 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Finish Search: Efficient Test-Time Scaling in Large Language Models
May 23, 2025Test-time scaling (TTS), which involves dynamic allocation of compute during inference, offers a promising way to improve reasoning in large language models. While existing TTS methods work well, they often rely on long decoding paths or require a large number of samples to be generated, increasing the token usage and inference latency. We observe the surprising fact that for reasoning tasks, shorter traces are much more likely to be correct than longer ones. Motivated by this, we introduce First Finish Search (FFS), a training-free parallel decoding strategy that launches $n$ independent samples and returns as soon as any one completes. We evaluate FFS alongside simple decoding, beam search, majority voting, and budget forcing on four reasoning models (DeepSeek-R1, R1-Distill-Qwen-32B, QwQ-32B and Phi-4-Reasoning-Plus) and across four datasets (AIME24, AIME25-I, AIME25-II and GPQA Diamond). With DeepSeek-R1, FFS achieves $82.23\%$ accuracy on the AIME datasets, a $15\%$ improvement over DeepSeek-R1's standalone accuracy, nearly matching OpenAI's o4-mini performance. Our theoretical analysis explains why stopping at the shortest trace is likely to yield a correct answer and identifies the conditions under which early stopping may be suboptimal. The elegance and simplicity of FFS demonstrate that straightforward TTS strategies can perform remarkably well, revealing the untapped potential of simple approaches at inference time.
Step-by-Step Unmasking for Parameter-Efficient Fine-tuning of Large Language Models
Aug 27, 2024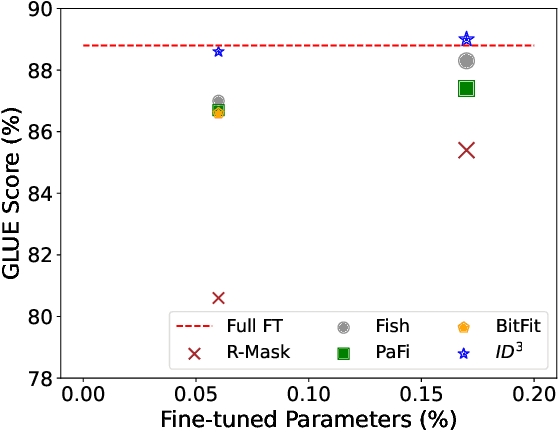
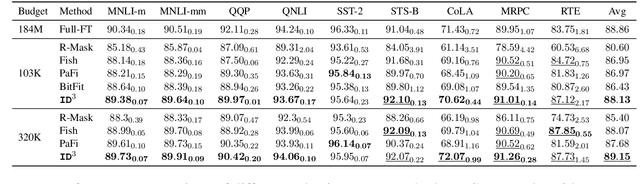

Fine-tuning large language models (LLMs) on downstream tasks requires substantial computational resources. A class of parameter-efficient fine-tuning (PEFT) aims to mitigate these computational challenges by selectively fine-tuning only a small fraction of the model parameters. Although computationally efficient, these techniques often fail to match the performance of fully fine-tuned models, primarily due to inherent biases introduced during parameter selection. Traditional selective PEFT techniques use a fixed set of parameters based on a predefined budget (a process also known as unmasking), failing to capture parameter importance dynamically and often ending up exceeding the budget. We introduce $\text{ID}^3$, a novel selective PEFT method that calculates parameter importance continually and dynamically unmasks parameters by balancing exploration and exploitation in parameter selection. Our empirical study on 15 tasks spanning natural language understanding and generative tasks demonstrates the effectiveness of our method compared to fixed-masking-based PEFT techniques. We analytically show that $\text{ID}^3$ reduces the number of gradient updates by a factor of two, enhancing computational efficiency. $\text{ID}^3$ is robust to random initialization of neurons and, therefore, can be seamlessly integrated into existing additive and reparametrization-based PEFT modules such as adapters and LoRA for dynamic sparsification.
The Third Monocular Depth Estimation Challenge
Apr 27, 2024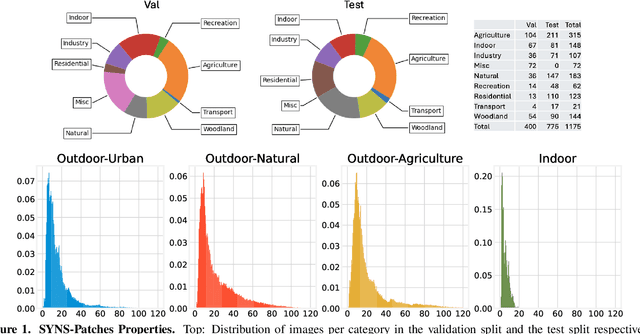

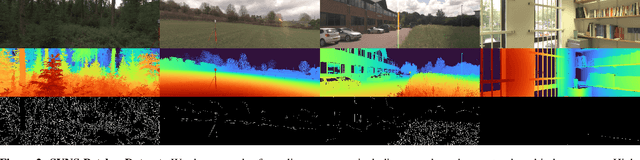
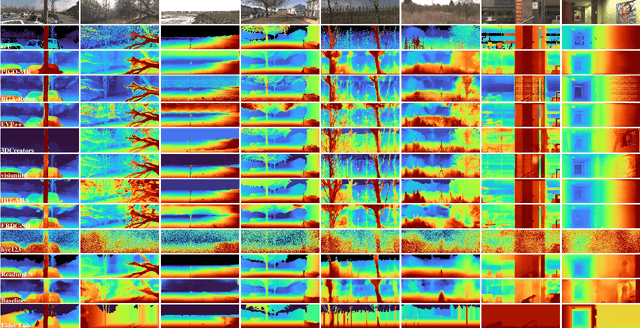
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
ECoDepth: Effective Conditioning of Diffusion Models for Monocular Depth Estimation
Apr 01, 2024



In the absence of parallax cues, a learning-based single image depth estimation (SIDE) model relies heavily on shading and contextual cues in the image. While this simplicity is attractive, it is necessary to train such models on large and varied datasets, which are difficult to capture. It has been shown that using embeddings from pre-trained foundational models, such as CLIP, improves zero shot transfer in several applications. Taking inspiration from this, in our paper we explore the use of global image priors generated from a pre-trained ViT model to provide more detailed contextual information. We argue that the embedding vector from a ViT model, pre-trained on a large dataset, captures greater relevant information for SIDE than the usual route of generating pseudo image captions, followed by CLIP based text embeddings. Based on this idea, we propose a new SIDE model using a diffusion backbone which is conditioned on ViT embeddings. Our proposed design establishes a new state-of-the-art (SOTA) for SIDE on NYUv2 dataset, achieving Abs Rel error of 0.059(14% improvement) compared to 0.069 by the current SOTA (VPD). And on KITTI dataset, achieving Sq Rel error of 0.139 (2% improvement) compared to 0.142 by the current SOTA (GEDepth). For zero-shot transfer with a model trained on NYUv2, we report mean relative improvement of (20%, 23%, 81%, 25%) over NeWCRFs on (Sun-RGBD, iBims1, DIODE, HyperSim) datasets, compared to (16%, 18%, 45%, 9%) by ZoeDepth. The project page is available at https://ecodepth-iitd.github.io