 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Third Monocular Depth Estimation Challenge
Apr 27, 2024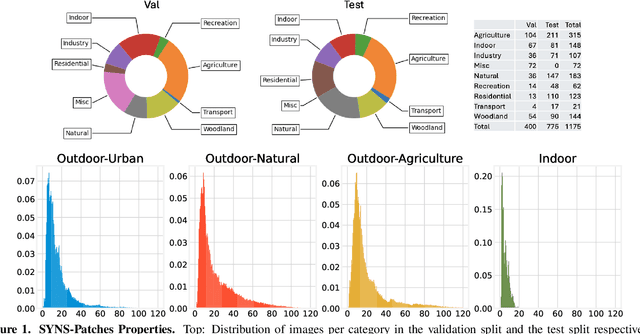

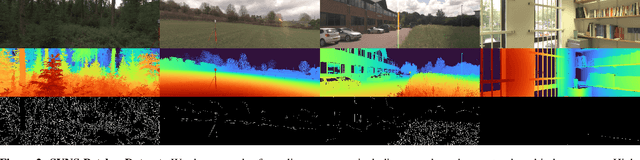
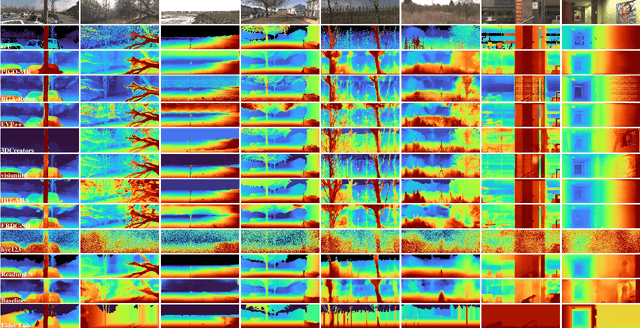
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
ECoDepth: Effective Conditioning of Diffusion Models for Monocular Depth Estimation
Apr 01, 2024



In the absence of parallax cues, a learning-based single image depth estimation (SIDE) model relies heavily on shading and contextual cues in the image. While this simplicity is attractive, it is necessary to train such models on large and varied datasets, which are difficult to capture. It has been shown that using embeddings from pre-trained foundational models, such as CLIP, improves zero shot transfer in several applications. Taking inspiration from this, in our paper we explore the use of global image priors generated from a pre-trained ViT model to provide more detailed contextual information. We argue that the embedding vector from a ViT model, pre-trained on a large dataset, captures greater relevant information for SIDE than the usual route of generating pseudo image captions, followed by CLIP based text embeddings. Based on this idea, we propose a new SIDE model using a diffusion backbone which is conditioned on ViT embeddings. Our proposed design establishes a new state-of-the-art (SOTA) for SIDE on NYUv2 dataset, achieving Abs Rel error of 0.059(14% improvement) compared to 0.069 by the current SOTA (VPD). And on KITTI dataset, achieving Sq Rel error of 0.139 (2% improvement) compared to 0.142 by the current SOTA (GEDepth). For zero-shot transfer with a model trained on NYUv2, we report mean relative improvement of (20%, 23%, 81%, 25%) over NeWCRFs on (Sun-RGBD, iBims1, DIODE, HyperSim) datasets, compared to (16%, 18%, 45%, 9%) by ZoeDepth. The project page is available at https://ecodepth-iitd.github.io
FinderNet: A Data Augmentation Free Canonicalization aided Loop Detection and Closure technique for Point clouds in 6-DOF separation
Apr 03, 2023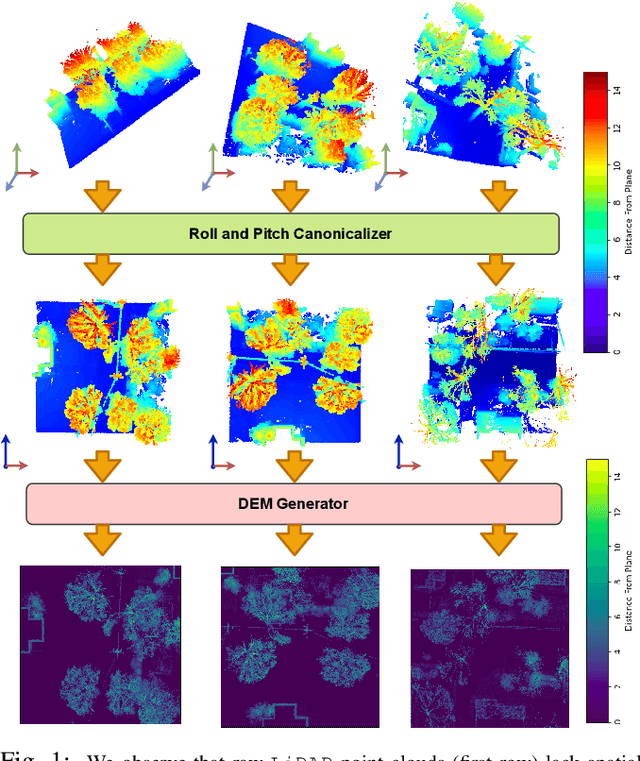
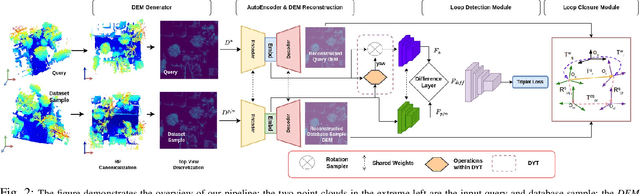
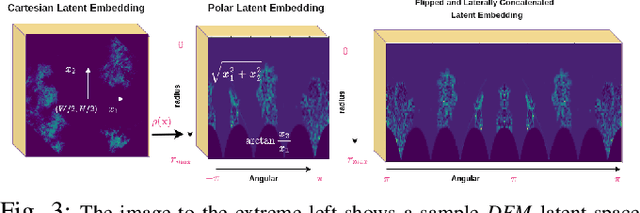
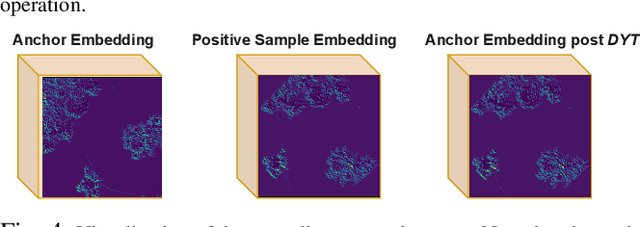
We focus on the problem of LiDAR point cloud based loop detection (or Finding) and closure (LDC) in a multi-agent setting. State-of-the-art (SOTA) techniques directly generate learned embeddings of a given point cloud, require large data transfers, and are not robust to wide variations in 6 Degrees-of-Freedom (DOF) viewpoint. Moreover, absence of strong priors in an unstructured point cloud leads to highly inaccurate LDC. In this original approach, we propose independent roll and pitch canonicalization of the point clouds using a common dominant ground plane. Discretization of the canonicalized point cloud along the axis perpendicular to the ground plane leads to an image similar to Digital Elevation Maps (DEMs), which exposes strong spatial priors in the scene. Our experiments show that LDC based on learnt embeddings of such DEMs is not only data efficient but also significantly more robust, and generalizable than the current SOTA. We report significant performance gain in terms of Average Precision for loop detection and absolute translation/rotation error for relative pose estimation (or loop closure) on Kitti, GPR and Oxford Robot Car over multiple SOTA LDC methods. Our encoder technique allows to compress the original point cloud by over 830 times. To further test the robustness of our technique we create and opensource a custom dataset called Lidar-UrbanFly Dataset (LUF) which consists of point clouds obtained from a LiDAR mounted on a quadrotor.