 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom sunblock to softblock: Analyzing the correlates of neology in published writing and on social media
Feb 13, 2026Living languages are shaped by a host of conflicting internal and external evolutionary pressures. While some of these pressures are universal across languages and cultures, others differ depending on the social and conversational context: language use in newspapers is subject to very different constraints than language use on social media. Prior distributional semantic work on English word emergence (neology) identified two factors correlated with creation of new words by analyzing a corpus consisting primarily of historical published texts (Ryskina et al., 2020, arXiv:2001.07740). Extending this methodology to contextual embeddings in addition to static ones and applying it to a new corpus of Twitter posts, we show that the same findings hold for both domains, though the topic popularity growth factor may contribute less to neology on Twitter than in published writing. We hypothesize that this difference can be explained by the two domains favouring different neologism formation mechanisms.
VOYAGER: A Training Free Approach for Generating Diverse Datasets using LLMs
Dec 12, 2025Large language models (LLMs) are increasingly being used to generate synthetic datasets for the evaluation and training of downstream models. However, prior work has noted that such generated data lacks diversity. In this paper, we propose Voyager, a novel principled approach to generate diverse datasets. Our approach is iterative and directly optimizes a mathematical quantity that optimizes the diversity of the dataset using the machinery of determinantal point processes. Furthermore, our approach is training-free, applicable to closed-source models, and scalable. In addition to providing theoretical justification for the working of our method, we also demonstrate through comprehensive experiments that Voyager significantly outperforms popular baseline approaches by providing a 1.5-3x improvement in diversity.
Spivavtor: An Instruction Tuned Ukrainian Text Editing Model
Apr 29, 2024We introduce Spivavtor, a dataset, and instruction-tuned models for text editing focused on the Ukrainian language. Spivavtor is the Ukrainian-focused adaptation of the English-only CoEdIT model. Similar to CoEdIT, Spivavtor performs text editing tasks by following instructions in Ukrainian. This paper describes the details of the Spivavtor-Instruct dataset and Spivavtor models. We evaluate Spivavtor on a variety of text editing tasks in Ukrainian, such as Grammatical Error Correction (GEC), Text Simplification, Coherence, and Paraphrasing, and demonstrate its superior performance on all of them. We publicly release our best-performing models and data as resources to the community to advance further research in this space.
mEdIT: Multilingual Text Editing via Instruction Tuning
Feb 26, 2024We introduce mEdIT, a multi-lingual extension to CoEdIT -- the recent state-of-the-art text editing models for writing assistance. mEdIT models are trained by fine-tuning multi-lingual large, pre-trained language models (LLMs) via instruction tuning. They are designed to take instructions from the user specifying the attributes of the desired text in the form of natural language instructions, such as Grammatik korrigieren (German) or Parafrasee la oraci\'on (Spanish). We build mEdIT by curating data from multiple publicly available human-annotated text editing datasets for three text editing tasks (Grammatical Error Correction (GEC), Text Simplification, and Paraphrasing) across diverse languages belonging to six different language families. We detail the design and training of mEdIT models and demonstrate their strong performance on many multi-lingual text editing benchmarks against other multilingual LLMs. We also find that mEdIT generalizes effectively to new languages over multilingual baselines. We publicly release our data, code, and trained models at https://github.com/vipulraheja/medit.
Personalized Text Generation with Fine-Grained Linguistic Control
Feb 07, 2024



As the text generation capabilities of large language models become increasingly prominent, recent studies have focused on controlling particular aspects of the generated text to make it more personalized. However, most research on controllable text generation focuses on controlling the content or modeling specific high-level/coarse-grained attributes that reflect authors' writing styles, such as formality, domain, or sentiment. In this paper, we focus on controlling fine-grained attributes spanning multiple linguistic dimensions, such as lexical and syntactic attributes. We introduce a novel benchmark to train generative models and evaluate their ability to generate personalized text based on multiple fine-grained linguistic attributes. We systematically investigate the performance of various large language models on our benchmark and draw insights from the factors that impact their performance. We make our code, data, and pretrained models publicly available.
SOCIALITE-LLAMA: An Instruction-Tuned Model for Social Scientific Tasks
Feb 03, 2024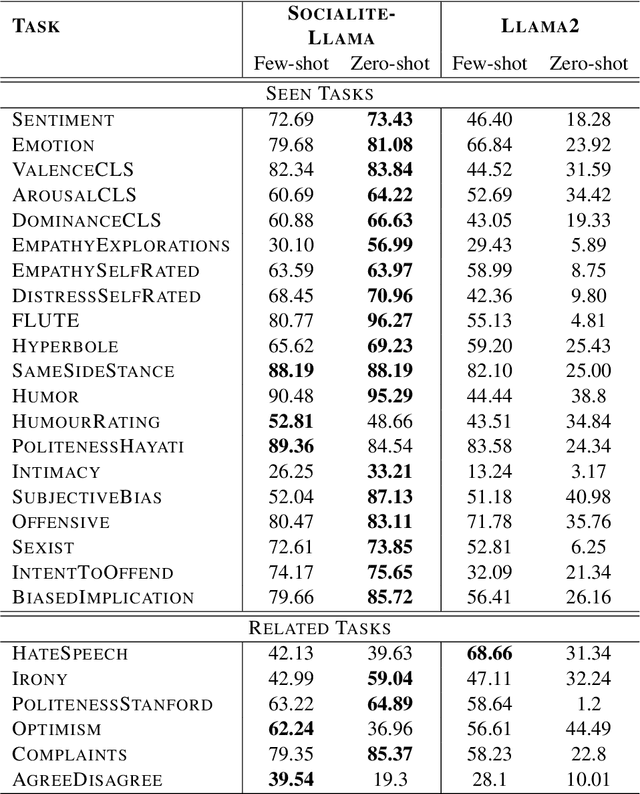



Social science NLP tasks, such as emotion or humor detection, are required to capture the semantics along with the implicit pragmatics from text, often with limited amounts of training data. Instruction tuning has been shown to improve the many capabilities of large language models (LLMs) such as commonsense reasoning, reading comprehension, and computer programming. However, little is known about the effectiveness of instruction tuning on the social domain where implicit pragmatic cues are often needed to be captured. We explore the use of instruction tuning for social science NLP tasks and introduce Socialite-Llama -- an open-source, instruction-tuned Llama. On a suite of 20 social science tasks, Socialite-Llama improves upon the performance of Llama as well as matches or improves upon the performance of a state-of-the-art, multi-task finetuned model on a majority of them. Further, Socialite-Llama also leads to improvement on 5 out of 6 related social tasks as compared to Llama, suggesting instruction tuning can lead to generalized social understanding. All resources including our code, model and dataset can be found through bit.ly/socialitellama.
Writing Assistants Should Model Social Factors of Language
Mar 28, 2023Intelligent writing assistants powered by large language models (LLMs) are more popular today than ever before, but their further widespread adoption is precluded by sub-optimal performance. In this position paper, we argue that a major reason for this sub-optimal performance and adoption is a singular focus on the information content of language while ignoring its social aspects. We analyze the different dimensions of these social factors in the context of writing assistants and propose their incorporation into building smarter, more effective, and truly personalized writing assistants that would enrich the user experience and contribute to increased user adoption.
NTULM: Enriching Social Media Text Representations with Non-Textual Units
Oct 29, 2022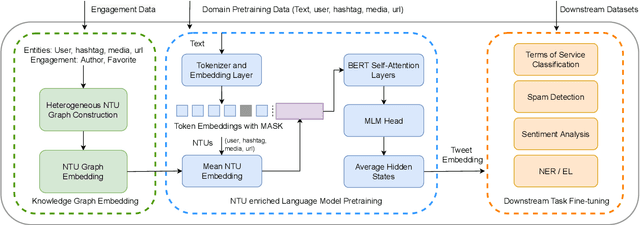

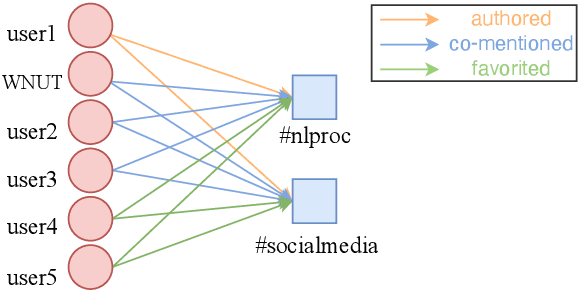
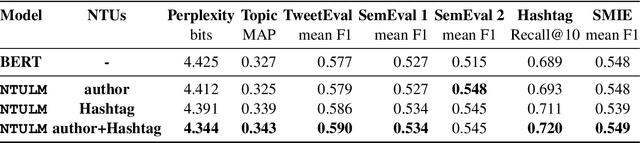
On social media, additional context is often present in the form of annotations and meta-data such as the post's author, mentions, Hashtags, and hyperlinks. We refer to these annotations as Non-Textual Units (NTUs). We posit that NTUs provide social context beyond their textual semantics and leveraging these units can enrich social media text representations. In this work we construct an NTU-centric social heterogeneous network to co-embed NTUs. We then principally integrate these NTU embeddings into a large pretrained language model by fine-tuning with these additional units. This adds context to noisy short-text social media. Experiments show that utilizing NTU-augmented text representations significantly outperforms existing text-only baselines by 2-5\% relative points on many downstream tasks highlighting the importance of context to social media NLP. We also highlight that including NTU context into the initial layers of language model alongside text is better than using it after the text embedding is generated. Our work leads to the generation of holistic general purpose social media content embedding.
CTM -- A Model for Large-Scale Multi-View Tweet Topic Classification
May 03, 2022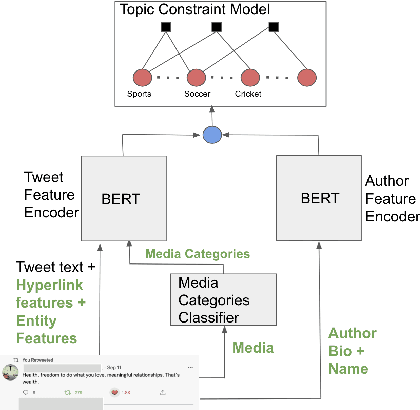

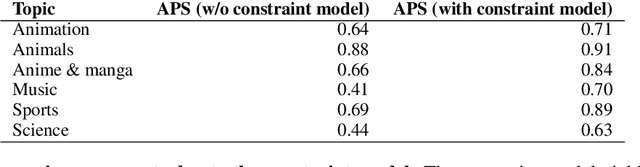

Automatically associating social media posts with topics is an important prerequisite for effective search and recommendation on many social media platforms. However, topic classification of such posts is quite challenging because of (a) a large topic space (b) short text with weak topical cues, and (c) multiple topic associations per post. In contrast to most prior work which only focuses on post classification into a small number of topics ($10$-$20$), we consider the task of large-scale topic classification in the context of Twitter where the topic space is $10$ times larger with potentially multiple topic associations per Tweet. We address the challenges above by proposing a novel neural model, CTM that (a) supports a large topic space of $300$ topics and (b) takes a holistic approach to tweet content modeling -- leveraging multi-modal content, author context, and deeper semantic cues in the Tweet. Our method offers an effective way to classify Tweets into topics at scale by yielding superior performance to other approaches (a relative lift of $\mathbf{20}\%$ in median average precision score) and has been successfully deployed in production at Twitter.
LMSOC: An Approach for Socially Sensitive Pretraining
Oct 20, 2021

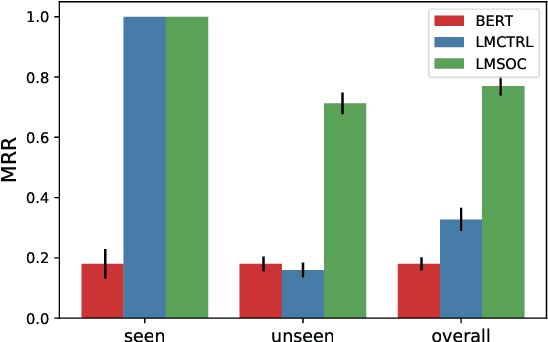

While large-scale pretrained language models have been shown to learn effective linguistic representations for many NLP tasks, there remain many real-world contextual aspects of language that current approaches do not capture. For instance, consider a cloze-test "I enjoyed the ____ game this weekend": the correct answer depends heavily on where the speaker is from, when the utterance occurred, and the speaker's broader social milieu and preferences. Although language depends heavily on the geographical, temporal, and other social contexts of the speaker, these elements have not been incorporated into modern transformer-based language models. We propose a simple but effective approach to incorporate speaker social context into the learned representations of large-scale language models. Our method first learns dense representations of social contexts using graph representation learning algorithms and then primes language model pretraining with these social context representations. We evaluate our approach on geographically-sensitive language-modeling tasks and show a substantial improvement (more than 100% relative lift on MRR) compared to baselines.