 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Graph Few-Shot Learning via In-Context Learning
May 23, 2026Graph few-shot learning, which aims to classify nodes from novel classes with only a few labeled examples, is a widely studied problem in graph learning. However, existing methods often face two key limitations. First, the predominant graph few-shot learning paradigm relies on supervised tasks, failing to leverage the vast number of unlabeled nodes in the graph. Second, many approaches require complex task adaptation or fine-tuning during inference, limiting their efficiency and applicability. Inspired by the powerful in-context learning capabilities of large language models, we propose a novel model named VISION for adVancIng graph few-Shot learning via In-cOntext LearNing to address these challenges. Our model reframes graph few-shot learning as a fine-tuning-free sequence reasoning problem. At its core is a context-aware network that initializes nodes with role embeddings and employs a dual-context fusion module to synergistically integrate local topological structures and global task-level dependencies. This allows our model to dynamically generate class-aware representations for the query set conditioned on the support set context in a single forward pass. To effectively train our model, we introduce an unsupervised task generator that creates structure-adaptive features and constructs diverse pseudo-tasks from abundant unlabeled data. Our method unifies unsupervised meta-learning with graph in-context learning, achieving efficient inference. Extensive experiments on multiple benchmark datasets demonstrate the superiority of our model. Our public code can be found
Efficient Spectral Efficiency Maximization Design for IRS-aided MIMO Systems
Oct 30, 2025Driven by the growing demand for higher spectral efficiency in wireless communications, intelligent reflecting surfaces (IRS) have attracted considerable attention for their ability to dynamically reconfigure the propagation environment. This work addresses the spectral efficiency maximization problem in IRS-assisted multiple-input multiple-output (MIMO) systems, which involves the joint optimization of the transmit precoding matrix and the IRS phase shift configuration. This problem is inherently challenging due to its non-convex nature. To tackle it effectively, we introduce a computationally efficient algorithm, termed ADMM-APG, which integrates the alternating direction method of multipliers (ADMM) with the accelerated projected gradient (APG) method. The proposed framework decomposes the original problem into tractable subproblems, each admitting a closed-form solution while maintaining low computational complexity. Simulation results demonstrate that the ADMM-APG algorithm consistently surpasses existing benchmark methods in terms of spectral efficiency and computational complexity, achieving significant performance gains across a range of system configurations.
Efficient Joint Precoding Design for Wideband Intelligent Reflecting Surface-Assisted Cell-Free Network
Dec 07, 2024In this paper, we propose an efficient joint precoding design method to maximize the weighted sum-rate in wideband intelligent reflecting surface (IRS)-assisted cell-free networks by jointly optimizing the active beamforming of base stations and the passive beamforming of IRS. Due to employing wideband transmissions, the frequency selectivity of IRSs has to been taken into account, whose response usually follows a Lorentzian-like profile. To address the high-dimensional non-convex optimization problem, we employ a fractional programming approach to decouple the non-convex problem into subproblems for alternating optimization between active and passive beamforming. The active beamforming subproblem is addressed using the consensus alternating direction method of multipliers (CADMM) algorithm, while the passive beamforming subproblem is tackled using the accelerated projection gradient (APG) method and Flecher-Reeves conjugate gradient method (FRCG). Simulation results demonstrate that our proposed approach achieves significant improvements in weighted sum-rate under various performance metrics compared to primal-dual subgradient (PDS) with ideal reflection matrix. This study provides valuable insights for computational complexity reduction and network capacity enhancement.
A Perspective for Adapting Generalist AI to Specialized Medical AI Applications and Their Challenges
Oct 28, 2024
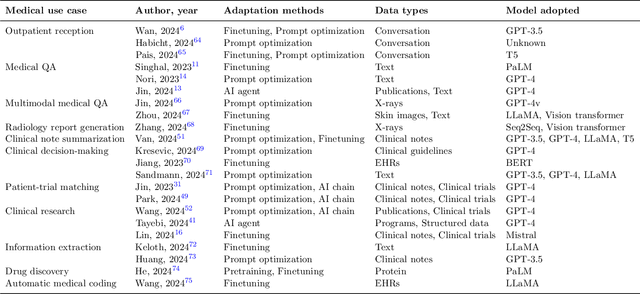

The integration of Large Language Models (LLMs) into medical applications has sparked widespread interest across the healthcare industry, from drug discovery and development to clinical decision support, assisting telemedicine, medical devices, and healthcare insurance applications. This perspective paper aims to discuss the inner workings of building LLM-powered medical AI applications and introduces a comprehensive framework for their development. We review existing literature and outline the unique challenges of applying LLMs in specialized medical contexts. Additionally, we introduce a three-step framework to organize medical LLM research activities: 1) Modeling: breaking down complex medical workflows into manageable steps for developing medical-specific models; 2) Optimization: optimizing the model performance with crafted prompts and integrating external knowledge and tools, and 3) System engineering: decomposing complex tasks into subtasks and leveraging human expertise for building medical AI applications. Furthermore, we offer a detailed use case playbook that describes various LLM-powered medical AI applications, such as optimizing clinical trial design, enhancing clinical decision support, and advancing medical imaging analysis. Finally, we discuss various challenges and considerations for building medical AI applications with LLMs, such as handling hallucination issues, data ownership and compliance, privacy, intellectual property considerations, compute cost, sustainability issues, and responsible AI requirements.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022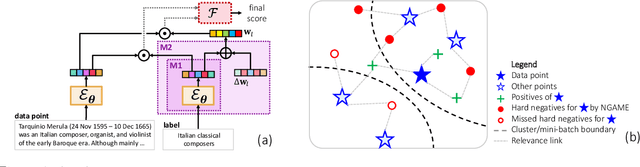
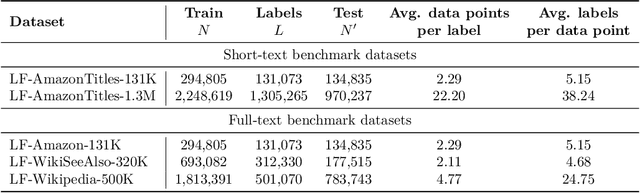
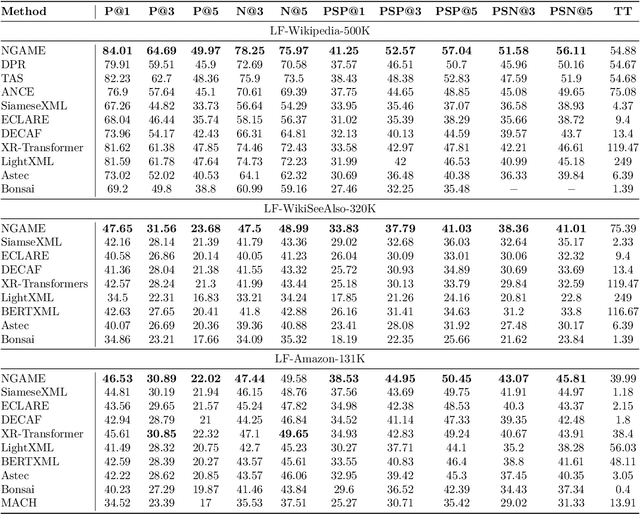
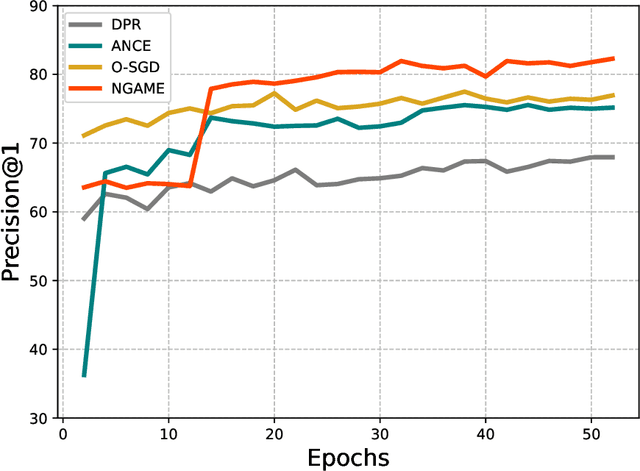
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
Hybrid Encoder: Towards Efficient and Precise Native AdsRecommendation via Hybrid Transformer Encoding Networks
Apr 22, 2021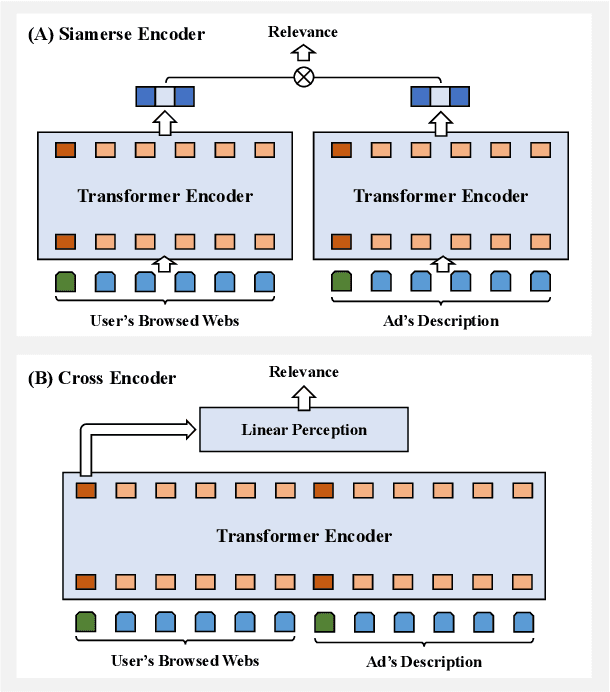
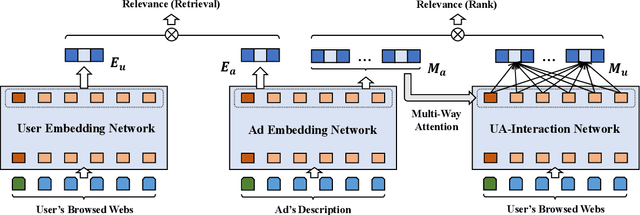
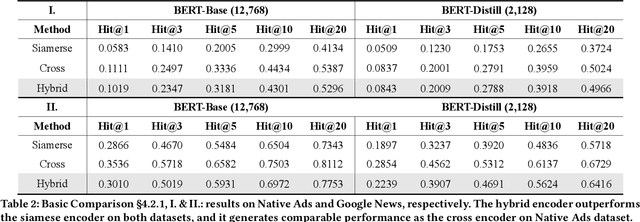
Transformer encoding networks have been proved to be a powerful tool of understanding natural languages. They are playing a critical role in native ads service, which facilitates the recommendation of appropriate ads based on user's web browsing history. For the sake of efficient recommendation, conventional methods would generate user and advertisement embeddings independently with a siamese transformer encoder, such that approximate nearest neighbour search (ANN) can be leveraged. Given that the underlying semantic about user and ad can be complicated, such independently generated embeddings are prone to information loss, which leads to inferior recommendation quality. Although another encoding strategy, the cross encoder, can be much more accurate, it will lead to huge running cost and become infeasible for realtime services, like native ads recommendation. In this work, we propose hybrid encoder, which makes efficient and precise native ads recommendation through two consecutive steps: retrieval and ranking. In the retrieval step, user and ad are encoded with a siamese component, which enables relevant candidates to be retrieved via ANN search. In the ranking step, it further represents each ad with disentangled embeddings and each user with ad-related embeddings, which contributes to the fine-grained selection of high-quality ads from the candidate set. Both steps are light-weighted, thanks to the pre-computed and cached intermedia results. To optimize the hybrid encoder's performance in this two-stage workflow, a progressive training pipeline is developed, which builds up the model's capability in the retrieval and ranking task step-by-step. The hybrid encoder's effectiveness is experimentally verified: with very little additional cost, it outperforms the siamese encoder significantly and achieves comparable recommendation quality as the cross encoder.
Multi-Interest-Aware User Modeling for Large-Scale Sequential Recommendations
Mar 04, 2021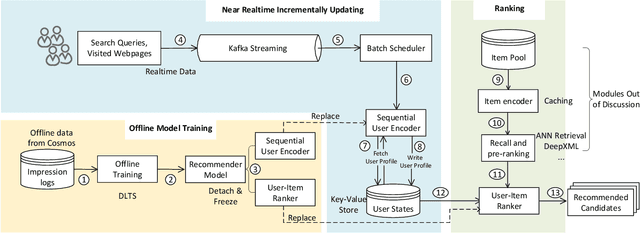
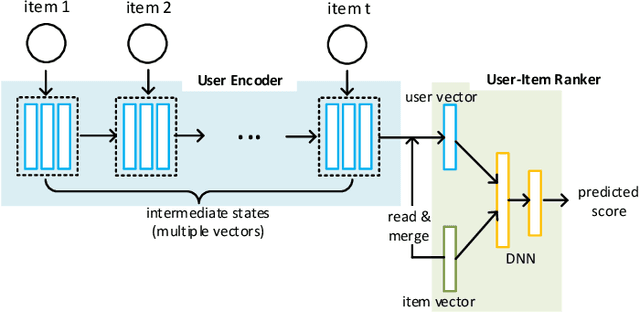
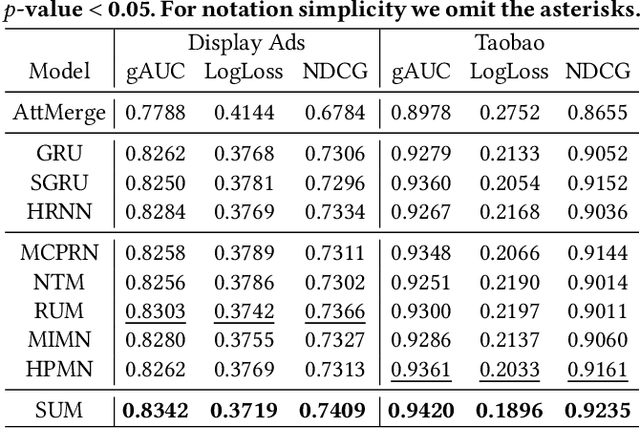
Precise user modeling is critical for online personalized recommendation services. Generally, users' interests are diverse and are not limited to a single aspect, which is particularly evident when their behaviors are observed for a longer time. For example, a user may demonstrate interests in cats/dogs, dancing and food \& delights when browsing short videos on Tik Tok; the same user may show interests in real estate and women's wear in her web browsing behaviors. Traditional models tend to encode a user's behaviors into a single embedding vector, which do not have enough capacity to effectively capture her diverse interests. This paper proposes a Sequential User Matrix (SUM) to accurately and efficiently capture users' diverse interests. SUM models user behavior with a multi-channel network, with each channel representing a different aspect of the user's interests. User states in different channels are updated by an \emph{erase-and-add} paradigm with interest- and instance-level attention. We further propose a local proximity debuff component and a highway connection component to make the model more robust and accurate. SUM can be maintained and updated incrementally, making it feasible to be deployed for large-scale online serving. We conduct extensive experiments on two datasets. Results demonstrate that SUM consistently outperforms state-of-the-art baselines.
DymSLAM:4D Dynamic Scene Reconstruction Based on Geometrical Motion Segmentation
Mar 10, 2020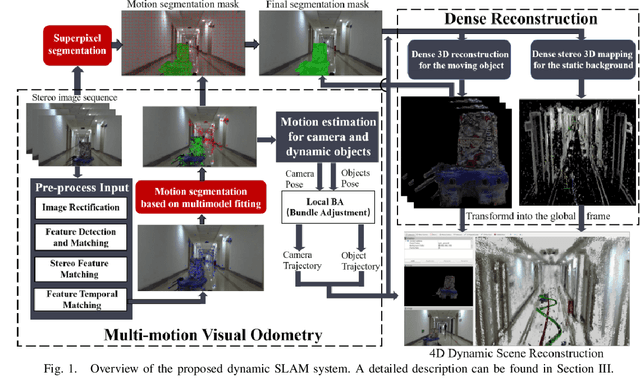

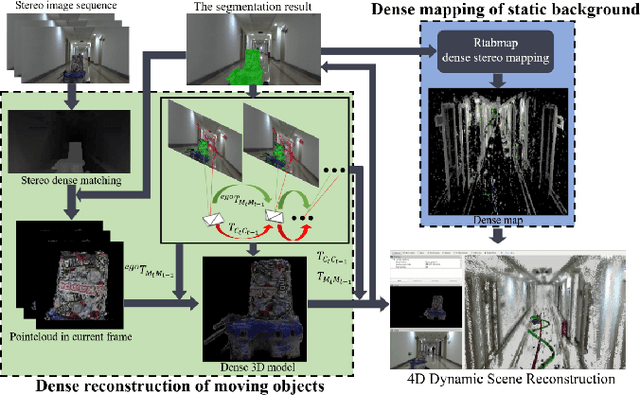

Most SLAM algorithms are based on the assumption that the scene is static. However, in practice, most scenes are dynamic which usually contains moving objects, these methods are not suitable. In this paper, we introduce DymSLAM, a dynamic stereo visual SLAM system being capable of reconstructing a 4D (3D + time) dynamic scene with rigid moving objects. The only input of DymSLAM is stereo video, and its output includes a dense map of the static environment, 3D model of the moving objects and the trajectories of the camera and the moving objects. We at first detect and match the interesting points between successive frames by using traditional SLAM methods. Then the interesting points belonging to different motion models (including ego-motion and motion models of rigid moving objects) are segmented by a multi-model fitting approach. Based on the interesting points belonging to the ego-motion, we are able to estimate the trajectory of the camera and reconstruct the static background. The interesting points belonging to the motion models of rigid moving objects are then used to estimate their relative motion models to the camera and reconstruct the 3D models of the objects. We then transform the relative motion to the trajectories of the moving objects in the global reference frame. Finally, we then fuse the 3D models of the moving objects into the 3D map of the environment by considering their motion trajectories to obtain a 4D (3D+time) sequence. DymSLAM obtains information about the dynamic objects instead of ignoring them and is suitable for unknown rigid objects. Hence, the proposed system allows the robot to be employed for high-level tasks, such as obstacle avoidance for dynamic objects. We conducted experiments in a real-world environment where both the camera and the objects were moving in a wide range.
Improving Native Ads CTR Prediction by Large Scale Event Embedding and Recurrent Networks
Aug 14, 2018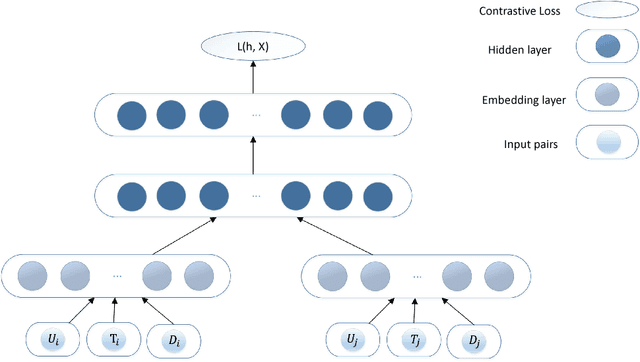

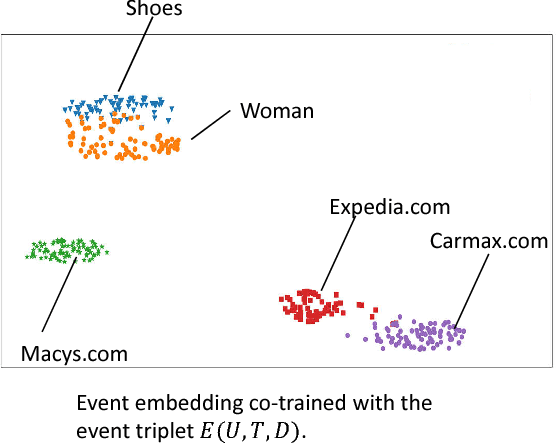

Click through rate (CTR) prediction is very important for Native advertisement but also hard as there is no direct query intent. In this paper we propose a large-scale event embedding scheme to encode the each user browsing event by training a Siamese network with weak supervision on the users' consecutive events. The CTR prediction problem is modeled as a supervised recurrent neural network, which naturally model the user history as a sequence of events. Our proposed recurrent models utilizing pretrained event embedding vectors and an attention layer to model the user history. Our experiments demonstrate that our model significantly outperforms the baseline and some variants.
Combinatorial Multi-Armed Bandit and Its Extension to Probabilistically Triggered Arms
Mar 29, 2016We define a general framework for a large class of combinatorial multi-armed bandit (CMAB) problems, where subsets of base arms with unknown distributions form super arms. In each round, a super arm is played and the base arms contained in the super arm are played and their outcomes are observed. We further consider the extension in which more based arms could be probabilistically triggered based on the outcomes of already triggered arms. The reward of the super arm depends on the outcomes of all played arms, and it only needs to satisfy two mild assumptions, which allow a large class of nonlinear reward instances. We assume the availability of an offline (\alpha,\beta)-approximation oracle that takes the means of the outcome distributions of arms and outputs a super arm that with probability {\beta} generates an {\alpha} fraction of the optimal expected reward. The objective of an online learning algorithm for CMAB is to minimize (\alpha,\beta)-approximation regret, which is the difference between the \alpha{\beta} fraction of the expected reward when always playing the optimal super arm, and the expected reward of playing super arms according to the algorithm. We provide CUCB algorithm that achieves O(log n) distribution-dependent regret, where n is the number of rounds played, and we further provide distribution-independent bounds for a large class of reward functions. Our regret analysis is tight in that it matches the bound of UCB1 algorithm (up to a constant factor) for the classical MAB problem, and it significantly improves the regret bound in a earlier paper on combinatorial bandits with linear rewards. We apply our CMAB framework to two new applications, probabilistic maximum coverage and social influence maximization, both having nonlinear reward structures. In particular, application to social influence maximization requires our extension on probabilistically triggered arms.