 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Regret Bounds for Combinatorial Semi-Bandits with Probabilistically Triggered Arms and Its Applications
Feb 21, 2018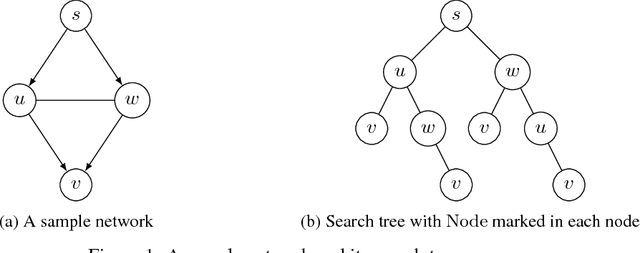
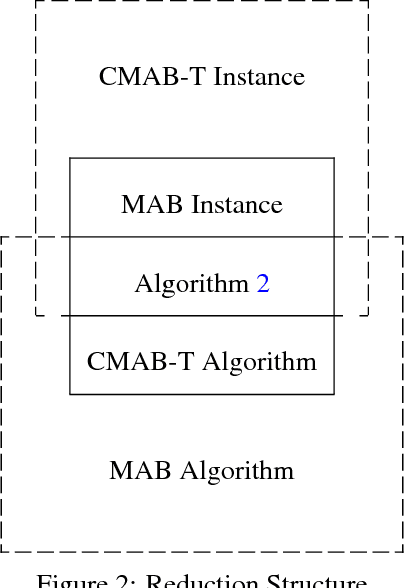
We study combinatorial multi-armed bandit with probabilistically triggered arms (CMAB-T) and semi-bandit feedback. We resolve a serious issue in the prior CMAB-T studies where the regret bounds contain a possibly exponentially large factor of $1/p^*$, where $p^*$ is the minimum positive probability that an arm is triggered by any action. We address this issue by introducing a triggering probability modulated (TPM) bounded smoothness condition into the general CMAB-T framework, and show that many applications such as influence maximization bandit and combinatorial cascading bandit satisfy this TPM condition. As a result, we completely remove the factor of $1/p^*$ from the regret bounds, achieving significantly better regret bounds for influence maximization and cascading bandits than before. Finally, we provide lower bound results showing that the factor $1/p^*$ is unavoidable for general CMAB-T problems, suggesting that the TPM condition is crucial in removing this factor.
Combinatorial Multi-Armed Bandit and Its Extension to Probabilistically Triggered Arms
Mar 29, 2016We define a general framework for a large class of combinatorial multi-armed bandit (CMAB) problems, where subsets of base arms with unknown distributions form super arms. In each round, a super arm is played and the base arms contained in the super arm are played and their outcomes are observed. We further consider the extension in which more based arms could be probabilistically triggered based on the outcomes of already triggered arms. The reward of the super arm depends on the outcomes of all played arms, and it only needs to satisfy two mild assumptions, which allow a large class of nonlinear reward instances. We assume the availability of an offline (\alpha,\beta)-approximation oracle that takes the means of the outcome distributions of arms and outputs a super arm that with probability {\beta} generates an {\alpha} fraction of the optimal expected reward. The objective of an online learning algorithm for CMAB is to minimize (\alpha,\beta)-approximation regret, which is the difference between the \alpha{\beta} fraction of the expected reward when always playing the optimal super arm, and the expected reward of playing super arms according to the algorithm. We provide CUCB algorithm that achieves O(log n) distribution-dependent regret, where n is the number of rounds played, and we further provide distribution-independent bounds for a large class of reward functions. Our regret analysis is tight in that it matches the bound of UCB1 algorithm (up to a constant factor) for the classical MAB problem, and it significantly improves the regret bound in a earlier paper on combinatorial bandits with linear rewards. We apply our CMAB framework to two new applications, probabilistic maximum coverage and social influence maximization, both having nonlinear reward structures. In particular, application to social influence maximization requires our extension on probabilistically triggered arms.