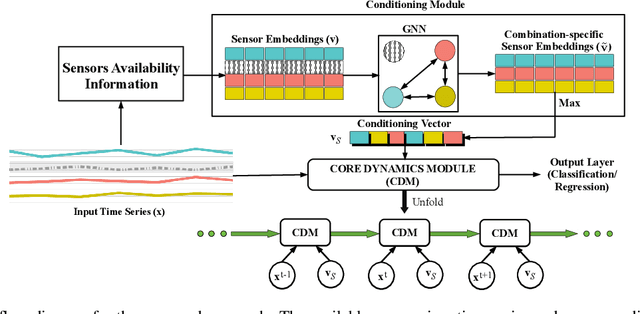
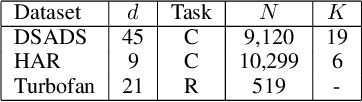
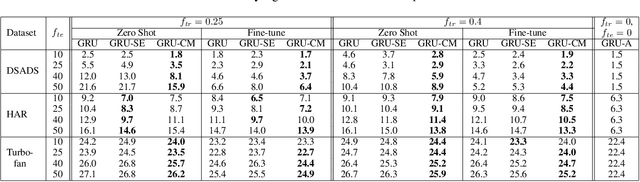
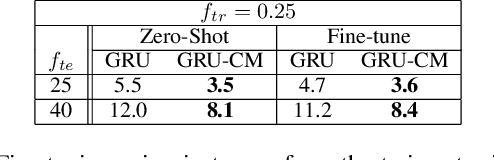
Several applications of Internet of Things (IoT) technology involve capturing data from multiple sensors resulting in multi-sensor time series. Existing neural networks based approaches for such multi-sensor or multivariate time series modeling assume fixed input dimension or number of sensors. Such approaches can struggle in the practical setting where different instances of the same device or equipment such as mobiles, wearables, engines, etc. come with different combinations of installed sensors. We consider training neural network models from such multi-sensor time series, where the time series have varying input dimensionality owing to availability or installation of a different subset of sensors at each source of time series. We propose a novel neural network architecture suitable for zero-shot transfer learning allowing robust inference for multivariate time series with previously unseen combination of available dimensions or sensors at test time. Such a combinatorial generalization is achieved by conditioning the layers of a core neural network-based time series model with a "conditioning vector" that carries information of the available combination of sensors for each time series. This conditioning vector is obtained by summarizing the set of learned "sensor embedding vectors" corresponding to the available sensors in a time series via a graph neural network. We evaluate the proposed approach on publicly available activity recognition and equipment prognostics datasets, and show that the proposed approach allows for better generalization in comparison to a deep gated recurrent neural network baseline.
Graph Neural Networks for Leveraging Industrial Equipment Structure: An application to Remaining Useful Life Estimation
Jun 30, 2020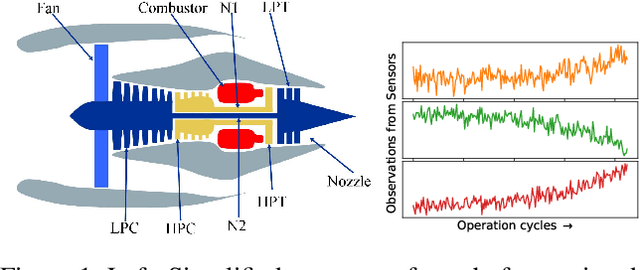
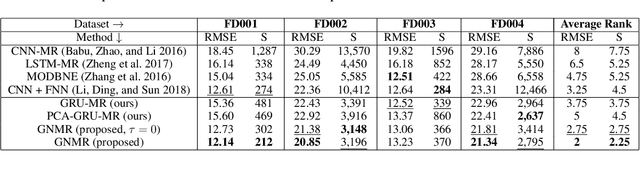
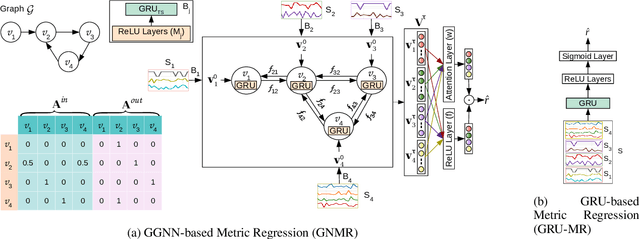

Automated equipment health monitoring from streaming multisensor time-series data can be used to enable condition-based maintenance, avoid sudden catastrophic failures, and ensure high operational availability. We note that most complex machinery has a well-documented and readily accessible underlying structure capturing the inter-dependencies between sub-systems or modules. Deep learning models such as those based on recurrent neural networks (RNNs) or convolutional neural networks (CNNs) fail to explicitly leverage this potentially rich source of domain-knowledge into the learning procedure. In this work, we propose to capture the structure of a complex equipment in the form of a graph, and use graph neural networks (GNNs) to model multi-sensor time-series data. Using remaining useful life estimation as an application task, we evaluate the advantage of incorporating the graph structure via GNNs on the publicly available turbofan engine benchmark dataset. We observe that the proposed GNN-based RUL estimation model compares favorably to several strong baselines from literature such as those based on RNNs and CNNs. Additionally, we observe that the learned network is able to focus on the module (node) with impending failure through a simple attention mechanism, potentially paving the way for actionable diagnosis.
Meta-Learning for Few-Shot Time Series Classification
Sep 25, 2019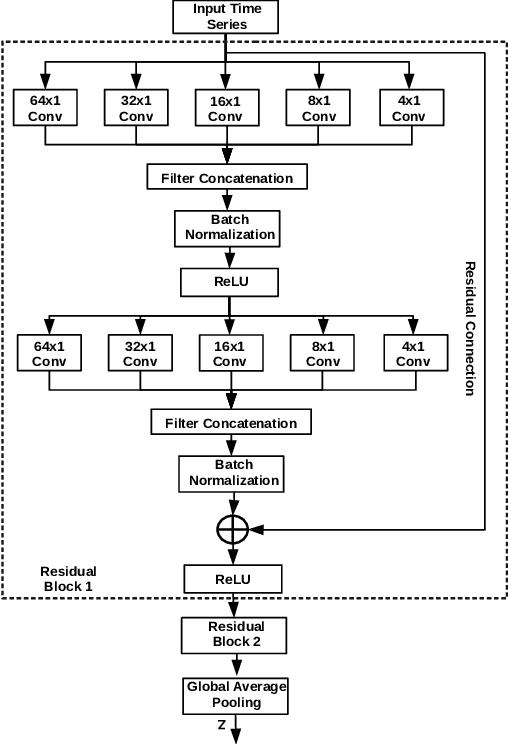
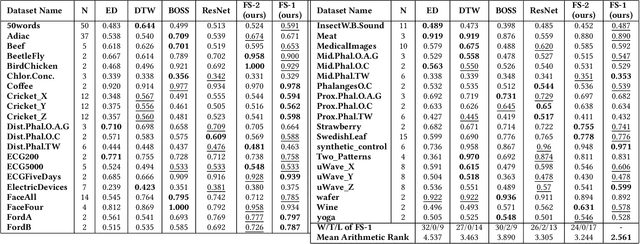
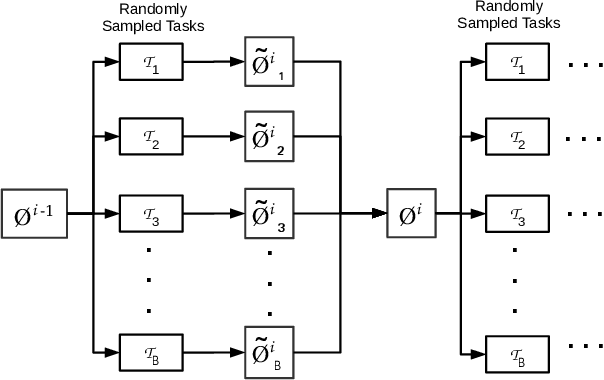
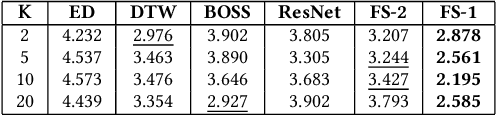
Deep neural networks (DNNs) have achieved state-of-the-art results on time series classification (TSC) tasks. In this work, we focus on leveraging DNNs in the often-encountered practical scenario where access to labeled training data is difficult, and where DNNs would be prone to overfitting. We leverage recent advancements in gradient-based meta-learning, and propose an approach to train a residual neural network with convolutional layers as a meta-learning agent for few-shot TSC. The network is trained on a diverse set of few-shot tasks sampled from various domains (e.g. healthcare, activity recognition, etc.) such that it can solve a target task from another domain using only a small number of training samples from the target task. Most existing meta-learning approaches are limited in practice as they assume a fixed number of target classes across tasks. We overcome this limitation in order to train a common agent across domains with each domain having different number of target classes, we utilize a triplet-loss based learning procedure that does not require any constraints to be enforced on the number of classes for the few-shot TSC tasks. To the best of our knowledge, we are the first to use meta-learning based pre-training for TSC. Our approach sets a new benchmark for few-shot TSC, outperforming several strong baselines on few-shot tasks sampled from 41 datasets in UCR TSC Archive. We observe that pre-training under the meta-learning paradigm allows the network to quickly adapt to new unseen tasks with small number of labeled instances.