 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention and Compression is all you need for Controllably Efficient Language Models
Nov 07, 2025The quadratic cost of attention in transformers motivated the development of efficient approaches: namely sparse and sliding window attention, convolutions and linear attention. Although these approaches result in impressive reductions in compute and memory, they often trade-off with quality, specifically in-context recall performance. Moreover, apriori fixing this quality-compute tradeoff means being suboptimal from the get-go: some downstream applications require more memory for in-context recall, while others require lower latency and memory. Further, these approaches rely on heuristic choices that artificially restrict attention, or require handcrafted and complex recurrent state update rules, or they must be carefully composed with attention at specific layers to form a hybrid architecture that complicates the design process, especially at scale. To address above issues, we propose Compress & Attend Transformer (CAT), a conceptually simple architecture employing two simple ingredients only: dense attention and compression. CAT decodes chunks of tokens by attending to compressed chunks of the sequence so far. Compression results in decoding from a reduced sequence length that yields compute and memory savings, while choosing a particular chunk size trades-off quality for efficiency. Moreover, CAT can be trained with multiple chunk sizes at once, unlocking control of quality-compute trade-offs directly at test-time without any retraining, all in a single adaptive architecture. In exhaustive evaluations on common language modeling tasks, in-context recall, and long-context understanding, a single adaptive CAT model outperforms existing efficient baselines, including hybrid architectures, across different compute-memory budgets. Further, a single CAT matches dense transformer in language modeling across model scales while being 1.4-3x faster and requiring 2-9x lower total memory usage.
KL-Regularized Reinforcement Learning is Designed to Mode Collapse
Oct 23, 2025It is commonly believed that optimizing the reverse KL divergence results in "mode seeking", while optimizing forward KL results in "mass covering", with the latter being preferred if the goal is to sample from multiple diverse modes. We show -- mathematically and empirically -- that this intuition does not necessarily transfer well to doing reinforcement learning with reverse/forward KL regularization (e.g. as commonly used with language models). Instead, the choice of reverse/forward KL determines the family of optimal target distributions, parameterized by the regularization coefficient. Mode coverage depends primarily on other factors, such as regularization strength, and relative scales between rewards and reference probabilities. Further, we show commonly used settings such as low regularization strength and equal verifiable rewards tend to specify unimodal target distributions, meaning the optimization objective is, by construction, non-diverse. We leverage these insights to construct a simple, scalable, and theoretically justified algorithm. It makes minimal changes to reward magnitudes, yet optimizes for a target distribution which puts high probability over all high-quality sampling modes. In experiments, this simple modification works to post-train both Large Language Models and Chemical Language Models to have higher solution quality and diversity, without any external signals of diversity, and works with both forward and reverse KL when using either naively fails.
On the Necessity of World Knowledge for Mitigating Missing Labels in Extreme Classification
Aug 18, 2024Extreme Classification (XC) aims to map a query to the most relevant documents from a very large document set. XC algorithms used in real-world applications learn this mapping from datasets curated from implicit feedback, such as user clicks. However, these datasets inevitably suffer from missing labels. In this work, we observe that systematic missing labels lead to missing knowledge, which is critical for accurately modelling relevance between queries and documents. We formally show that this absence of knowledge cannot be recovered using existing methods such as propensity weighting and data imputation strategies that solely rely on the training dataset. While LLMs provide an attractive solution to augment the missing knowledge, leveraging them in applications with low latency requirements and large document sets is challenging. To incorporate missing knowledge at scale, we propose SKIM (Scalable Knowledge Infusion for Missing Labels), an algorithm that leverages a combination of small LM and abundant unstructured meta-data to effectively mitigate the missing label problem. We show the efficacy of our method on large-scale public datasets through exhaustive unbiased evaluation ranging from human annotations to simulations inspired from industrial settings. SKIM outperforms existing methods on Recall@100 by more than 10 absolute points. Additionally, SKIM scales to proprietary query-ad retrieval datasets containing 10 million documents, outperforming contemporary methods by 12% in offline evaluation and increased ad click-yield by 1.23% in an online A/B test conducted on a popular search engine. We release our code, prompts, trained XC models and finetuned SLMs at: https://github.com/bicycleman15/skim
A Novel Data Augmentation Technique for Out-of-Distribution Sample Detection using Compounded Corruptions
Jul 28, 2022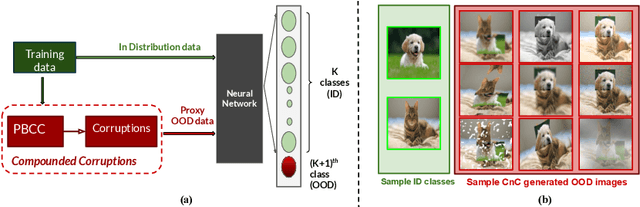
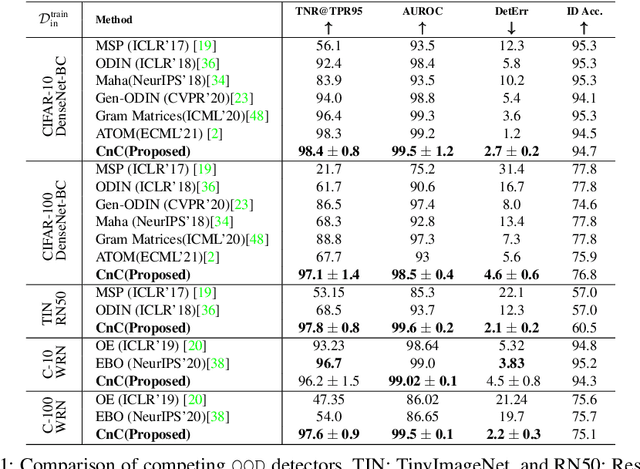
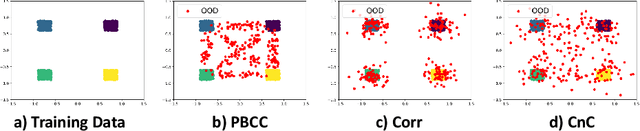
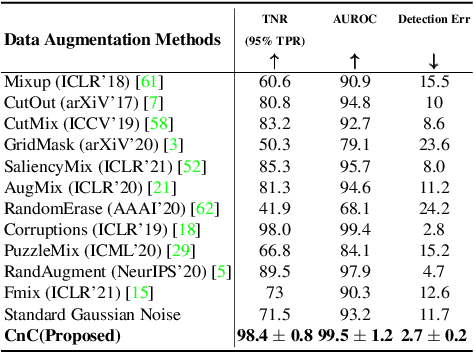
Modern deep neural network models are known to erroneously classify out-of-distribution (OOD) test data into one of the in-distribution (ID) training classes with high confidence. This can have disastrous consequences for safety-critical applications. A popular mitigation strategy is to train a separate classifier that can detect such OOD samples at the test time. In most practical settings OOD examples are not known at the train time, and hence a key question is: how to augment the ID data with synthetic OOD samples for training such an OOD detector? In this paper, we propose a novel Compounded Corruption technique for the OOD data augmentation termed CnC. One of the major advantages of CnC is that it does not require any hold-out data apart from the training set. Further, unlike current state-of-the-art (SOTA) techniques, CnC does not require backpropagation or ensembling at the test time, making our method much faster at inference. Our extensive comparison with 20 methods from the major conferences in last 4 years show that a model trained using CnC based data augmentation, significantly outperforms SOTA, both in terms of OOD detection accuracy as well as inference time. We include a detailed post-hoc analysis to investigate the reasons for the success of our method and identify higher relative entropy and diversity of CnC samples as probable causes. We also provide theoretical insights via a piece-wise decomposition analysis on a two-dimensional dataset to reveal (visually and quantitatively) that our approach leads to a tighter boundary around ID classes, leading to better detection of OOD samples. Source code link: https://github.com/cnc-ood
A Stitch in Time Saves Nine: A Train-Time Regularizing Loss for Improved Neural Network Calibration
Mar 25, 2022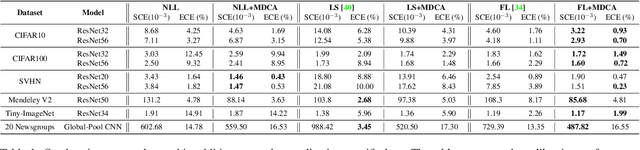
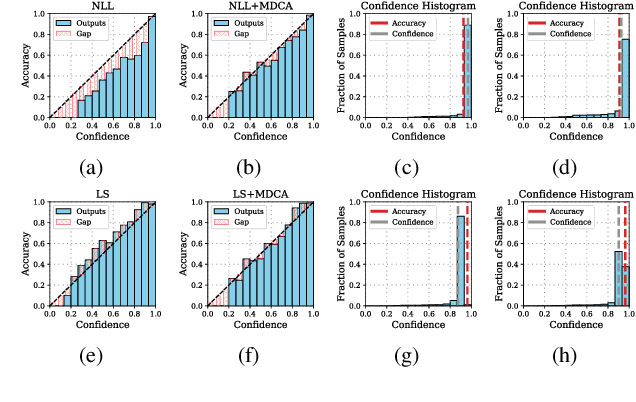
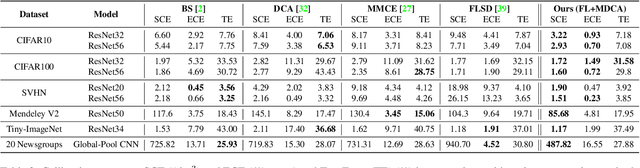
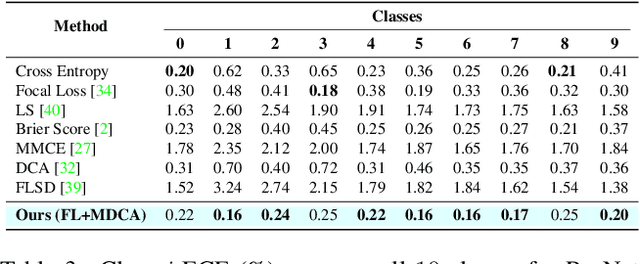
Deep Neural Networks ( DNN s) are known to make overconfident mistakes, which makes their use problematic in safety-critical applications. State-of-the-art ( SOTA ) calibration techniques improve on the confidence of predicted labels alone and leave the confidence of non-max classes (e.g. top-2, top-5) uncalibrated. Such calibration is not suitable for label refinement using post-processing. Further, most SOTA techniques learn a few hyper-parameters post-hoc, leaving out the scope for image, or pixel specific calibration. This makes them unsuitable for calibration under domain shift, or for dense prediction tasks like semantic segmentation. In this paper, we argue for intervening at the train time itself, so as to directly produce calibrated DNN models. We propose a novel auxiliary loss function: Multi-class Difference in Confidence and Accuracy ( MDCA ), to achieve the same MDCA can be used in conjunction with other application/task-specific loss functions. We show that training with MDCA leads to better-calibrated models in terms of Expected Calibration Error ( ECE ), and Static Calibration Error ( SCE ) on image classification, and segmentation tasks. We report ECE ( SCE ) score of 0.72 (1.60) on the CIFAR 100 dataset, in comparison to 1.90 (1.71) by the SOTA. Under domain shift, a ResNet-18 model trained on PACS dataset using MDCA gives an average ECE ( SCE ) score of 19.7 (9.7) across all domains, compared to 24.2 (11.8) by the SOTA. For the segmentation task, we report a 2X reduction in calibration error on PASCAL - VOC dataset in comparison to Focal Loss. Finally, MDCA training improves calibration even on imbalanced data, and for natural language classification tasks. We have released the code here: code is available at https://github.com/mdca-loss