 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitionNet: A Collaborative Neural Network for Play Style Discovery in Online Skill Gaming Platform
May 01, 2025Games are one of the safest source of realizing self-esteem and relaxation at the same time. An online gaming platform typically has massive data coming in, e.g., in-game actions, player moves, clickstreams, transactions etc. It is rather interesting, as something as simple as data on gaming moves can help create a psychological imprint of the user at that moment, based on her impulsive reactions and response to a situation in the game. Mining this knowledge can: (a) immediately help better explain observed and predicted player behavior; and (b) consequently propel deeper understanding towards players' experience, growth and protection. To this effect, we focus on discovery of the "game behaviours" as micro-patterns formed by continuous sequence of games and the persistent "play styles" of the players' as a sequence of such sequences on an online skill gaming platform for Rummy. We propose a two stage deep neural network, CognitionNet. The first stage focuses on mining game behaviours as cluster representations in a latent space while the second aggregates over these micro patterns to discover play styles via a supervised classification objective around player engagement. The dual objective allows CognitionNet to reveal several player psychology inspired decision making and tactics. To our knowledge, this is the first and one-of-its-kind research to fully automate the discovery of: (i) player psychology and game tactics from telemetry data; and (ii) relevant diagnostic explanations to players' engagement predictions. The collaborative training of the two networks with differential input dimensions is enabled using a novel formulation of "bridge loss". The network plays pivotal role in obtaining homogeneous and consistent play style definitions and significantly outperforms the SOTA baselines wherever applicable.
CROSS-JEM: Accurate and Efficient Cross-encoders for Short-text Ranking Tasks
Sep 15, 2024Ranking a set of items based on their relevance to a given query is a core problem in search and recommendation. Transformer-based ranking models are the state-of-the-art approaches for such tasks, but they score each query-item independently, ignoring the joint context of other relevant items. This leads to sub-optimal ranking accuracy and high computational costs. In response, we propose Cross-encoders with Joint Efficient Modeling (CROSS-JEM), a novel ranking approach that enables transformer-based models to jointly score multiple items for a query, maximizing parameter utilization. CROSS-JEM leverages (a) redundancies and token overlaps to jointly score multiple items, that are typically short-text phrases arising in search and recommendations, and (b) a novel training objective that models ranking probabilities. CROSS-JEM achieves state-of-the-art accuracy and over 4x lower ranking latency over standard cross-encoders. Our contributions are threefold: (i) we highlight the gap between the ranking application's need for scoring thousands of items per query and the limited capabilities of current cross-encoders; (ii) we introduce CROSS-JEM for joint efficient scoring of multiple items per query; and (iii) we demonstrate state-of-the-art accuracy on standard public datasets and a proprietary dataset. CROSS-JEM opens up new directions for designing tailored early-attention-based ranking models that incorporate strict production constraints such as item multiplicity and latency.
On the Necessity of World Knowledge for Mitigating Missing Labels in Extreme Classification
Aug 18, 2024Extreme Classification (XC) aims to map a query to the most relevant documents from a very large document set. XC algorithms used in real-world applications learn this mapping from datasets curated from implicit feedback, such as user clicks. However, these datasets inevitably suffer from missing labels. In this work, we observe that systematic missing labels lead to missing knowledge, which is critical for accurately modelling relevance between queries and documents. We formally show that this absence of knowledge cannot be recovered using existing methods such as propensity weighting and data imputation strategies that solely rely on the training dataset. While LLMs provide an attractive solution to augment the missing knowledge, leveraging them in applications with low latency requirements and large document sets is challenging. To incorporate missing knowledge at scale, we propose SKIM (Scalable Knowledge Infusion for Missing Labels), an algorithm that leverages a combination of small LM and abundant unstructured meta-data to effectively mitigate the missing label problem. We show the efficacy of our method on large-scale public datasets through exhaustive unbiased evaluation ranging from human annotations to simulations inspired from industrial settings. SKIM outperforms existing methods on Recall@100 by more than 10 absolute points. Additionally, SKIM scales to proprietary query-ad retrieval datasets containing 10 million documents, outperforming contemporary methods by 12% in offline evaluation and increased ad click-yield by 1.23% in an online A/B test conducted on a popular search engine. We release our code, prompts, trained XC models and finetuned SLMs at: https://github.com/bicycleman15/skim
Graph Regularized Encoder Training for Extreme Classification
Feb 28, 2024
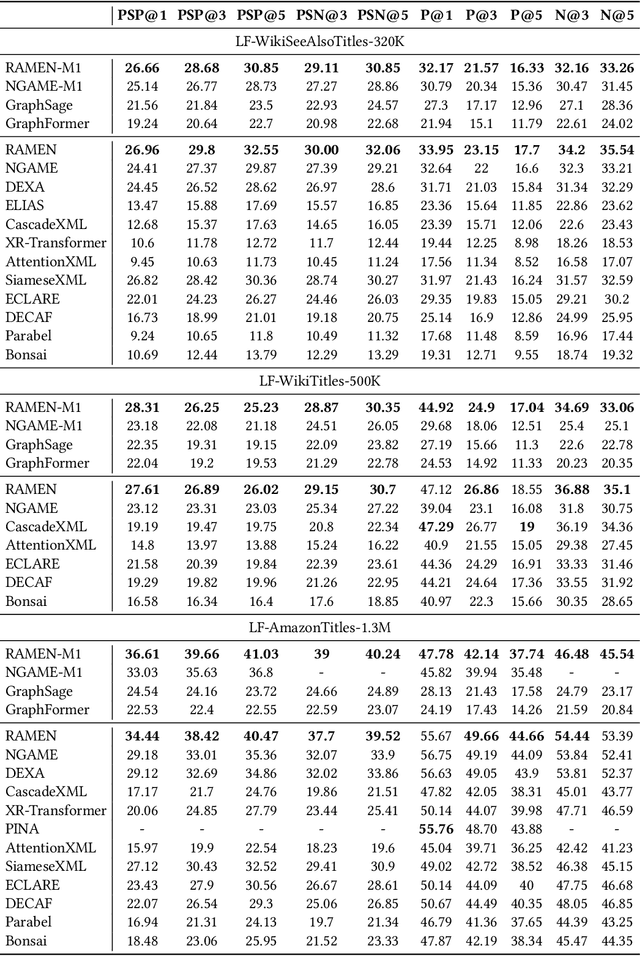
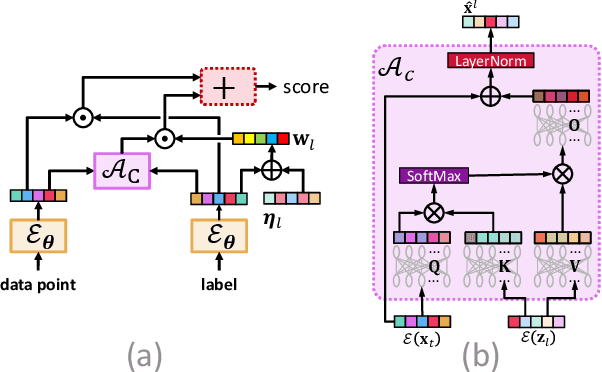
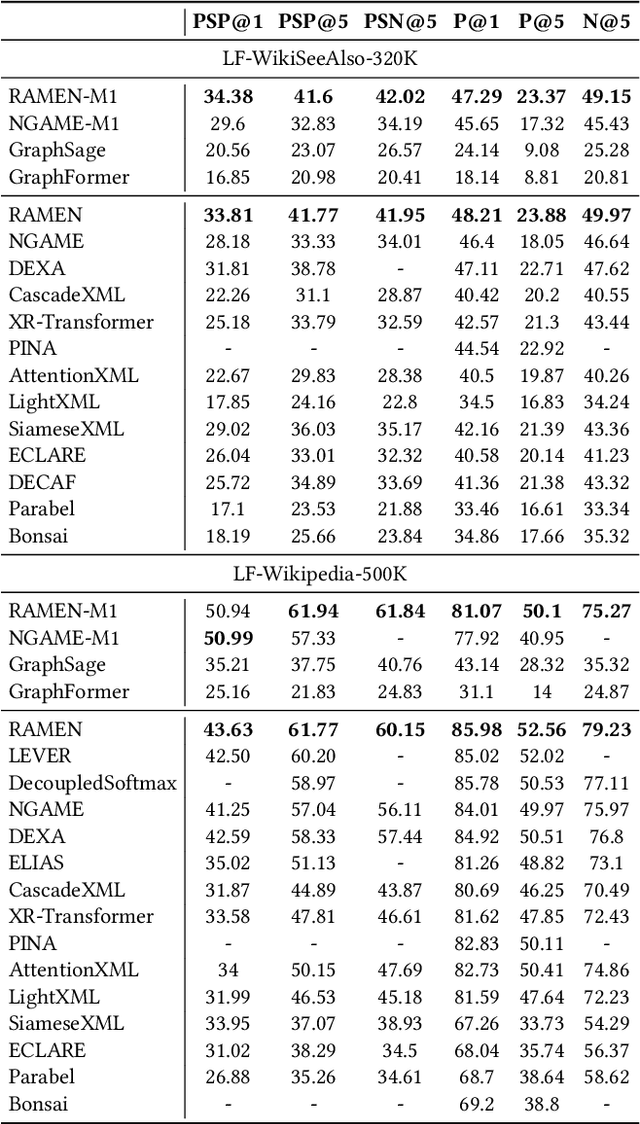
Deep extreme classification (XC) aims to train an encoder architecture and an accompanying classifier architecture to tag a data point with the most relevant subset of labels from a very large universe of labels. XC applications in ranking, recommendation and tagging routinely encounter tail labels for which the amount of training data is exceedingly small. Graph convolutional networks (GCN) present a convenient but computationally expensive way to leverage task metadata and enhance model accuracies in these settings. This paper formally establishes that in several use cases, the steep computational cost of GCNs is entirely avoidable by replacing GCNs with non-GCN architectures. The paper notices that in these settings, it is much more effective to use graph data to regularize encoder training than to implement a GCN. Based on these insights, an alternative paradigm RAMEN is presented to utilize graph metadata in XC settings that offers significant performance boosts with zero increase in inference computational costs. RAMEN scales to datasets with up to 1M labels and offers prediction accuracy up to 15% higher on benchmark datasets than state of the art methods, including those that use graph metadata to train GCNs. RAMEN also offers 10% higher accuracy over the best baseline on a proprietary recommendation dataset sourced from click logs of a popular search engine. Code for RAMEN will be released publicly.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022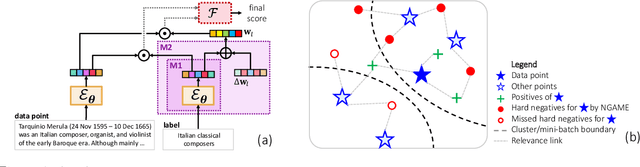
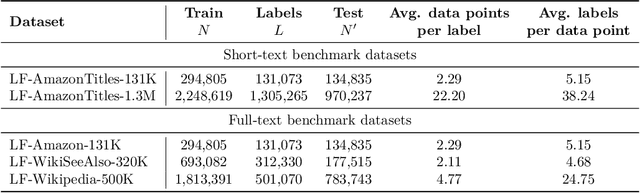
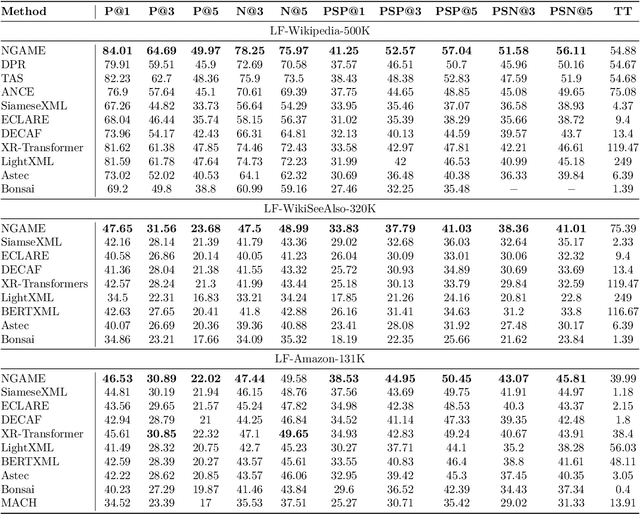
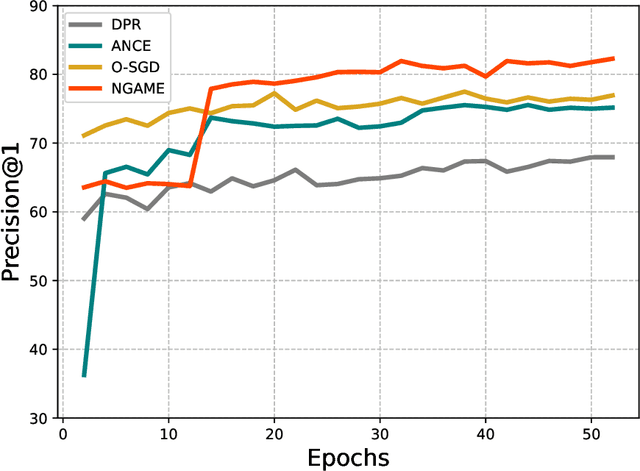
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
Nov 12, 2021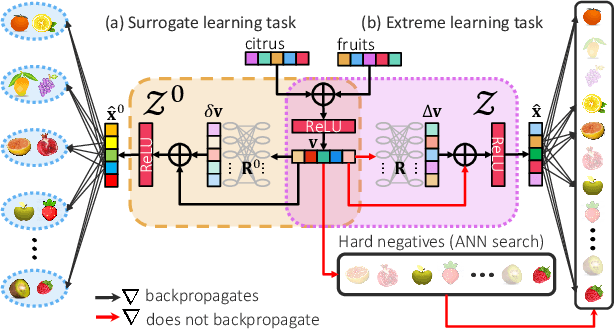
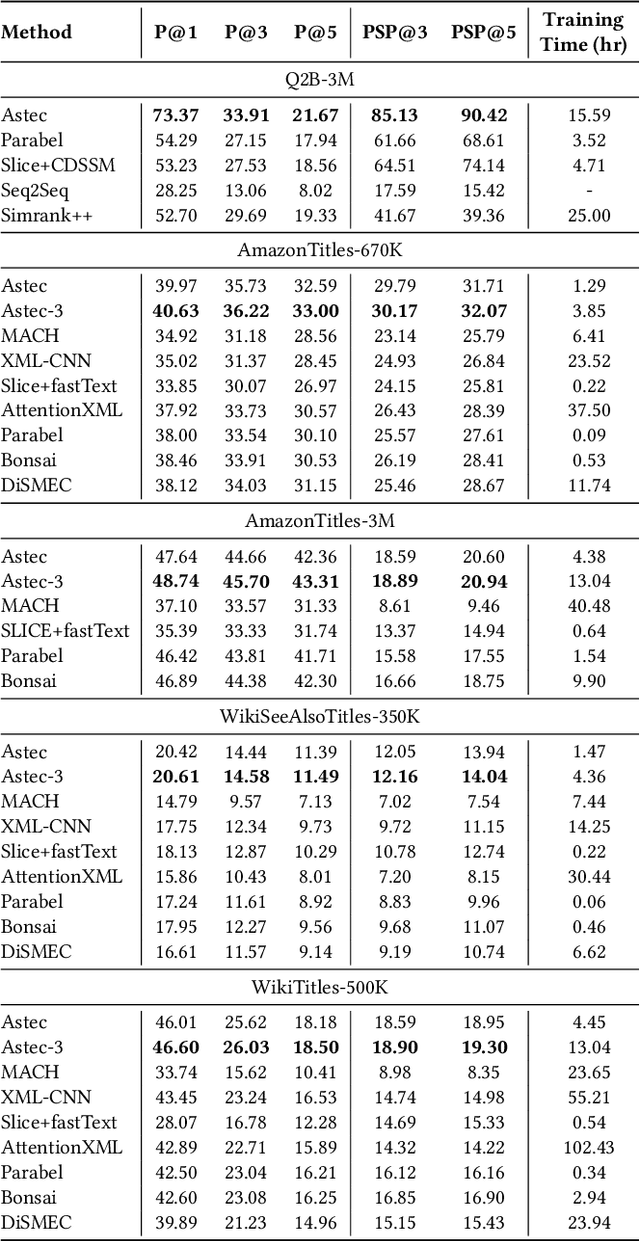

Scalability and accuracy are well recognized challenges in deep extreme multi-label learning where the objective is to train architectures for automatically annotating a data point with the most relevant subset of labels from an extremely large label set. This paper develops the DeepXML framework that addresses these challenges by decomposing the deep extreme multi-label task into four simpler sub-tasks each of which can be trained accurately and efficiently. Choosing different components for the four sub-tasks allows DeepXML to generate a family of algorithms with varying trade-offs between accuracy and scalability. In particular, DeepXML yields the Astec algorithm that could be 2-12% more accurate and 5-30x faster to train than leading deep extreme classifiers on publically available short text datasets. Astec could also efficiently train on Bing short text datasets containing up to 62 million labels while making predictions for billions of users and data points per day on commodity hardware. This allowed Astec to be deployed on the Bing search engine for a number of short text applications ranging from matching user queries to advertiser bid phrases to showing personalized ads where it yielded significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. DeepXML's code is available at https://github.com/Extreme-classification/deepxml
DECAF: Deep Extreme Classification with Label Features
Aug 01, 2021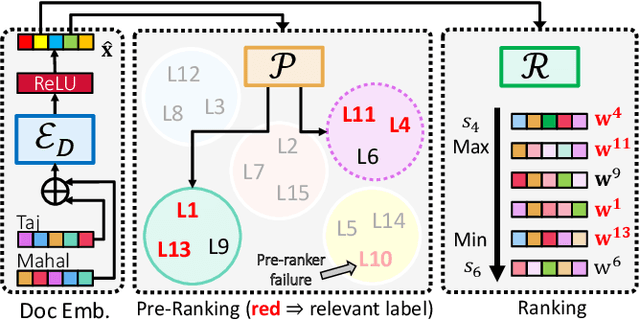
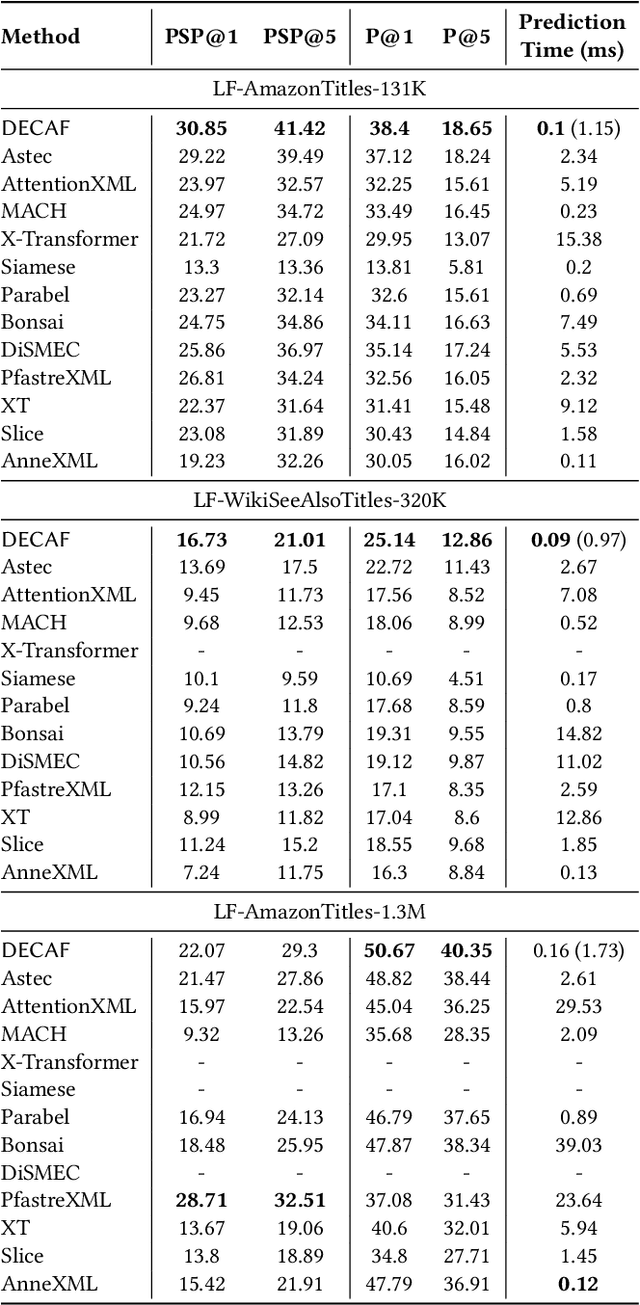
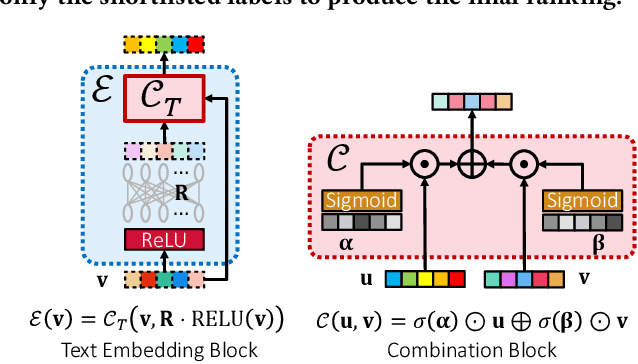
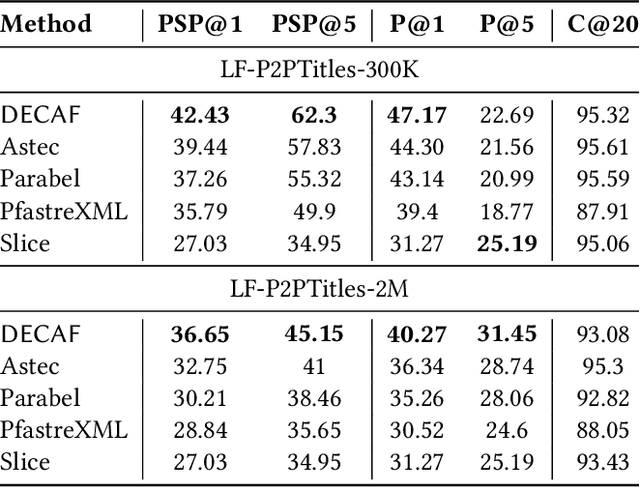
Extreme multi-label classification (XML) involves tagging a data point with its most relevant subset of labels from an extremely large label set, with several applications such as product-to-product recommendation with millions of products. Although leading XML algorithms scale to millions of labels, they largely ignore label meta-data such as textual descriptions of the labels. On the other hand, classical techniques that can utilize label metadata via representation learning using deep networks struggle in extreme settings. This paper develops the DECAF algorithm that addresses these challenges by learning models enriched by label metadata that jointly learn model parameters and feature representations using deep networks and offer accurate classification at the scale of millions of labels. DECAF makes specific contributions to model architecture design, initialization, and training, enabling it to offer up to 2-6% more accurate prediction than leading extreme classifiers on publicly available benchmark product-to-product recommendation datasets, such as LF-AmazonTitles-1.3M. At the same time, DECAF was found to be up to 22x faster at inference than leading deep extreme classifiers, which makes it suitable for real-time applications that require predictions within a few milliseconds. The code for DECAF is available at the following URL https://github.com/Extreme-classification/DECAF.