 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatryoshka Model Learning for Improved Elastic Student Models
May 29, 2025Industry-grade ML models are carefully designed to meet rapidly evolving serving constraints, which requires significant resources for model development. In this paper, we propose MatTA, a framework for training multiple accurate Student models using a novel Teacher-TA-Student recipe. TA models are larger versions of the Student models with higher capacity, and thus allow Student models to better relate to the Teacher model and also bring in more domain-specific expertise. Furthermore, multiple accurate Student models can be extracted from the TA model. Therefore, despite only one training run, our methodology provides multiple servable options to trade off accuracy for lower serving cost. We demonstrate the proposed method, MatTA, on proprietary datasets and models. Its practical efficacy is underscored by live A/B tests within a production ML system, demonstrating 20% improvement on a key metric. We also demonstrate our method on GPT-2 Medium, a public model, and achieve relative improvements of over 24% on SAT Math and over 10% on the LAMBADA benchmark.
Unpacking the Resilience of SNLI Contradiction Examples to Attacks
Dec 15, 2024Pre-trained models excel on NLI benchmarks like SNLI and MultiNLI, but their true language understanding remains uncertain. Models trained only on hypotheses and labels achieve high accuracy, indicating reliance on dataset biases and spurious correlations. To explore this issue, we applied the Universal Adversarial Attack to examine the model's vulnerabilities. Our analysis revealed substantial drops in accuracy for the entailment and neutral classes, whereas the contradiction class exhibited a smaller decline. Fine-tuning the model on an augmented dataset with adversarial examples restored its performance to near-baseline levels for both the standard and challenge sets. Our findings highlight the value of adversarial triggers in identifying spurious correlations and improving robustness while providing insights into the resilience of the contradiction class to adversarial attacks.
URL-BERT: Training Webpage Representations via Social Media Engagements
Oct 25, 2023



Understanding and representing webpages is crucial to online social networks where users may share and engage with URLs. Common language model (LM) encoders such as BERT can be used to understand and represent the textual content of webpages. However, these representations may not model thematic information of web domains and URLs or accurately capture their appeal to social media users. In this work, we introduce a new pre-training objective that can be used to adapt LMs to understand URLs and webpages. Our proposed framework consists of two steps: (1) scalable graph embeddings to learn shallow representations of URLs based on user engagement on social media and (2) a contrastive objective that aligns LM representations with the aforementioned graph-based representation. We apply our framework to the multilingual version of BERT to obtain the model URL-BERT. We experimentally demonstrate that our continued pre-training approach improves webpage understanding on a variety of tasks and Twitter internal and external benchmarks.
Electricity Consumption Forecasting for Out-of-distribution Time-of-Use Tariffs
Feb 11, 2022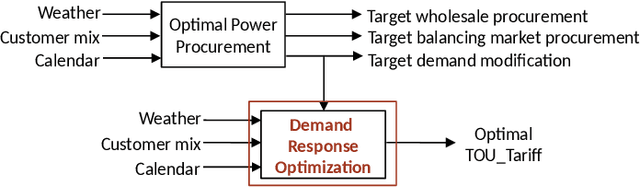

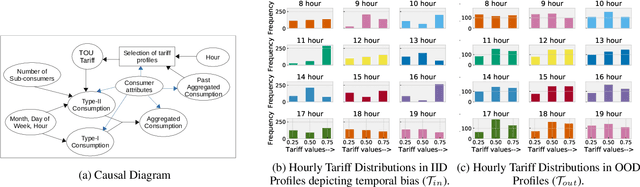

In electricity markets, retailers or brokers want to maximize profits by allocating tariff profiles to end consumers. One of the objectives of such demand response management is to incentivize the consumers to adjust their consumption so that the overall electricity procurement in the wholesale markets is minimized, e.g. it is desirable that consumers consume less during peak hours when cost of procurement for brokers from wholesale markets are high. We consider a greedy solution to maximize the overall profit for brokers by optimal tariff profile allocation. This in-turn requires forecasting electricity consumption for each user for all tariff profiles. This forecasting problem is challenging compared to standard forecasting problems due to following reasons: i. the number of possible combinations of hourly tariffs is high and retailers may not have considered all combinations in the past resulting in a biased set of tariff profiles tried in the past, ii. the profiles allocated in the past to each user is typically based on certain policy. These reasons violate the standard i.i.d. assumptions, as there is a need to evaluate new tariff profiles on existing customers and historical data is biased by the policies used in the past for tariff allocation. In this work, we consider several scenarios for forecasting and optimization under these conditions. We leverage the underlying structure of how consumers respond to variable tariff rates by comparing tariffs across hours and shifting loads, and propose suitable inductive biases in the design of deep neural network based architectures for forecasting under such scenarios. More specifically, we leverage attention mechanisms and permutation equivariant networks that allow desirable processing of tariff profiles to learn tariff representations that are insensitive to the biases in the data and still representative of the task.
Challenges and approaches to privacy preserving post-click conversion prediction
Jan 29, 2022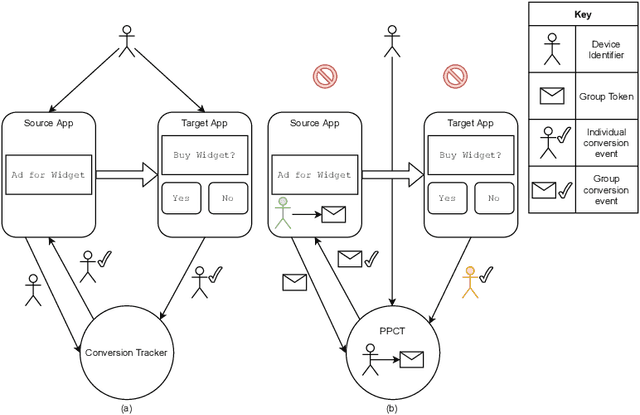
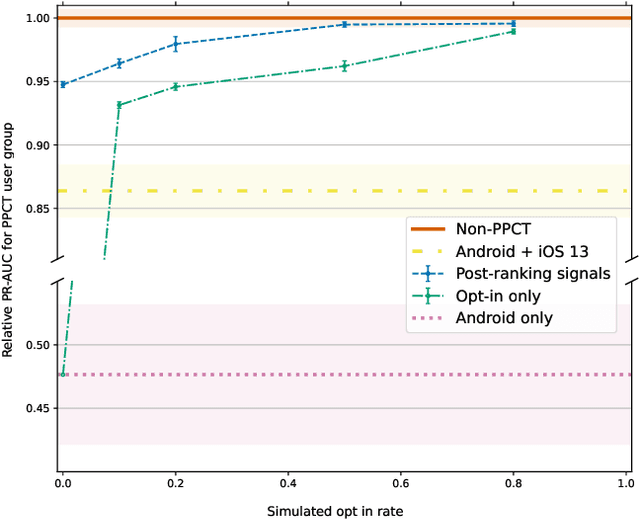
Online advertising has typically been more personalized than offline advertising, through the use of machine learning models and real-time auctions for ad targeting. One specific task, predicting the likelihood of conversion (i.e.\ the probability a user will purchase the advertised product), is crucial to the advertising ecosystem for both targeting and pricing ads. Currently, these models are often trained by observing individual user behavior, but, increasingly, regulatory and technical constraints are requiring privacy-preserving approaches. For example, major platforms are moving to restrict tracking individual user events across multiple applications, and governments around the world have shown steadily more interest in regulating the use of personal data. Instead of receiving data about individual user behavior, advertisers may receive privacy-preserving feedback, such as the number of installs of an advertised app that resulted from a group of users. In this paper we outline the recent privacy-related changes in the online advertising ecosystem from a machine learning perspective. We provide an overview of the challenges and constraints when learning conversion models in this setting. We introduce a novel approach for training these models that makes use of post-ranking signals. We show using offline experiments on real world data that it outperforms a model relying on opt-in data alone, and significantly reduces model degradation when no individual labels are available. Finally, we discuss future directions for research in this evolving area.