 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Continual Learning for Text Classification via Selective Inter-client Transfer
Oct 12, 2022
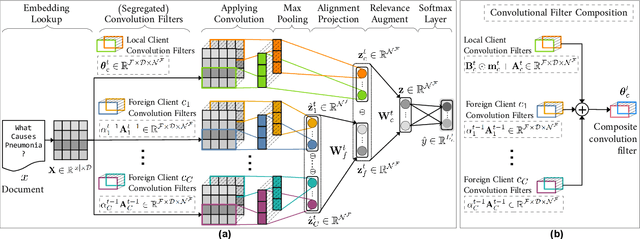
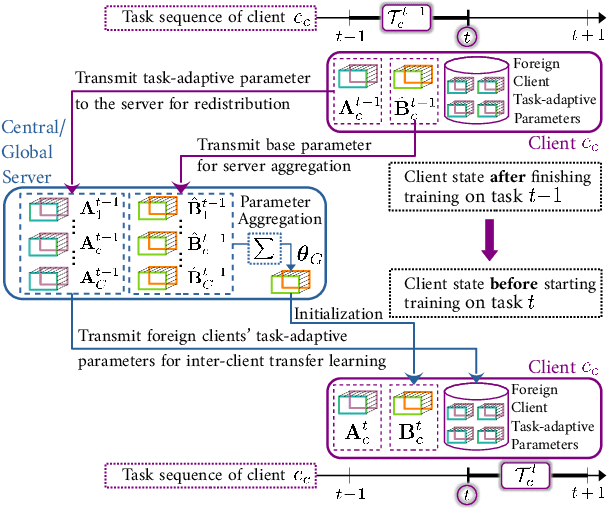
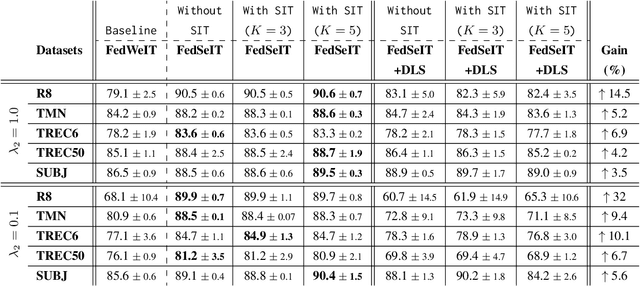
In this work, we combine the two paradigms: Federated Learning (FL) and Continual Learning (CL) for text classification task in cloud-edge continuum. The objective of Federated Continual Learning (FCL) is to improve deep learning models over life time at each client by (relevant and efficient) knowledge transfer without sharing data. Here, we address challenges in minimizing inter-client interference while knowledge sharing due to heterogeneous tasks across clients in FCL setup. In doing so, we propose a novel framework, Federated Selective Inter-client Transfer (FedSeIT) which selectively combines model parameters of foreign clients. To further maximize knowledge transfer, we assess domain overlap and select informative tasks from the sequence of historical tasks at each foreign client while preserving privacy. Evaluating against the baselines, we show improved performance, a gain of (average) 12.4\% in text classification over a sequence of tasks using five datasets from diverse domains. To the best of our knowledge, this is the first work that applies FCL to NLP.
Multi-source Neural Topic Modeling in Multi-view Embedding Spaces
Apr 17, 2021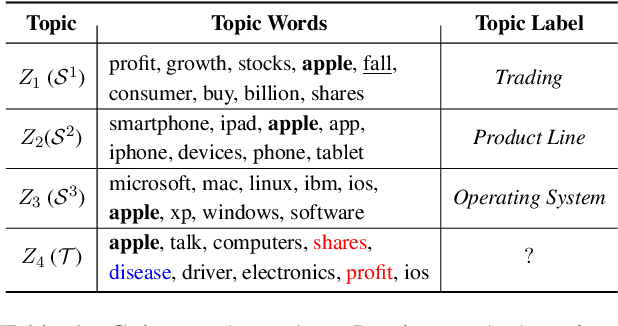
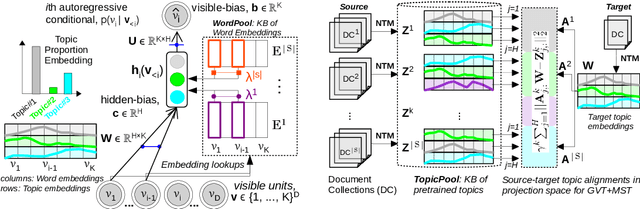

Though word embeddings and topics are complementary representations, several past works have only used pretrained word embeddings in (neural) topic modeling to address data sparsity in short-text or small collection of documents. This work presents a novel neural topic modeling framework using multi-view embedding spaces: (1) pretrained topic-embeddings, and (2) pretrained word-embeddings (context insensitive from Glove and context-sensitive from BERT models) jointly from one or many sources to improve topic quality and better deal with polysemy. In doing so, we first build respective pools of pretrained topic (i.e., TopicPool) and word embeddings (i.e., WordPool). We then identify one or more relevant source domain(s) and transfer knowledge to guide meaningful learning in the sparse target domain. Within neural topic modeling, we quantify the quality of topics and document representations via generalization (perplexity), interpretability (topic coherence) and information retrieval (IR) using short-text, long-text, small and large document collections from news and medical domains. Introducing the multi-source multi-view embedding spaces, we have shown state-of-the-art neural topic modeling using 6 source (high-resource) and 5 target (low-resource) corpora.
TopicBERT for Energy Efficient Document Classification
Oct 15, 2020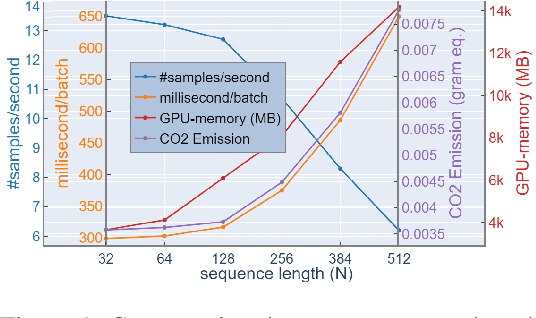


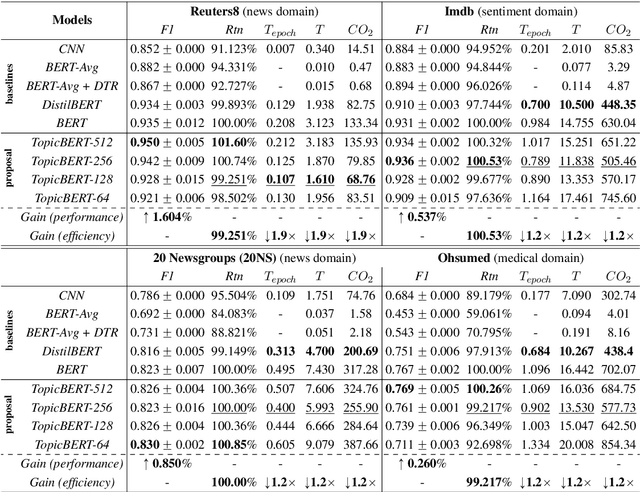
Prior research notes that BERT's computational cost grows quadratically with sequence length thus leading to longer training times, higher GPU memory constraints and carbon emissions. While recent work seeks to address these scalability issues at pre-training, these issues are also prominent in fine-tuning especially for long sequence tasks like document classification. Our work thus focuses on optimizing the computational cost of fine-tuning for document classification. We achieve this by complementary learning of both topic and language models in a unified framework, named TopicBERT. This significantly reduces the number of self-attention operations - a main performance bottleneck. Consequently, our model achieves a 1.4x ($\sim40\%$) speedup with $\sim40\%$ reduction in $CO_2$ emission while retaining $99.9\%$ performance over 5 datasets.
Explainable and Discourse Topic-aware Neural Language Understanding
Jun 19, 2020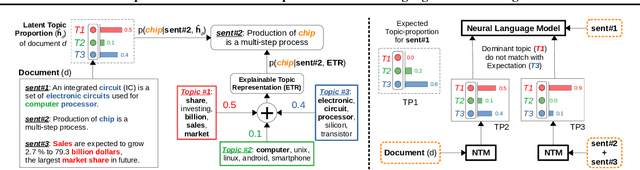


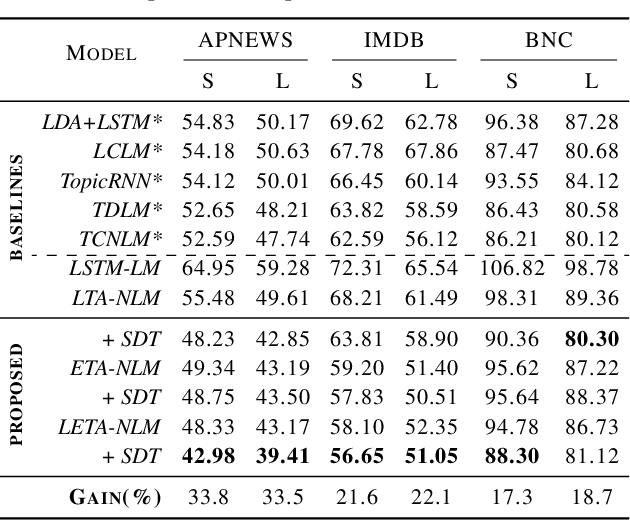
Marrying topic models and language models exposes language understanding to a broader source of document-level context beyond sentences via topics. While introducing topical semantics in language models, existing approaches incorporate latent document topic proportions and ignore topical discourse in sentences of the document. This work extends the line of research by additionally introducing an explainable topic representation in language understanding, obtained from a set of key terms correspondingly for each latent topic of the proportion. Moreover, we retain sentence-topic associations along with document-topic association by modeling topical discourse for every sentence in the document. We present a novel neural composite language model that exploits both the latent and explainable topics along with topical discourse at sentence-level in a joint learning framework of topic and language models. Experiments over a range of tasks such as language modeling, word sense disambiguation, document classification, retrieval and text generation demonstrate ability of the proposed model in improving language understanding.
Neural Topic Modeling with Continual Lifelong Learning
Jun 19, 2020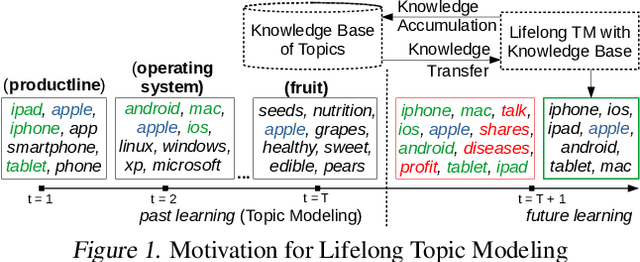



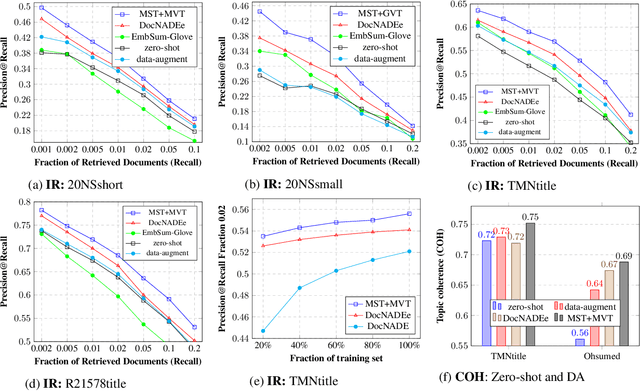
Lifelong learning has recently attracted attention in building machine learning systems that continually accumulate and transfer knowledge to help future learning. Unsupervised topic modeling has been popularly used to discover topics from document collections. However, the application of topic modeling is challenging due to data sparsity, e.g., in a small collection of (short) documents and thus, generate incoherent topics and sub-optimal document representations. To address the problem, we propose a lifelong learning framework for neural topic modeling that can continuously process streams of document collections, accumulate topics and guide future topic modeling tasks by knowledge transfer from several sources to better deal with the sparse data. In the lifelong process, we particularly investigate jointly: (1) sharing generative homologies (latent topics) over lifetime to transfer prior knowledge, and (2) minimizing catastrophic forgetting to retain the past learning via novel selective data augmentation, co-training and topic regularization approaches. Given a stream of document collections, we apply the proposed Lifelong Neural Topic Modeling (LNTM) framework in modeling three sparse document collections as future tasks and demonstrate improved performance quantified by perplexity, topic coherence and information retrieval task.
BioNLP-OST 2019 RDoC Tasks: Multi-grain Neural Relevance Ranking Using Topics and Attention Based Query-Document-Sentence Interactions
Oct 02, 2019
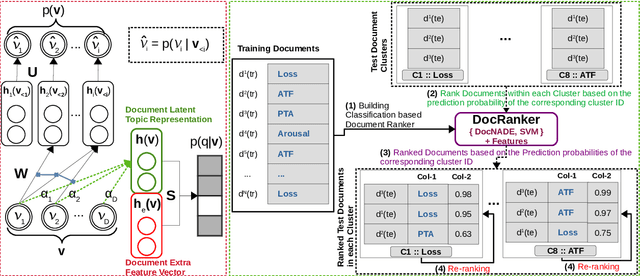

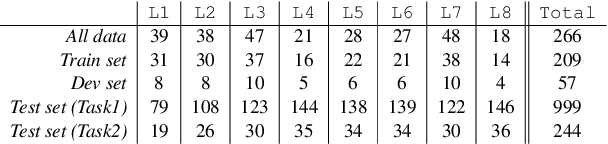
This paper presents our system details and results of participation in the RDoC Tasks of BioNLP-OST 2019. Research Domain Criteria (RDoC) construct is a multi-dimensional and broad framework to describe mental health disorders by combining knowledge from genomics to behaviour. Non-availability of RDoC labelled dataset and tedious labelling process hinders the use of RDoC framework to reach its full potential in Biomedical research community and Healthcare industry. Therefore, Task-1 aims at retrieval and ranking of PubMed abstracts relevant to a given RDoC construct and Task-2 aims at extraction of the most relevant sentence from a given PubMed abstract. We investigate (1) attention based supervised neural topic model and SVM for retrieval and ranking of PubMed abstracts and, further utilize BM25 and other relevance measures for re-ranking, (2) supervised and unsupervised sentence ranking models utilizing multi-view representations comprising of query-aware attention-based sentence representation (QAR), bag-of-words (BoW) and TF-IDF. Our best systems achieved 1st rank and scored 0.86 mean average precision (mAP) and 0.58 macro average accuracy (MAA) in Task-1 and Task-2 respectively.
Lifelong Neural Topic Learning in Contextualized Autoregressive Topic Models of Language via Informative Transfers
Sep 29, 2019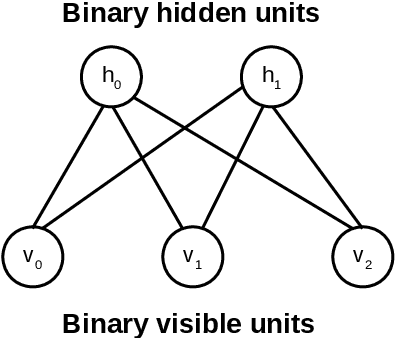
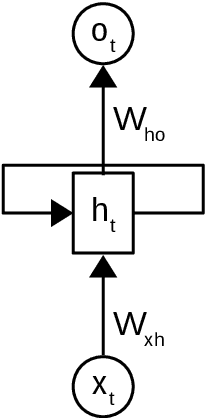
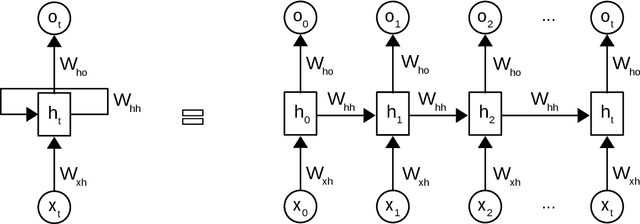
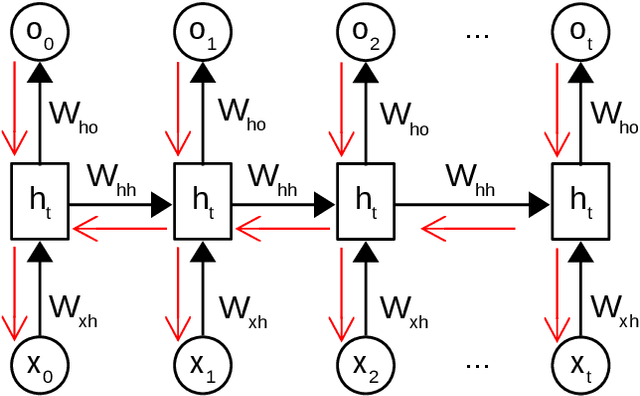
Topic models such as LDA, DocNADE, iDocNADEe have been popular in document analysis. However, the traditional topic models have several limitations including: (1) Bag-of-words (BoW) assumption, where they ignore word ordering, (2) Data sparsity, where the application of topic models is challenging due to limited word co-occurrences, leading to incoherent topics and (3) No Continuous Learning framework for topic learning in lifelong fashion, exploiting historical knowledge (or latent topics) and minimizing catastrophic forgetting. This thesis focuses on addressing the above challenges within neural topic modeling framework. We propose: (1) Contextualized topic model that combines a topic and a language model and introduces linguistic structures (such as word ordering, syntactic and semantic features, etc.) in topic modeling, (2) A novel lifelong learning mechanism into neural topic modeling framework to demonstrate continuous learning in sequential document collections and minimizing catastrophic forgetting. Additionally, we perform a selective data augmentation to alleviate the need for complete historical corpora during data hallucination or replay.
Multi-view and Multi-source Transfers in Neural Topic Modeling with Pretrained Topic and Word Embeddings
Sep 17, 2019

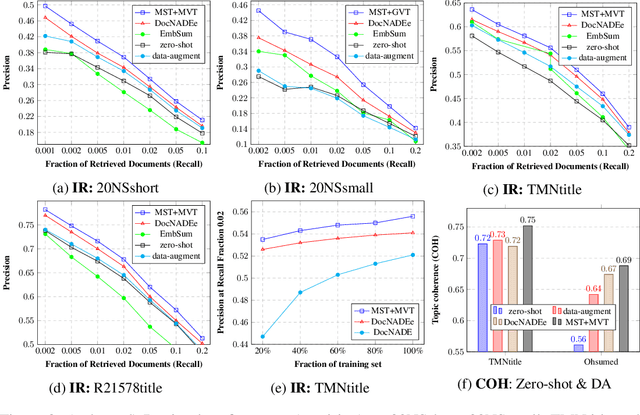
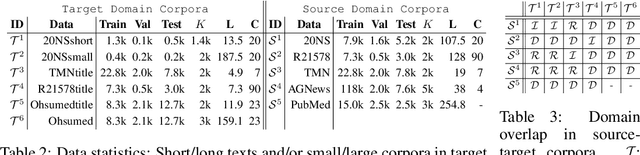
Though word embeddings and topics are complementary representations, several past works have only used pre-trained word embeddings in (neural) topic modeling to address data sparsity problem in short text or small collection of documents. However, no prior work has employed (pre-trained latent) topics in transfer learning paradigm. In this paper, we propose an approach to (1) perform knowledge transfer using latent topics obtained from a large source corpus, and (2) jointly transfer knowledge via the two representations (or views) in neural topic modeling to improve topic quality, better deal with polysemy and data sparsity issues in a target corpus. In doing so, we first accumulate topics and word representations from one or many source corpora to build a pool of topics and word vectors. Then, we identify one or multiple relevant source domain(s) and take advantage of corresponding topics and word features via the respective pools to guide meaningful learning in the sparse target domain. We quantify the quality of topic and document representations via generalization (perplexity), interpretability (topic coherence) and information retrieval (IR) using short-text, long-text, small and large document collections from news and medical domains. We have demonstrated the state-of-the-art results on topic modeling with the proposed framework.
textTOvec: Deep Contextualized Neural Autoregressive Models of Language with Distributed Compositional Prior
Oct 10, 2018

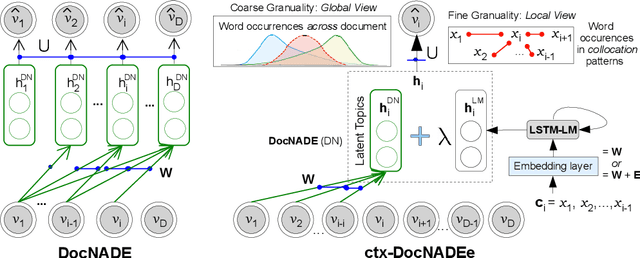
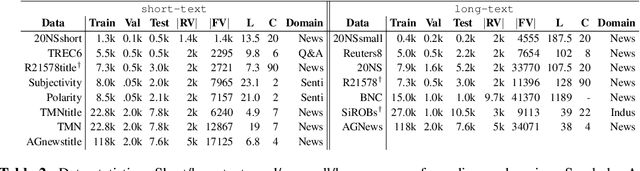
We address two challenges of probabilistic topic modelling in order to better estimate the probability of a word in a given context, i.e., P(word|context): (1) No Language Structure in Context: Probabilistic topic models ignore word order by summarizing a given context as a "bag-of-word" and consequently the semantics of words in the context is lost. The LSTM-LM learns a vector-space representation of each word by accounting for word order in local collocation patterns and models complex characteristics of language (e.g., syntax and semantics), while the TM simultaneously learns a latent representation from the entire document and discovers the underlying thematic structure. We unite two complementary paradigms of learning the meaning of word occurrences by combining a TM and a LM in a unified probabilistic framework, named as ctx-DocNADE. (2) Limited Context and/or Smaller training corpus of documents: In settings with a small number of word occurrences (i.e., lack of context) in short text or data sparsity in a corpus of few documents, the application of TMs is challenging. We address this challenge by incorporating external knowledge into neural autoregressive topic models via a language modelling approach: we use word embeddings as input of a LSTM-LM with the aim to improve the word-topic mapping on a smaller and/or short-text corpus. The proposed DocNADE extension is named as ctx-DocNADEe. We present novel neural autoregressive topic model variants coupled with neural LMs and embeddings priors that consistently outperform state-of-the-art generative TMs in terms of generalization (perplexity), interpretability (topic coherence) and applicability (retrieval and classification) over 6 long-text and 8 short-text datasets from diverse domains.
Document Informed Neural Autoregressive Topic Models with Distributional Prior
Sep 15, 2018

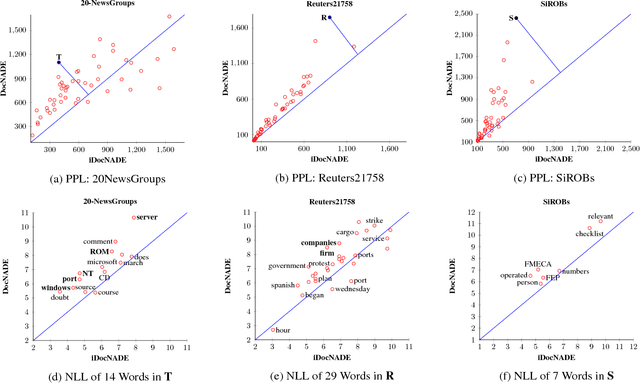
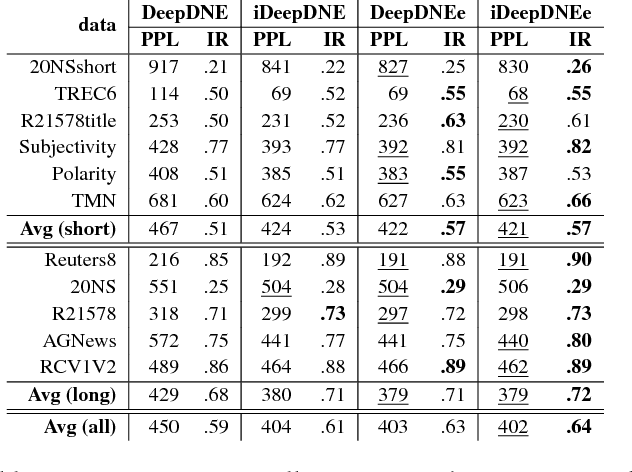
We address two challenges in topic models: (1) Context information around words helps in determining their actual meaning, e.g., "networks" used in the contexts artificial neural networks vs. biological neuron networks. Generative topic models infer topic-word distributions, taking no or only little context into account. Here, we extend a neural autoregressive topic model to exploit the full context information around words in a document in a language modeling fashion. The proposed model is named as iDocNADE. (2) Due to the small number of word occurrences (i.e., lack of context) in short text and data sparsity in a corpus of few documents, the application of topic models is challenging on such texts. Therefore, we propose a simple and efficient way of incorporating external knowledge into neural autoregressive topic models: we use embeddings as a distributional prior. The proposed variants are named as DocNADE2 and iDocNADE2. We present novel neural autoregressive topic model variants that consistently outperform state-of-the-art generative topic models in terms of generalization, interpretability (topic coherence) and applicability (retrieval and classification) over 6 long-text and 8 short-text datasets from diverse domains.