 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP Architecture for Abdominal CT Image-Text Alignment and Zero-Shot Learning: Investigating Batch Composition and Data Scaling
Apr 15, 2026Vision-language models trained with contrastive learning on paired medical images and reports show strong zero-shot diagnostic capabilities, yet the effect of training batch composition on learned representations remains unexplored for 3D medical imaging. We reproduce Merlin, a dual-encoder model that aligns 3D abdominal CT volumes with radiology reports using symmetric InfoNCE loss, achieving a zero-shot macro F1 of 74.45% across 30 findings (original: 73.00%). We then investigate two axes of variation. First, we control the normal-to-abnormal ratio within training batches at 25:75, 50:50, and 75:25 using section-level balanced sampling on the full dataset. All three configurations underperform the unbalanced baseline by 2.4 to 2.8 points, with 75:25 achieving the best result (72.02%) among balanced variants. Second, we conduct data scaling ablations on a 4,362-study subset, training with 20%, 40%, and 100% of the data. Performance scales sub-linearly from 65.26% to 71.88%, with individual findings varying dramatically in data sensitivity. Enforcing 50:50 balanced sampling on the same subset further degrades performance to 68.01%, confirming that explicit class balancing hurts regardless of dataset or balancing granularity. Our results indicate that the stochastic diversity of random sampling, combined with Merlin's alternating batching over anatomical subsections, provides more effective regularization than engineered class ratios at the small batch sizes required by 3D medical volumes.
Performance of a Deep Learning-Based Segmentation Model for Pancreatic Tumors on Public Endoscopic Ultrasound Datasets
Jan 09, 2026Background: Pancreatic cancer is one of the most aggressive cancers, with poor survival rates. Endoscopic ultrasound (EUS) is a key diagnostic modality, but its effectiveness is constrained by operator subjectivity. This study evaluates a Vision Transformer-based deep learning segmentation model for pancreatic tumors. Methods: A segmentation model using the USFM framework with a Vision Transformer backbone was trained and validated with 17,367 EUS images (from two public datasets) in 5-fold cross-validation. The model was tested on an independent dataset of 350 EUS images from another public dataset, manually segmented by radiologists. Preprocessing included grayscale conversion, cropping, and resizing to 512x512 pixels. Metrics included Dice similarity coefficient (DSC), intersection over union (IoU), sensitivity, specificity, and accuracy. Results: In 5-fold cross-validation, the model achieved a mean DSC of 0.651 +/- 0.738, IoU of 0.579 +/- 0.658, sensitivity of 69.8%, specificity of 98.8%, and accuracy of 97.5%. For the external validation set, the model achieved a DSC of 0.657 (95% CI: 0.634-0.769), IoU of 0.614 (95% CI: 0.590-0.689), sensitivity of 71.8%, and specificity of 97.7%. Results were consistent, but 9.7% of cases exhibited erroneous multiple predictions. Conclusions: The Vision Transformer-based model demonstrated strong performance for pancreatic tumor segmentation in EUS images. However, dataset heterogeneity and limited external validation highlight the need for further refinement, standardization, and prospective studies.
Multi-RADS Synthetic Radiology Report Dataset and Head-to-Head Benchmarking of 41 Open-Weight and Proprietary Language Models
Jan 06, 2026Background: Reporting and Data Systems (RADS) standardize radiology risk communication but automated RADS assignment from narrative reports is challenging because of guideline complexity, output-format constraints, and limited benchmarking across RADS frameworks and model sizes. Purpose: To create RXL-RADSet, a radiologist-verified synthetic multi-RADS benchmark, and compare validity and accuracy of open-weight small language models (SLMs) with a proprietary model for RADS assignment. Materials and Methods: RXL-RADSet contains 1,600 synthetic radiology reports across 10 RADS (BI-RADS, CAD-RADS, GB-RADS, LI-RADS, Lung-RADS, NI-RADS, O-RADS, PI-RADS, TI-RADS, VI-RADS) and multiple modalities. Reports were generated by LLMs using scenario plans and simulated radiologist styles and underwent two-stage radiologist verification. We evaluated 41 quantized SLMs (12 families, 0.135-32B parameters) and GPT-5.2 under a fixed guided prompt. Primary endpoints were validity and accuracy; a secondary analysis compared guided versus zero-shot prompting. Results: Under guided prompting GPT-5.2 achieved 99.8% validity and 81.1% accuracy (1,600 predictions). Pooled SLMs (65,600 predictions) achieved 96.8% validity and 61.1% accuracy; top SLMs in the 20-32B range reached ~99% validity and mid-to-high 70% accuracy. Performance scaled with model size (inflection between <1B and >=10B) and declined with RADS complexity primarily due to classification difficulty rather than invalid outputs. Guided prompting improved validity (99.2% vs 96.7%) and accuracy (78.5% vs 69.6%) compared with zero-shot. Conclusion: RXL-RADSet provides a radiologist-verified multi-RADS benchmark; large SLMs (20-32B) can approach proprietary-model performance under guided prompting, but gaps remain for higher-complexity schemes.
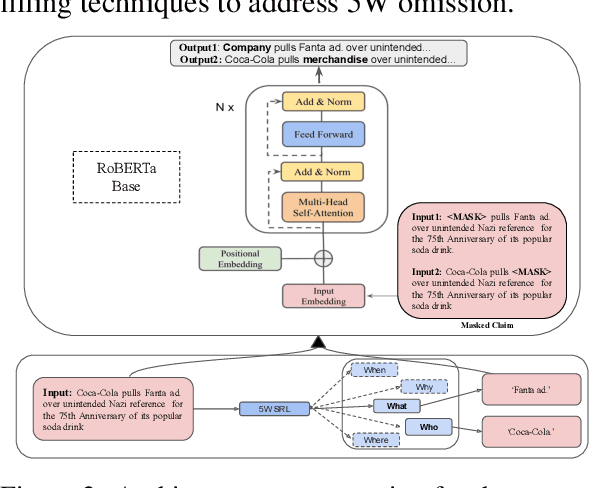
Musings About the Future of Search: A Return to the Past?
Dec 25, 2024When you have a question, the most effective way to have the question answered is to directly connect with experts on the topic and have a conversation with them. Prior to the invention of writing, this was the only way. Although effective, this solution exhibits scalability challenges. Writing allowed knowledge to be materialized, preserved, and replicated, enabling the development of different technologies over the centuries to connect information seekers with relevant information. This progression ultimately culminated in the ten-blue-links web search paradigm we're familiar with, just before the recent emergence of generative AI. However, we often forget that consuming static content is an imperfect solution. With the advent of large language models, it has become possible to develop a superior experience by allowing users to directly engage with experts. These interactions can of course satisfy information needs, but expert models can do so much more. This coming future requires reimagining search.
LQ-Adapter: ViT-Adapter with Learnable Queries for Gallbladder Cancer Detection from Ultrasound Image
Nov 30, 2024We focus on the problem of Gallbladder Cancer (GBC) detection from Ultrasound (US) images. The problem presents unique challenges to modern Deep Neural Network (DNN) techniques due to low image quality arising from noise, textures, and viewpoint variations. Tackling such challenges would necessitate precise localization performance by the DNN to identify the discerning features for the downstream malignancy prediction. While several techniques have been proposed in the recent years for the problem, all of these methods employ complex custom architectures. Inspired by the success of foundational models for natural image tasks, along with the use of adapters to fine-tune such models for the custom tasks, we investigate the merit of one such design, ViT-Adapter, for the GBC detection problem. We observe that ViT-Adapter relies predominantly on a primitive CNN-based spatial prior module to inject the localization information via cross-attention, which is inefficient for our problem due to the small pathology sizes, and variability in their appearances due to non-regular structure of the malignancy. In response, we propose, LQ-Adapter, a modified Adapter design for ViT, which improves localization information by leveraging learnable content queries over the basic spatial prior module. Our method surpasses existing approaches, enhancing the mean IoU (mIoU) scores by 5.4%, 5.8%, and 2.7% over ViT-Adapters, DINO, and FocalNet-DINO, respectively on the US image-based GBC detection dataset, and establishing a new state-of-the-art (SOTA). Additionally, we validate the applicability and effectiveness of LQ-Adapter on the Kvasir-Seg dataset for polyp detection from colonoscopy images. Superior performance of our design on this problem as well showcases its capability to handle diverse medical imaging tasks across different datasets. Code is released at https://github.com/ChetanMadan/LQ-Adapter
FocusMAE: Gallbladder Cancer Detection from Ultrasound Videos with Focused Masked Autoencoders
Mar 29, 2024In recent years, automated Gallbladder Cancer (GBC) detection has gained the attention of researchers. Current state-of-the-art (SOTA) methodologies relying on ultrasound sonography (US) images exhibit limited generalization, emphasizing the need for transformative approaches. We observe that individual US frames may lack sufficient information to capture disease manifestation. This study advocates for a paradigm shift towards video-based GBC detection, leveraging the inherent advantages of spatiotemporal representations. Employing the Masked Autoencoder (MAE) for representation learning, we address shortcomings in conventional image-based methods. We propose a novel design called FocusMAE to systematically bias the selection of masking tokens from high-information regions, fostering a more refined representation of malignancy. Additionally, we contribute the most extensive US video dataset for GBC detection. We also note that, this is the first study on US video-based GBC detection. We validate the proposed methods on the curated dataset, and report a new state-of-the-art (SOTA) accuracy of 96.4% for the GBC detection problem, against an accuracy of 84% by current Image-based SOTA - GBCNet, and RadFormer, and 94.7% by Video-based SOTA - AdaMAE. We further demonstrate the generality of the proposed FocusMAE on a public CT-based Covid detection dataset, reporting an improvement in accuracy by 3.3% over current baselines. The source code and pretrained models are available at: https://gbc-iitd.github.io/focusmae
SEPSIS: I Can Catch Your Lies -- A New Paradigm for Deception Detection
Dec 01, 2023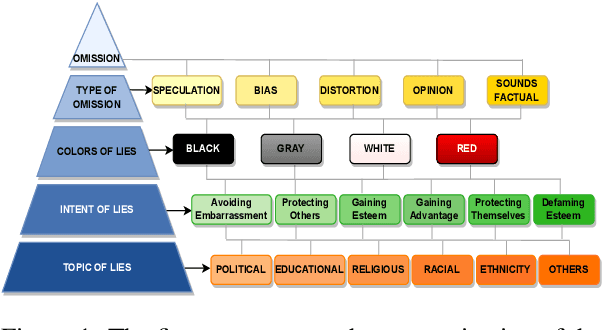


Deception is the intentional practice of twisting information. It is a nuanced societal practice deeply intertwined with human societal evolution, characterized by a multitude of facets. This research explores the problem of deception through the lens of psychology, employing a framework that categorizes deception into three forms: lies of omission, lies of commission, and lies of influence. The primary focus of this study is specifically on investigating only lies of omission. We propose a novel framework for deception detection leveraging NLP techniques. We curated an annotated dataset of 876,784 samples by amalgamating a popular large-scale fake news dataset and scraped news headlines from the Twitter handle of Times of India, a well-known Indian news media house. Each sample has been labeled with four layers, namely: (i) the type of omission (speculation, bias, distortion, sounds factual, and opinion), (ii) colors of lies(black, white, etc), and (iii) the intention of such lies (to influence, etc) (iv) topic of lies (political, educational, religious, etc). We present a novel multi-task learning pipeline that leverages the dataless merging of fine-tuned language models to address the deception detection task mentioned earlier. Our proposed model achieved an F1 score of 0.87, demonstrating strong performance across all layers including the type, color, intent, and topic aspects of deceptive content. Finally, our research explores the relationship between lies of omission and propaganda techniques. To accomplish this, we conducted an in-depth analysis, uncovering compelling findings. For instance, our analysis revealed a significant correlation between loaded language and opinion, shedding light on their interconnectedness. To encourage further research in this field, we will be making the models and dataset available with the MIT License, making it favorable for open-source research.
Gall Bladder Cancer Detection from US Images with Only Image Level Labels
Sep 11, 2023



Automated detection of Gallbladder Cancer (GBC) from Ultrasound (US) images is an important problem, which has drawn increased interest from researchers. However, most of these works use difficult-to-acquire information such as bounding box annotations or additional US videos. In this paper, we focus on GBC detection using only image-level labels. Such annotation is usually available based on the diagnostic report of a patient, and do not require additional annotation effort from the physicians. However, our analysis reveals that it is difficult to train a standard image classification model for GBC detection. This is due to the low inter-class variance (a malignant region usually occupies only a small portion of a US image), high intra-class variance (due to the US sensor capturing a 2D slice of a 3D object leading to large viewpoint variations), and low training data availability. We posit that even when we have only the image level label, still formulating the problem as object detection (with bounding box output) helps a deep neural network (DNN) model focus on the relevant region of interest. Since no bounding box annotations is available for training, we pose the problem as weakly supervised object detection (WSOD). Motivated by the recent success of transformer models in object detection, we train one such model, DETR, using multi-instance-learning (MIL) with self-supervised instance selection to suit the WSOD task. Our proposed method demonstrates an improvement of AP and detection sensitivity over the SOTA transformer-based and CNN-based WSOD methods. Project page is at https://gbc-iitd.github.io/wsod-gbc
Adversarial Adaptation for French Named Entity Recognition
Jan 12, 2023

Named Entity Recognition (NER) is the task of identifying and classifying named entities in large-scale texts into predefined classes. NER in French and other relatively limited-resource languages cannot always benefit from approaches proposed for languages like English due to a dearth of large, robust datasets. In this paper, we present our work that aims to mitigate the effects of this dearth of large, labeled datasets. We propose a Transformer-based NER approach for French, using adversarial adaptation to similar domain or general corpora to improve feature extraction and enable better generalization. Our approach allows learning better features using large-scale unlabeled corpora from the same domain or mixed domains to introduce more variations during training and reduce overfitting. Experimental results on three labeled datasets show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of Transformer models, source datasets, and target corpora. We also show that adversarial adaptation to large-scale unlabeled corpora can help mitigate the performance dip incurred on using Transformer models pre-trained on smaller corpora.
Transformer-Based Named Entity Recognition for French Using Adversarial Adaptation to Similar Domain Corpora
Dec 05, 2022
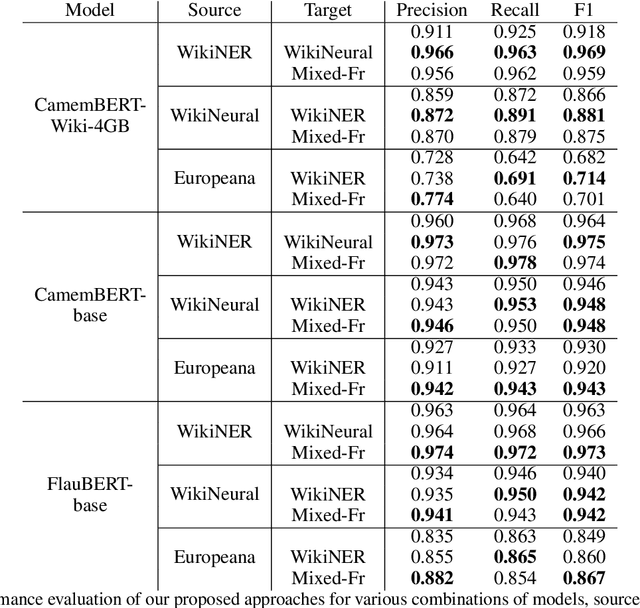
Named Entity Recognition (NER) involves the identification and classification of named entities in unstructured text into predefined classes. NER in languages with limited resources, like French, is still an open problem due to the lack of large, robust, labelled datasets. In this paper, we propose a transformer-based NER approach for French using adversarial adaptation to similar domain or general corpora for improved feature extraction and better generalization. We evaluate our approach on three labelled datasets and show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of transformer models, source datasets and target corpora.