 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicking Human Visual Development for Learning Robust Image Representations
Dec 16, 2025The human visual system is remarkably adept at adapting to changes in the input distribution; a capability modern convolutional neural networks (CNNs) still struggle to match. Drawing inspiration from the developmental trajectory of human vision, we propose a progressive blurring curriculum to improve the generalization and robustness of CNNs. Human infants are born with poor visual acuity, gradually refining their ability to perceive fine details. Mimicking this process, we begin training CNNs on highly blurred images during the initial epochs and progressively reduce the blur as training advances. This approach encourages the network to prioritize global structures over high-frequency artifacts, improving robustness against distribution shifts and noisy inputs. Challenging prior claims that blurring in the initial training epochs imposes a stimulus deficit and irreversibly harms model performance, we reveal that early-stage blurring enhances generalization with minimal impact on in-domain accuracy. Our experiments demonstrate that the proposed curriculum reduces mean corruption error (mCE) by up to 8.30% on CIFAR-10-C and 4.43% on ImageNet-100-C datasets, compared to standard training without blurring. Unlike static blur-based augmentation, which applies blurred images randomly throughout training, our method follows a structured progression, yielding consistent gains across various datasets. Furthermore, our approach complements other augmentation techniques, such as CutMix and MixUp, and enhances both natural and adversarial robustness against common attack methods. Code is available at https://github.com/rajankita/Visual_Acuity_Curriculum.
Backdoor Attacks on Open Vocabulary Object Detectors via Multi-Modal Prompt Tuning
Nov 16, 2025Open-vocabulary object detectors (OVODs) unify vision and language to detect arbitrary object categories based on text prompts, enabling strong zero-shot generalization to novel concepts. As these models gain traction in high-stakes applications such as robotics, autonomous driving, and surveillance, understanding their security risks becomes crucial. In this work, we conduct the first study of backdoor attacks on OVODs and reveal a new attack surface introduced by prompt tuning. We propose TrAP (Trigger-Aware Prompt tuning), a multi-modal backdoor injection strategy that jointly optimizes prompt parameters in both image and text modalities along with visual triggers. TrAP enables the attacker to implant malicious behavior using lightweight, learnable prompt tokens without retraining the base model weights, thus preserving generalization while embedding a hidden backdoor. We adopt a curriculum-based training strategy that progressively shrinks the trigger size, enabling effective backdoor activation using small trigger patches at inference. Experiments across multiple datasets show that TrAP achieves high attack success rates for both object misclassification and object disappearance attacks, while also improving clean image performance on downstream datasets compared to the zero-shot setting.
microCLIP: Unsupervised CLIP Adaptation via Coarse-Fine Token Fusion for Fine-Grained Image Classification
Oct 02, 2025Unsupervised adaptation of CLIP-based vision-language models (VLMs) for fine-grained image classification requires sensitivity to microscopic local cues. While CLIP exhibits strong zero-shot transfer, its reliance on coarse global features restricts its performance on fine-grained classification tasks. Prior efforts inject fine-grained knowledge by aligning large language model (LLM) descriptions with the CLIP $\texttt{[CLS]}$ token; however, this approach overlooks spatial precision. We propose $\textbf{microCLIP}$, a self-training framework that jointly refines CLIP's visual and textual representations using fine-grained cues. At its core is Saliency-Oriented Attention Pooling (SOAP) within a lightweight TokenFusion module, which builds a saliency-guided $\texttt{[FG]}$ token from patch embeddings and fuses it with the global $\texttt{[CLS]}$ token for coarse-fine alignment. To stabilize adaptation, we introduce a two-headed LLM-derived classifier: a frozen classifier that, via multi-view alignment, provides a stable text-based prior for pseudo-labeling, and a learnable classifier initialized from LLM descriptions and fine-tuned with TokenFusion. We further develop Dynamic Knowledge Aggregation, which convexly combines fixed LLM/CLIP priors with TokenFusion's evolving logits to iteratively refine pseudo-labels. Together, these components uncover latent fine-grained signals in CLIP, yielding a consistent $2.90\%$ average accuracy gain across 13 fine-grained benchmarks while requiring only light adaptation. Our code is available at https://github.com/sathiiii/microCLIP.
Why Stop at Words? Unveiling the Bigger Picture through Line-Level OCR
Aug 29, 2025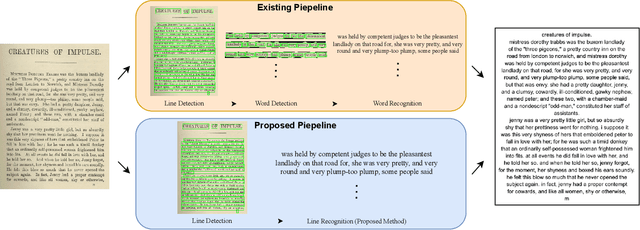
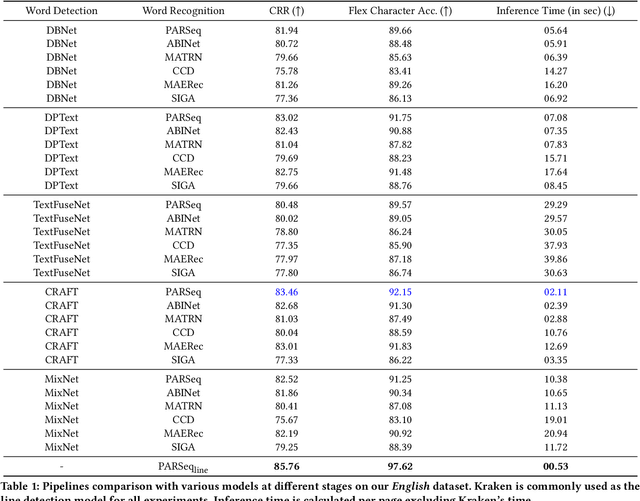

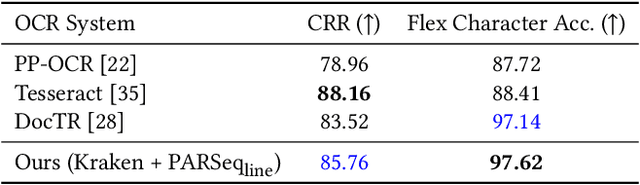
Conventional optical character recognition (OCR) techniques segmented each character and then recognized. This made them prone to error in character segmentation, and devoid of context to exploit language models. Advances in sequence to sequence translation in last decade led to modern techniques first detecting words and then inputting one word at a time to a model to directly output full words as sequence of characters. This allowed better utilization of language models and bypass error-prone character segmentation step. We observe that the above transition in style has moved the bottleneck in accuracy to word segmentation. Hence, in this paper, we propose a natural and logical progression from word level OCR to line-level OCR. The proposal allows to bypass errors in word detection, and provides larger sentence context for better utilization of language models. We show that the proposed technique not only improves the accuracy but also efficiency of OCR. Despite our thorough literature survey, we did not find any public dataset to train and benchmark such shift from word to line-level OCR. Hence, we also contribute a meticulously curated dataset of 251 English page images with line-level annotations. Our experimentation revealed a notable end-to-end accuracy improvement of 5.4%, underscoring the potential benefits of transitioning towards line-level OCR, especially for document images. We also report a 4 times improvement in efficiency compared to word-based pipelines. With continuous improvements in large language models, our methodology also holds potential to exploit such advances. Project Website: https://nishitanand.github.io/line-level-ocr-website
Identifying Physically Realizable Triggers for Backdoored Face Recognition Networks
Jun 24, 2025


Backdoor attacks embed a hidden functionality into deep neural networks, causing the network to display anomalous behavior when activated by a predetermined pattern in the input Trigger, while behaving well otherwise on public test data. Recent works have shown that backdoored face recognition (FR) systems can respond to natural-looking triggers like a particular pair of sunglasses. Such attacks pose a serious threat to the applicability of FR systems in high-security applications. We propose a novel technique to (1) detect whether an FR network is compromised with a natural, physically realizable trigger, and (2) identify such triggers given a compromised network. We demonstrate the effectiveness of our methods with a compromised FR network, where we are able to identify the trigger (e.g., green sunglasses or red hat) with a top-5 accuracy of 74%, whereas a naive brute force baseline achieves 56% accuracy.
Assessing Risk of Stealing Proprietary Models for Medical Imaging Tasks
Jun 24, 2025The success of deep learning in medical imaging applications has led several companies to deploy proprietary models in diagnostic workflows, offering monetized services. Even though model weights are hidden to protect the intellectual property of the service provider, these models are exposed to model stealing (MS) attacks, where adversaries can clone the model's functionality by querying it with a proxy dataset and training a thief model on the acquired predictions. While extensively studied on general vision tasks, the susceptibility of medical imaging models to MS attacks remains inadequately explored. This paper investigates the vulnerability of black-box medical imaging models to MS attacks under realistic conditions where the adversary lacks access to the victim model's training data and operates with limited query budgets. We demonstrate that adversaries can effectively execute MS attacks by using publicly available datasets. To further enhance MS capabilities with limited query budgets, we propose a two-step model stealing approach termed QueryWise. This method capitalizes on unlabeled data obtained from a proxy distribution to train the thief model without incurring additional queries. Evaluation on two medical imaging models for Gallbladder Cancer and COVID-19 classification substantiates the effectiveness of the proposed attack. The source code is available at https://github.com/rajankita/QueryWise.
Use of Metric Learning for the Recognition of Handwritten Digits, and its Application to Increase the Outreach of Voice-based Communication Platforms
Apr 26, 2025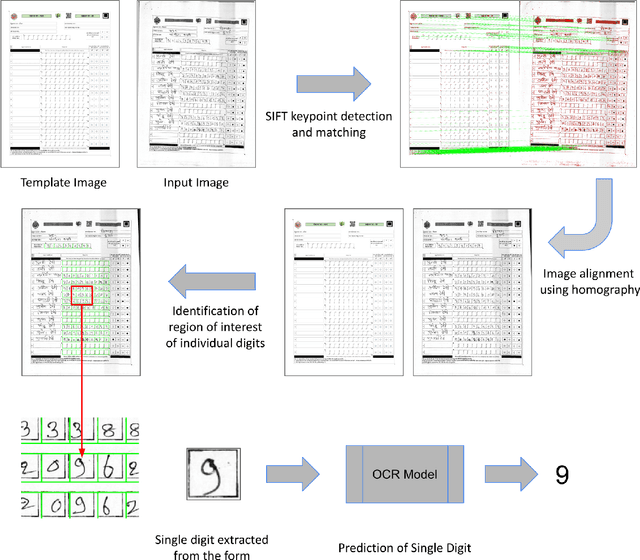
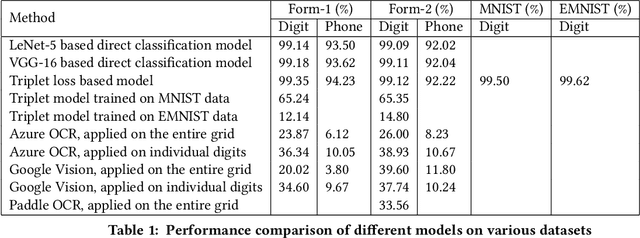

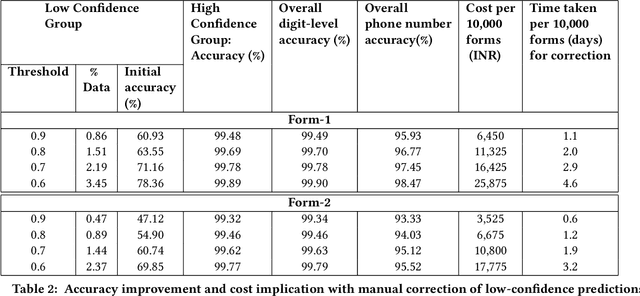
Initiation, monitoring, and evaluation of development programmes can involve field-based data collection about project activities. This data collection through digital devices may not always be feasible though, for reasons such as unaffordability of smartphones and tablets by field-based cadre, or shortfalls in their training and capacity building. Paper-based data collection has been argued to be more appropriate in several contexts, with automated digitization of the paper forms through OCR (Optical Character Recognition) and OMR (Optical Mark Recognition) techniques. We contribute with providing a large dataset of handwritten digits, and deep learning based models and methods built using this data, that are effective in real-world environments. We demonstrate the deployment of these tools in the context of a maternal and child health and nutrition awareness project, which uses IVR (Interactive Voice Response) systems to provide awareness information to rural women SHG (Self Help Group) members in north India. Paper forms were used to collect phone numbers of the SHG members at scale, which were digitized using the OCR tools developed by us, and used to push almost 4 million phone calls. The data, model, and code have been released in the open-source domain.
* 10 Pages, 7 Figures, ACM COMPASS 2022
Examining the Threat Landscape: Foundation Models and Model Stealing
Feb 25, 2025
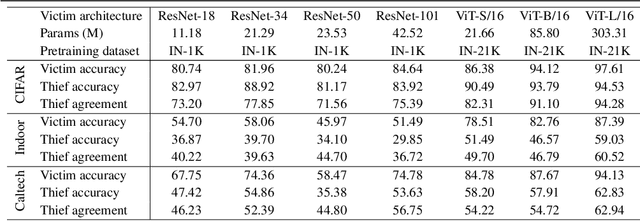


Foundation models (FMs) for computer vision learn rich and robust representations, enabling their adaptation to task/domain-specific deployments with little to no fine-tuning. However, we posit that the very same strength can make applications based on FMs vulnerable to model stealing attacks. Through empirical analysis, we reveal that models fine-tuned from FMs harbor heightened susceptibility to model stealing, compared to conventional vision architectures like ResNets. We hypothesize that this behavior is due to the comprehensive encoding of visual patterns and features learned by FMs during pre-training, which are accessible to both the attacker and the victim. We report that an attacker is able to obtain 94.28% agreement (matched predictions with victim) for a Vision Transformer based victim model (ViT-L/16) trained on CIFAR-10 dataset, compared to only 73.20% agreement for a ResNet-18 victim, when using ViT-L/16 as the thief model. We arguably show, for the first time, that utilizing FMs for downstream tasks may not be the best choice for deployment in commercial APIs due to their susceptibility to model theft. We thereby alert model owners towards the associated security risks, and highlight the need for robust security measures to safeguard such models against theft. Code is available at https://github.com/rajankita/foundation_model_stealing.
Feature Space Perturbation: A Panacea to Enhanced Transferability Estimation
Feb 23, 2025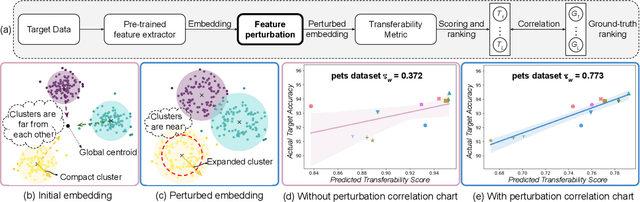
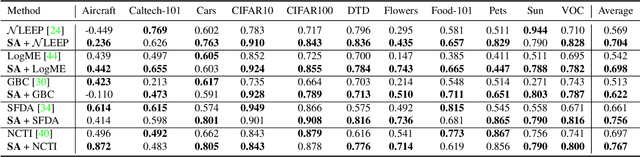

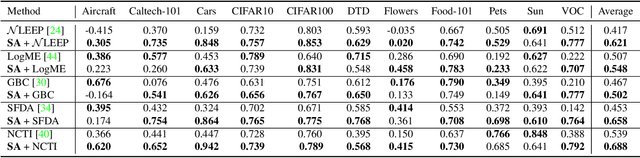
Leveraging a transferability estimation metric facilitates the non-trivial challenge of selecting the optimal model for the downstream task from a pool of pre-trained models. Most existing metrics primarily focus on identifying the statistical relationship between feature embeddings and the corresponding labels within the target dataset, but overlook crucial aspect of model robustness. This oversight may limit their effectiveness in accurately ranking pre-trained models. To address this limitation, we introduce a feature perturbation method that enhances the transferability estimation process by systematically altering the feature space. Our method includes a Spread operation that increases intra-class variability, adding complexity within classes, and an Attract operation that minimizes the distances between different classes, thereby blurring the class boundaries. Through extensive experimentation, we demonstrate the efficacy of our feature perturbation method in providing a more precise and robust estimation of model transferability. Notably, the existing LogMe method exhibited a significant improvement, showing a 28.84% increase in performance after applying our feature perturbation method.
LQ-Adapter: ViT-Adapter with Learnable Queries for Gallbladder Cancer Detection from Ultrasound Image
Nov 30, 2024We focus on the problem of Gallbladder Cancer (GBC) detection from Ultrasound (US) images. The problem presents unique challenges to modern Deep Neural Network (DNN) techniques due to low image quality arising from noise, textures, and viewpoint variations. Tackling such challenges would necessitate precise localization performance by the DNN to identify the discerning features for the downstream malignancy prediction. While several techniques have been proposed in the recent years for the problem, all of these methods employ complex custom architectures. Inspired by the success of foundational models for natural image tasks, along with the use of adapters to fine-tune such models for the custom tasks, we investigate the merit of one such design, ViT-Adapter, for the GBC detection problem. We observe that ViT-Adapter relies predominantly on a primitive CNN-based spatial prior module to inject the localization information via cross-attention, which is inefficient for our problem due to the small pathology sizes, and variability in their appearances due to non-regular structure of the malignancy. In response, we propose, LQ-Adapter, a modified Adapter design for ViT, which improves localization information by leveraging learnable content queries over the basic spatial prior module. Our method surpasses existing approaches, enhancing the mean IoU (mIoU) scores by 5.4%, 5.8%, and 2.7% over ViT-Adapters, DINO, and FocalNet-DINO, respectively on the US image-based GBC detection dataset, and establishing a new state-of-the-art (SOTA). Additionally, we validate the applicability and effectiveness of LQ-Adapter on the Kvasir-Seg dataset for polyp detection from colonoscopy images. Superior performance of our design on this problem as well showcases its capability to handle diverse medical imaging tasks across different datasets. Code is released at https://github.com/ChetanMadan/LQ-Adapter