 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompute Allocation for Reasoning-Intensive Retrieval Agents
Mar 15, 2026As agents operate over long horizons, their memory stores grow continuously, making retrieval critical to accessing relevant information. Many agent queries require reasoning-intensive retrieval, where the connection between query and relevant documents is implicit and requires inference to bridge. LLM-augmented pipelines address this through query expansion and candidate re-ranking, but introduce significant inference costs. We study computation allocation in reasoning-intensive retrieval pipelines using the BRIGHT benchmark and Gemini 2.5 model family. We vary model capacity, inference-time thinking, and re-ranking depth across query expansion and re-ranking stages. We find that re-ranking benefits substantially from stronger models (+7.5 NDCG@10) and deeper candidate pools (+21% from $k$=10 to 100), while query expansion shows diminishing returns beyond lightweight models (+1.1 NDCG@10 from weak to strong). Inference-time thinking provides minimal improvement at either stage. These results suggest that compute should be concentrated on re-ranking rather than distributed uniformly across pipeline stages.
LUCID: Attention with Preconditioned Representations
Feb 11, 2026Softmax-based dot-product attention is a cornerstone of Transformer architectures, enabling remarkable capabilities such as in-context learning. However, as context lengths increase, a fundamental limitation of the softmax function emerges: it tends to diffuse probability mass to irrelevant tokens degrading performance in long-sequence scenarios. Furthermore, attempts to sharpen focus by lowering softmax temperature hinder learnability due to vanishing gradients. We introduce LUCID Attention, an architectural modification that applies a preconditioner to the attention probabilities. This preconditioner, derived from exponentiated key-key similarities, minimizes overlap between the keys in a Reproducing Kernel Hilbert Space, thus allowing the query to focus on important keys among large number of keys accurately with same computational complexity as standard attention. Additionally, LUCID's preconditioning-based approach to retrieval bypasses the need for low temperature and the learnability problems associated with it. We validate our approach by training ~1 billion parameter language models evaluated on up to 128K tokens. Our results demonstrate significant gains on long-context retrieval tasks, specifically retrieval tasks from BABILong, RULER, SCROLLS and LongBench. For instance, LUCID achieves up to 18% improvement in BABILong and 14% improvement in RULER multi-needle performance compared to standard attention.
Exploring Design Choices for Building Language-Specific LLMs
Jun 20, 2024Despite rapid progress in large language models (LLMs), their performance on a vast majority of languages remain unsatisfactory. In this paper, we study building language-specific LLMs by adapting monolingual and multilingual LLMs. We conduct systematic experiments on how design choices (base model selection, vocabulary extension, and continued fine-tuning) impact the adapted LLM, both in terms of efficiency (how many tokens are needed to encode the same amount of information) and end task performance. We find that (1) the initial performance before the adaptation is not always indicative of the final performance. (2) Efficiency can easily improved with simple vocabulary extension and continued fine-tuning in most LLMs we study, and (3) The optimal adaptation method is highly language-dependent, and the simplest approach works well across various experimental settings. Adapting English-centric models can yield better results than adapting multilingual models despite their worse initial performance on low-resource languages. Together, our work lays foundations on efficiently building language-specific LLMs by adapting existing LLMs.
Efficacy of Dual-Encoders for Extreme Multi-Label Classification
Oct 16, 2023Dual-encoder models have demonstrated significant success in dense retrieval tasks for open-domain question answering that mostly involves zero-shot and few-shot scenarios. However, their performance in many-shot retrieval problems where training data is abundant, such as extreme multi-label classification (XMC), remains under-explored. Existing empirical evidence suggests that, for such problems, the dual-encoder method's accuracies lag behind the performance of state-of-the-art (SOTA) extreme classification methods that grow the number of learnable parameters linearly with the number of classes. As a result, some recent extreme classification techniques use a combination of dual-encoders and a learnable classification head for each class to excel on these tasks. In this paper, we investigate the potential of "pure" DE models in XMC tasks. Our findings reveal that when trained correctly standard dual-encoders can match or outperform SOTA extreme classification methods by up to 2% at Precision@1 even on the largest XMC datasets while being 20x smaller in terms of the number of trainable parameters. We further propose a differentiable topk error-based loss function, which can be used to specifically optimize for Recall@k metrics. We include our PyTorch implementation along with other resources for reproducing the results in the supplementary material.
EHI: End-to-end Learning of Hierarchical Index for Efficient Dense Retrieval
Oct 13, 2023Dense embedding-based retrieval is now the industry standard for semantic search and ranking problems, like obtaining relevant web documents for a given query. Such techniques use a two-stage process: (a) contrastive learning to train a dual encoder to embed both the query and documents and (b) approximate nearest neighbor search (ANNS) for finding similar documents for a given query. These two stages are disjoint; the learned embeddings might be ill-suited for the ANNS method and vice-versa, leading to suboptimal performance. In this work, we propose End-to-end Hierarchical Indexing -- EHI -- that jointly learns both the embeddings and the ANNS structure to optimize retrieval performance. EHI uses a standard dual encoder model for embedding queries and documents while learning an inverted file index (IVF) style tree structure for efficient ANNS. To ensure stable and efficient learning of discrete tree-based ANNS structure, EHI introduces the notion of dense path embedding that captures the position of a query/document in the tree. We demonstrate the effectiveness of EHI on several benchmarks, including de-facto industry standard MS MARCO (Dev set and TREC DL19) datasets. For example, with the same compute budget, EHI outperforms state-of-the-art (SOTA) in by 0.6% (MRR@10) on MS MARCO dev set and by 4.2% (nDCG@10) on TREC DL19 benchmarks.
End-to-End Learning to Index and Search in Large Output Spaces
Oct 16, 2022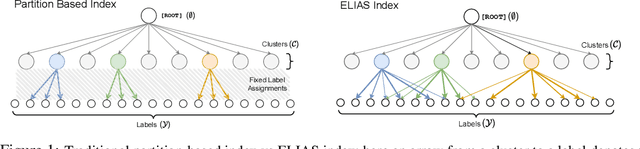
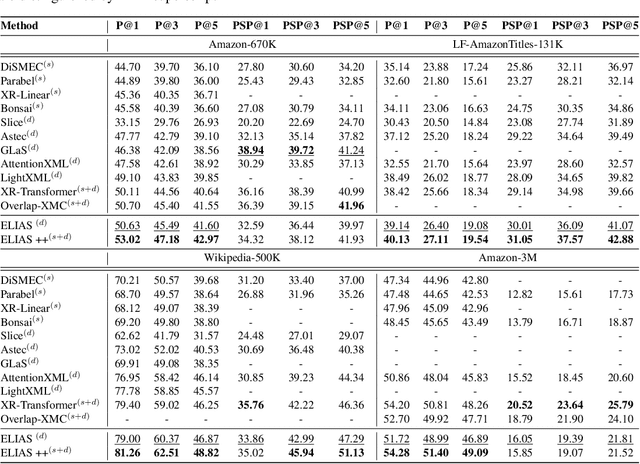
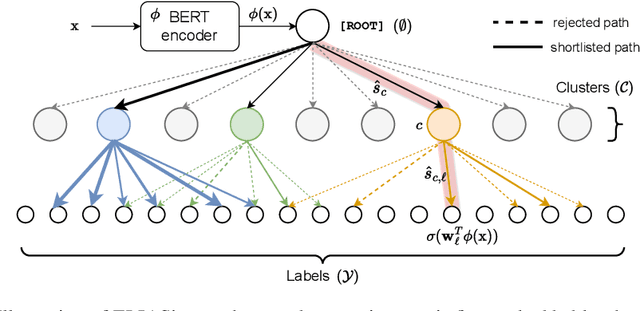
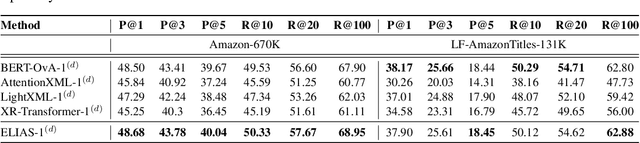
Extreme multi-label classification (XMC) is a popular framework for solving many real-world problems that require accurate prediction from a very large number of potential output choices. A popular approach for dealing with the large label space is to arrange the labels into a shallow tree-based index and then learn an ML model to efficiently search this index via beam search. Existing methods initialize the tree index by clustering the label space into a few mutually exclusive clusters based on pre-defined features and keep it fixed throughout the training procedure. This approach results in a sub-optimal indexing structure over the label space and limits the search performance to the quality of choices made during the initialization of the index. In this paper, we propose a novel method ELIAS which relaxes the tree-based index to a specialized weighted graph-based index which is learned end-to-end with the final task objective. More specifically, ELIAS models the discrete cluster-to-label assignments in the existing tree-based index as soft learnable parameters that are learned jointly with the rest of the ML model. ELIAS achieves state-of-the-art performance on several large-scale extreme classification benchmarks with millions of labels. In particular, ELIAS can be up to 2.5% better at precision@1 and up to 4% better at recall@100 than existing XMC methods. A PyTorch implementation of ELIAS along with other resources is available at https://github.com/nilesh2797/ELIAS.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022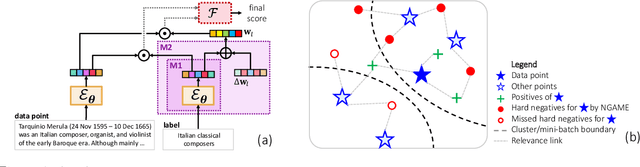
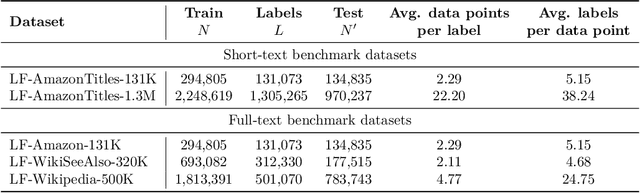
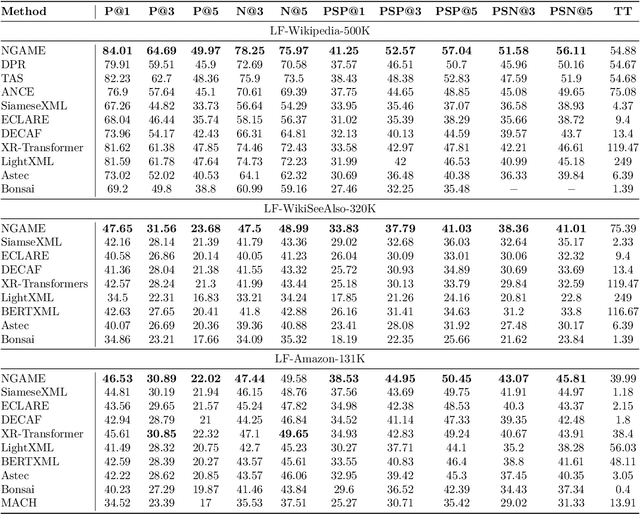
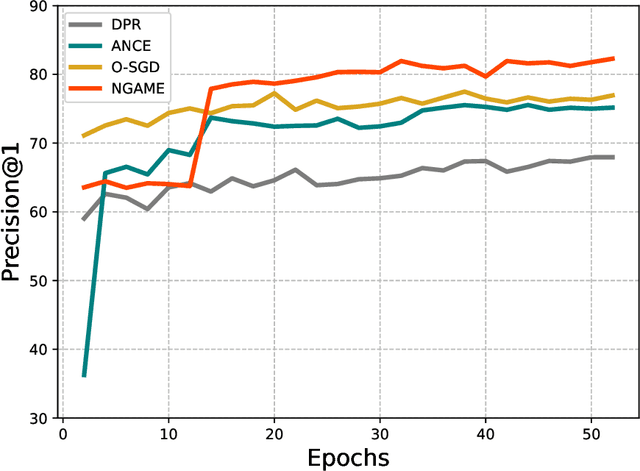
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
Extreme Regression for Dynamic Search Advertising
Jan 20, 2020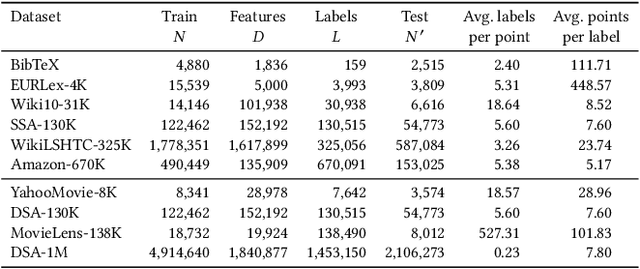
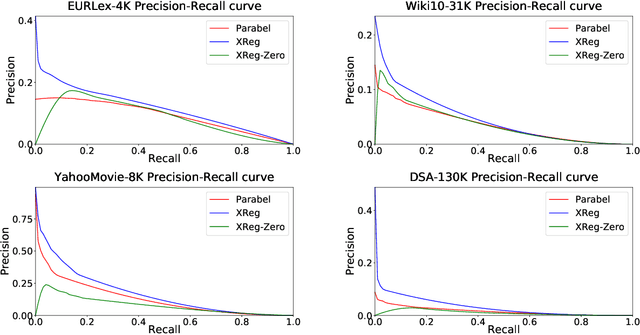
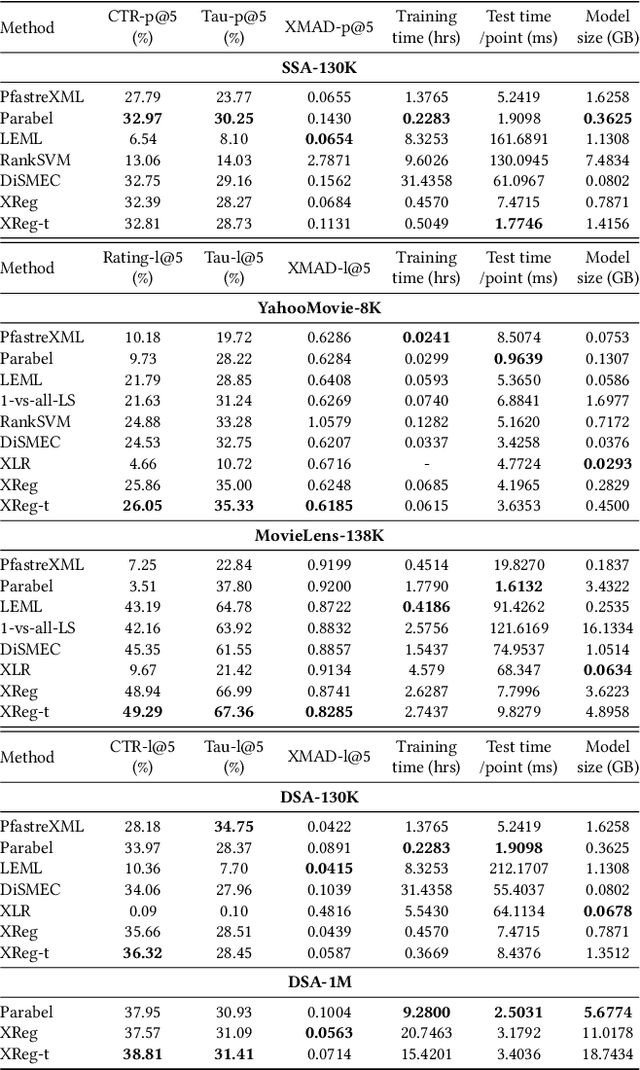
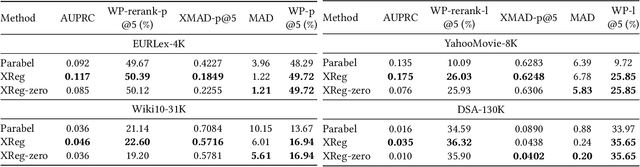
This paper introduces a new learning paradigm called eXtreme Regression (XR) whose objective is to accurately predict the numerical degrees of relevance of an extremely large number of labels to a data point. XR can provide elegant solutions to many large-scale ranking and recommendation applications including Dynamic Search Advertising (DSA). XR can learn more accurate models than the recently popular extreme classifiers which incorrectly assume strictly binary-valued label relevances. Traditional regression metrics which sum the errors over all the labels are unsuitable for XR problems since they could give extremely loose bounds for the label ranking quality. Also, the existing regression algorithms won't efficiently scale to millions of labels. This paper addresses these limitations through: (1) new evaluation metrics for XR which sum only the k largest regression errors; (2) a new algorithm called XReg which decomposes XR task into a hierarchy of much smaller regression problems thus leading to highly efficient training and prediction. This paper also introduces a (3) new labelwise prediction algorithm in XReg useful for DSA and other recommendation tasks. Experiments on benchmark datasets demonstrated that XReg can outperform the state-of-the-art extreme classifiers as well as large-scale regressors and rankers by up to 50% reduction in the new XR error metric, and up to 2% and 2.4% improvements in terms of the propensity-scored precision metric used in extreme classification and the click-through rate metric used in DSA respectively. Deployment of XReg on DSA in Bing resulted in a relative gain of 27% in query coverage. XReg's source code can be downloaded from http://manikvarma.org/code/XReg/download.html.