 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning, Fast and Slow: Towards LLMs That Adapt Continually
May 14, 2026Large language models (LLMs) are trained for downstream tasks by updating their parameters (e.g., via RL). However, updating parameters forces them to absorb task-specific information, which can result in catastrophic forgetting and loss of plasticity. In contrast, in-context learning with fixed LLM parameters can cheaply and rapidly adapt to task-specific requirements (e.g., prompt optimization), but cannot by itself typically match the performance gains available through updating LLM parameters. There is no good reason for restricting learning to being in-context or in-weights. Moreover, humans also likely learn at different time scales (e.g., System 1 vs 2). To this end, we introduce a fast-slow learning framework for LLMs, with model parameters as "slow" weights and optimized context as "fast" weights. These fast "weights" can learn from textual feedback to absorb the task-specific information, while allowing slow weights to stay closer to the base model and persist general reasoning behaviors. Fast-Slow Training (FST) is up to 3x more sample-efficient than only slow learning (RL) across reasoning tasks, while consistently reaching a higher performance asymptote. Moreover, FST-trained models remain closer to the base LLM (up to 70% less KL divergence), resulting in less catastrophic forgetting than RL-training. This reduced drift also preserves plasticity: after training on one task, FST trained models adapt more effectively to a subsequent task than parameter-only trained models. In continual learning scenarios, where task domains change on the fly, FST continues to acquire each new task while parameter-only RL stalls.
Best of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
Feb 12, 2026We propose UniDFlow, a unified discrete flow-matching framework for multimodal understanding, generation, and editing. It decouples understanding and generation via task-specific low-rank adapters, avoiding objective interference and representation entanglement, while a novel reference-based multimodal preference alignment optimizes relative outcomes under identical conditioning, improving faithfulness and controllability without large-scale retraining. UniDFlpw achieves SOTA performance across eight benchmarks and exhibits strong zero-shot generalization to tasks including inpainting, in-context image generation, reference-based editing, and compositional generation, despite no explicit task-specific training.
PyraTok: Language-Aligned Pyramidal Tokenizer for Video Understanding and Generation
Jan 22, 2026Discrete video VAEs underpin modern text-to-video generation and video understanding systems, yet existing tokenizers typically learn visual codebooks at a single scale with limited vocabularies and shallow language supervision, leading to poor cross-modal alignment and zero-shot transfer. We introduce PyraTok, a language-aligned pyramidal tokenizer that learns semantically structured discrete latents across multiple spatiotemporal resolutions. PyraTok builds on a pretrained video VAE and a novel Language aligned Pyramidal Quantization (LaPQ) module that discretizes encoder features at several depths using a shared large binary codebook, yielding compact yet expressive video token sequences. To tightly couple visual tokens with language, PyraTok jointly optimizes multi-scale text-guided quantization and a global autoregressive objective over the token hierarchy. Across ten benchmarks, PyraTok delivers state-of-the-art (SOTA) video reconstruction, consistently improves text-to-video quality, and sets new SOTA zero-shot performance on video segmentation, temporal action localization, and video understanding, scaling robustly to up to 4K/8K resolutions.
Matryoshka Model Learning for Improved Elastic Student Models
May 29, 2025Industry-grade ML models are carefully designed to meet rapidly evolving serving constraints, which requires significant resources for model development. In this paper, we propose MatTA, a framework for training multiple accurate Student models using a novel Teacher-TA-Student recipe. TA models are larger versions of the Student models with higher capacity, and thus allow Student models to better relate to the Teacher model and also bring in more domain-specific expertise. Furthermore, multiple accurate Student models can be extracted from the TA model. Therefore, despite only one training run, our methodology provides multiple servable options to trade off accuracy for lower serving cost. We demonstrate the proposed method, MatTA, on proprietary datasets and models. Its practical efficacy is underscored by live A/B tests within a production ML system, demonstrating 20% improvement on a key metric. We also demonstrate our method on GPT-2 Medium, a public model, and achieve relative improvements of over 24% on SAT Math and over 10% on the LAMBADA benchmark.
Geometric Median Matching for Robust k-Subset Selection from Noisy Data
Apr 03, 2025

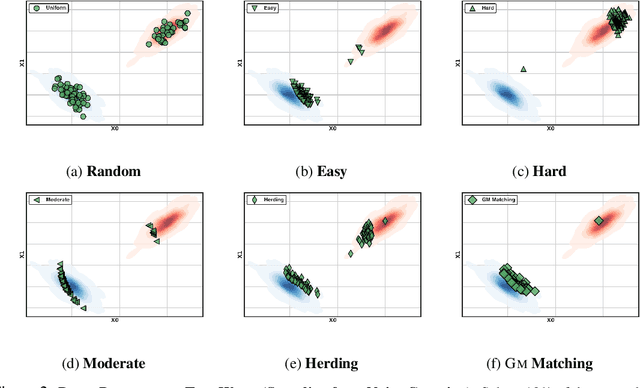

Data pruning -- the combinatorial task of selecting a small and representative subset from a large dataset, is crucial for mitigating the enormous computational costs associated with training data-hungry modern deep learning models at scale. Since large scale data collections are invariably noisy, developing data pruning strategies that remain robust even in the presence of corruption is critical in practice. However, existing data pruning methods often fail under high corruption rates due to their reliance on empirical mean estimation, which is highly sensitive to outliers. In response, we propose Geometric Median (GM) Matching, a novel k-subset selection strategy that leverages Geometric Median -- a robust estimator with an optimal breakdown point of 1/2; to enhance resilience against noisy data. Our method iteratively selects a k-subset such that the mean of the subset approximates the GM of the (potentially) noisy dataset, ensuring robustness even under arbitrary corruption. We provide theoretical guarantees, showing that GM Matching enjoys an improved O(1/k) convergence rate -- a quadratic improvement over random sampling, even under arbitrary corruption. Extensive experiments across image classification and image generation tasks demonstrate that GM Matching consistently outperforms existing pruning approaches, particularly in high-corruption settings and at high pruning rates; making it a strong baseline for robust data pruning.
Geometric Median (GM) Matching for Robust Data Pruning
Jun 25, 2024



Data pruning, the combinatorial task of selecting a small and informative subset from a large dataset, is crucial for mitigating the enormous computational costs associated with training data-hungry modern deep learning models at scale. Since large-scale data collections are invariably noisy, developing data pruning strategies that remain robust even in the presence of corruption is critical in practice. Unfortunately, the existing heuristics for (robust) data pruning lack theoretical coherence and rely on heroic assumptions, that are, often unattainable, by the very nature of the problem setting. Moreover, these strategies often yield sub-optimal neural scaling laws even compared to random sampling, especially in scenarios involving strong corruption and aggressive pruning rates -- making provably robust data pruning an open challenge. In response, in this work, we propose Geometric Median ($\gm$) Matching -- a herding~\citep{welling2009herding} style greedy algorithm -- that yields a $k$-subset such that the mean of the subset approximates the geometric median of the (potentially) noisy dataset. Theoretically, we show that $\gm$ Matching enjoys an improved $\gO(1/k)$ scaling over $\gO(1/\sqrt{k})$ scaling of uniform sampling; while achieving the optimal breakdown point of 1/2 even under arbitrary corruption. Extensive experiments across popular deep learning benchmarks indicate that $\gm$ Matching consistently outperforms prior state-of-the-art; the gains become more profound at high rates of corruption and aggressive pruning rates; making $\gm$ Matching a strong baseline for future research in robust data pruning.
Efficacy of Dual-Encoders for Extreme Multi-Label Classification
Oct 16, 2023Dual-encoder models have demonstrated significant success in dense retrieval tasks for open-domain question answering that mostly involves zero-shot and few-shot scenarios. However, their performance in many-shot retrieval problems where training data is abundant, such as extreme multi-label classification (XMC), remains under-explored. Existing empirical evidence suggests that, for such problems, the dual-encoder method's accuracies lag behind the performance of state-of-the-art (SOTA) extreme classification methods that grow the number of learnable parameters linearly with the number of classes. As a result, some recent extreme classification techniques use a combination of dual-encoders and a learnable classification head for each class to excel on these tasks. In this paper, we investigate the potential of "pure" DE models in XMC tasks. Our findings reveal that when trained correctly standard dual-encoders can match or outperform SOTA extreme classification methods by up to 2% at Precision@1 even on the largest XMC datasets while being 20x smaller in terms of the number of trainable parameters. We further propose a differentiable topk error-based loss function, which can be used to specifically optimize for Recall@k metrics. We include our PyTorch implementation along with other resources for reproducing the results in the supplementary material.
Preserving In-Context Learning ability in Large Language Model Fine-tuning
Nov 01, 2022Pretrained large language models (LLMs) are strong in-context learners that are able to perform few-shot learning without changing model parameters. However, as we show, fine-tuning an LLM on any specific task generally destroys its in-context ability. We discover an important cause of this loss, format specialization, where the model overfits to the format of the fine-tuned task and is unable to output anything beyond this format. We further show that format specialization happens at the beginning of fine-tuning. To solve this problem, we propose Prompt Tuning with MOdel Tuning (ProMoT), a simple yet effective two-stage fine-tuning framework that preserves in-context abilities of the pretrained model. ProMoT first trains a soft prompt for the fine-tuning target task, and then fine-tunes the model itself with this soft prompt attached. ProMoT offloads task-specific formats into the soft prompt that can be removed when doing other in-context tasks. We fine-tune mT5 XXL with ProMoT on natural language inference (NLI) and English-French translation and evaluate the in-context abilities of the resulting models on 8 different NLP tasks. ProMoT achieves similar performance on the fine-tuned tasks compared with vanilla fine-tuning, but with much less reduction of in-context learning performances across the board. More importantly, ProMoT shows remarkable generalization ability on tasks that have different formats, e.g. fine-tuning on a NLI binary classification task improves the model's in-context ability to do summarization (+0.53 Rouge-2 score compared to the pretrained model), making ProMoT a promising method to build general purpose capabilities such as grounding and reasoning into LLMs with small but high quality datasets. When extended to sequential or multi-task training, ProMoT can achieve even better out-of-domain generalization performance.
End-to-End Learning to Index and Search in Large Output Spaces
Oct 16, 2022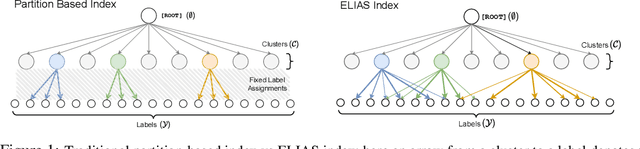
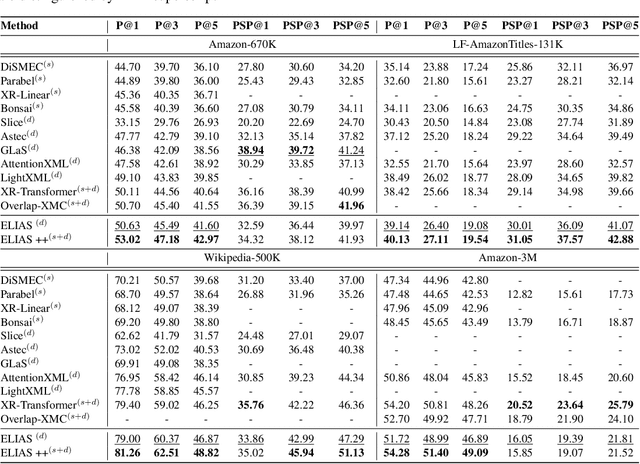
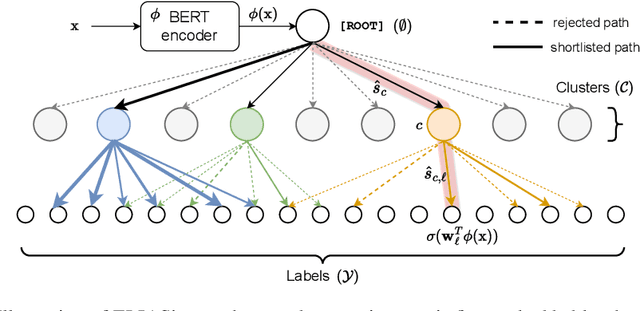
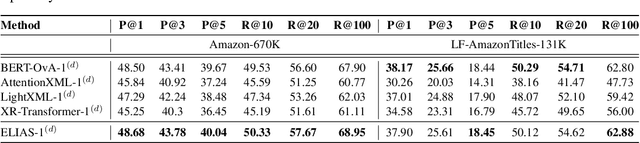
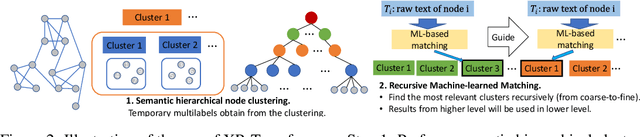
Extreme multi-label classification (XMC) is a popular framework for solving many real-world problems that require accurate prediction from a very large number of potential output choices. A popular approach for dealing with the large label space is to arrange the labels into a shallow tree-based index and then learn an ML model to efficiently search this index via beam search. Existing methods initialize the tree index by clustering the label space into a few mutually exclusive clusters based on pre-defined features and keep it fixed throughout the training procedure. This approach results in a sub-optimal indexing structure over the label space and limits the search performance to the quality of choices made during the initialization of the index. In this paper, we propose a novel method ELIAS which relaxes the tree-based index to a specialized weighted graph-based index which is learned end-to-end with the final task objective. More specifically, ELIAS models the discrete cluster-to-label assignments in the existing tree-based index as soft learnable parameters that are learned jointly with the rest of the ML model. ELIAS achieves state-of-the-art performance on several large-scale extreme classification benchmarks with millions of labels. In particular, ELIAS can be up to 2.5% better at precision@1 and up to 4% better at recall@100 than existing XMC methods. A PyTorch implementation of ELIAS along with other resources is available at https://github.com/nilesh2797/ELIAS.
Node Feature Extraction by Self-Supervised Multi-scale Neighborhood Prediction
Oct 29, 2021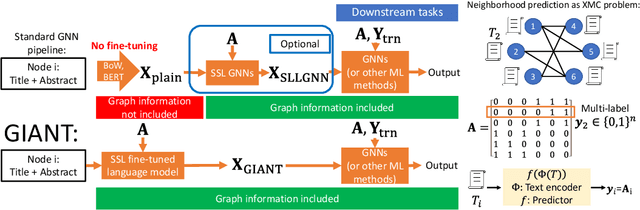

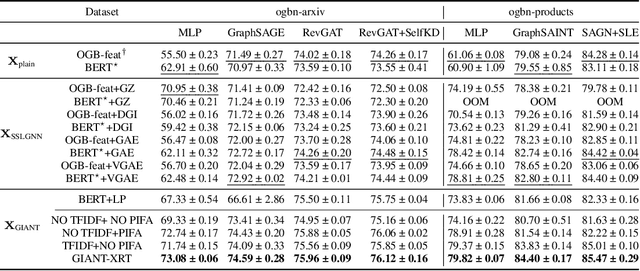
Learning on graphs has attracted significant attention in the learning community due to numerous real-world applications. In particular, graph neural networks (GNNs), which take numerical node features and graph structure as inputs, have been shown to achieve state-of-the-art performance on various graph-related learning tasks. Recent works exploring the correlation between numerical node features and graph structure via self-supervised learning have paved the way for further performance improvements of GNNs. However, methods used for extracting numerical node features from raw data are still graph-agnostic within standard GNN pipelines. This practice is sub-optimal as it prevents one from fully utilizing potential correlations between graph topology and node attributes. To mitigate this issue, we propose a new self-supervised learning framework, Graph Information Aided Node feature exTraction (GIANT). GIANT makes use of the eXtreme Multi-label Classification (XMC) formalism, which is crucial for fine-tuning the language model based on graph information, and scales to large datasets. We also provide a theoretical analysis that justifies the use of XMC over link prediction and motivates integrating XR-Transformers, a powerful method for solving XMC problems, into the GIANT framework. We demonstrate the superior performance of GIANT over the standard GNN pipeline on Open Graph Benchmark datasets: For example, we improve the accuracy of the top-ranked method GAMLP from $68.25\%$ to $69.67\%$, SGC from $63.29\%$ to $66.10\%$ and MLP from $47.24\%$ to $61.10\%$ on the ogbn-papers100M dataset by leveraging GIANT.