 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Global Localization using Multi-Modal Object-Instance Re-Identification
Sep 18, 2024Re-identification (ReID) is a critical challenge in computer vision, predominantly studied in the context of pedestrians and vehicles. However, robust object-instance ReID, which has significant implications for tasks such as autonomous exploration, long-term perception, and scene understanding, remains underexplored. In this work, we address this gap by proposing a novel dual-path object-instance re-identification transformer architecture that integrates multimodal RGB and depth information. By leveraging depth data, we demonstrate improvements in ReID across scenes that are cluttered or have varying illumination conditions. Additionally, we develop a ReID-based localization framework that enables accurate camera localization and pose identification across different viewpoints. We validate our methods using two custom-built RGB-D datasets, as well as multiple sequences from the open-source TUM RGB-D datasets. Our approach demonstrates significant improvements in both object instance ReID (mAP of 75.18) and localization accuracy (success rate of 83% on TUM-RGBD), highlighting the essential role of object ReID in advancing robotic perception. Our models, frameworks, and datasets have been made publicly available.
FinderNet: A Data Augmentation Free Canonicalization aided Loop Detection and Closure technique for Point clouds in 6-DOF separation
Apr 03, 2023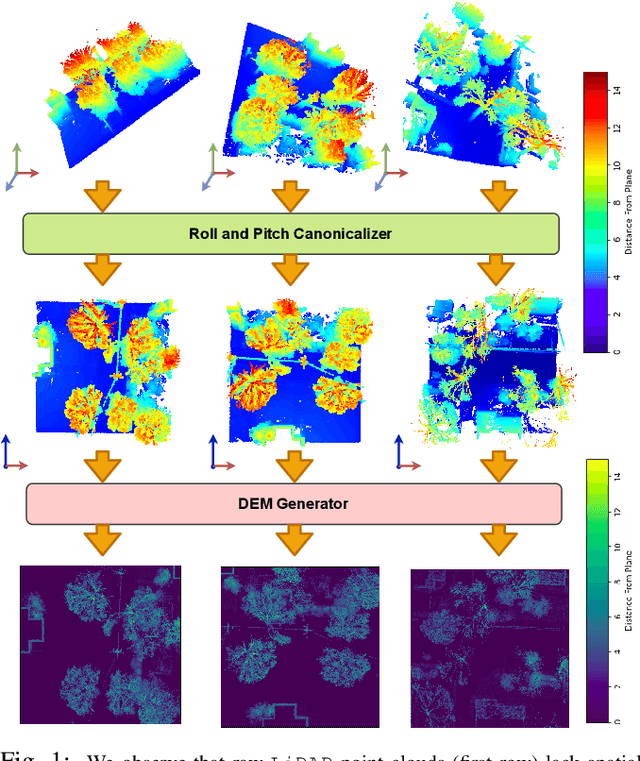
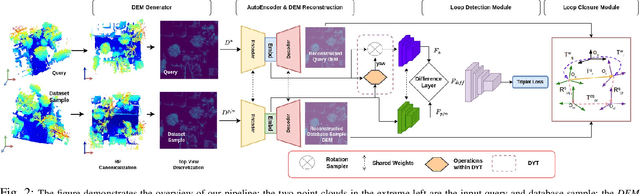
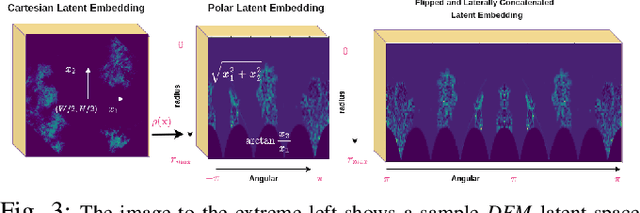
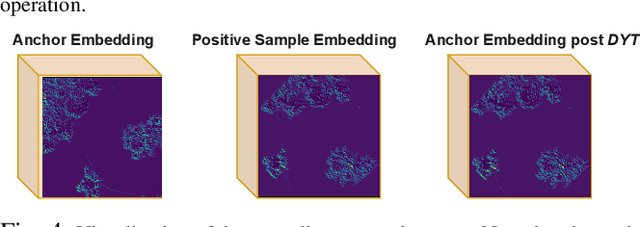
We focus on the problem of LiDAR point cloud based loop detection (or Finding) and closure (LDC) in a multi-agent setting. State-of-the-art (SOTA) techniques directly generate learned embeddings of a given point cloud, require large data transfers, and are not robust to wide variations in 6 Degrees-of-Freedom (DOF) viewpoint. Moreover, absence of strong priors in an unstructured point cloud leads to highly inaccurate LDC. In this original approach, we propose independent roll and pitch canonicalization of the point clouds using a common dominant ground plane. Discretization of the canonicalized point cloud along the axis perpendicular to the ground plane leads to an image similar to Digital Elevation Maps (DEMs), which exposes strong spatial priors in the scene. Our experiments show that LDC based on learnt embeddings of such DEMs is not only data efficient but also significantly more robust, and generalizable than the current SOTA. We report significant performance gain in terms of Average Precision for loop detection and absolute translation/rotation error for relative pose estimation (or loop closure) on Kitti, GPR and Oxford Robot Car over multiple SOTA LDC methods. Our encoder technique allows to compress the original point cloud by over 830 times. To further test the robustness of our technique we create and opensource a custom dataset called Lidar-UrbanFly Dataset (LUF) which consists of point clouds obtained from a LiDAR mounted on a quadrotor.