 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Word Sequences to Behavioral Sequences: Adapting Modeling and Evaluation Paradigms for Longitudinal NLP
Jan 12, 2026While NLP typically treats documents as independent and unordered samples, in longitudinal studies, this assumption rarely holds: documents are nested within authors and ordered in time, forming person-indexed, time-ordered $\textit{behavioral sequences}$. Here, we demonstrate the need for and propose a longitudinal modeling and evaluation paradigm that consequently updates four parts of the NLP pipeline: (1) evaluation splits aligned to generalization over people ($\textit{cross-sectional}$) and/or time ($\textit{prospective}$); (2) accuracy metrics separating between-person differences from within-person dynamics; (3) sequence inputs to incorporate history by default; and (4) model internals that support different $\textit{coarseness}$ of latent state over histories (pooled summaries, explicit dynamics, or interaction-based models). We demonstrate the issues ensued by traditional pipeline and our proposed improvements on a dataset of 17k daily diary transcripts paired with PTSD symptom severity from 238 participants, finding that traditional document-level evaluation can yield substantially different and sometimes reversed conclusions compared to our ecologically valid modeling and evaluation. We tie our results to a broader discussion motivating a shift from word-sequence evaluation toward $\textit{behavior-sequence}$ paradigms for NLP.
PsychAdapter: Adapting LLM Transformers to Reflect Traits, Personality and Mental Health
Dec 22, 2024



Artificial intelligence-based language generators are now a part of most people's lives. However, by default, they tend to generate "average" language without reflecting the ways in which people differ. Here, we propose a lightweight modification to the standard language model transformer architecture - "PsychAdapter" - that uses empirically derived trait-language patterns to generate natural language for specified personality, demographic, and mental health characteristics (with or without prompting). We applied PsychAdapters to modify OpenAI's GPT-2, Google's Gemma, and Meta's Llama 3 and found generated text to reflect the desired traits. For example, expert raters evaluated PsychAdapter's generated text output and found it matched intended trait levels with 87.3% average accuracy for Big Five personalities, and 96.7% for depression and life satisfaction. PsychAdapter is a novel method to introduce psychological behavior patterns into language models at the foundation level, independent of prompting, by influencing every transformer layer. This approach can create chatbots with specific personality profiles, clinical training tools that mirror language associated with psychological conditionals, and machine translations that match an authors reading or education level without taking up LLM context windows. PsychAdapter also allows for the exploration psychological constructs through natural language expression, extending the natural language processing toolkit to study human psychology.
Explaining GPT-4's Schema of Depression Using Machine Behavior Analysis
Nov 21, 2024



Use of large language models such as ChatGPT (GPT-4) for mental health support has grown rapidly, emerging as a promising route to assess and help people with mood disorders, like depression. However, we have a limited understanding of GPT-4's schema of mental disorders, that is, how it internally associates and interprets symptoms. In this work, we leveraged contemporary measurement theory to decode how GPT-4 interrelates depressive symptoms to inform both clinical utility and theoretical understanding. We found GPT-4's assessment of depression: (a) had high overall convergent validity (r = .71 with self-report on 955 samples, and r = .81 with experts judgments on 209 samples); (b) had moderately high internal consistency (symptom inter-correlates r = .23 to .78 ) that largely aligned with literature and self-report; except that GPT-4 (c) underemphasized suicidality's -- and overemphasized psychomotor's -- relationship with other symptoms, and (d) had symptom inference patterns that suggest nuanced hypotheses (e.g. sleep and fatigue are influenced by most other symptoms while feelings of worthlessness/guilt is mostly influenced by depressed mood).
SOCIALITE-LLAMA: An Instruction-Tuned Model for Social Scientific Tasks
Feb 03, 2024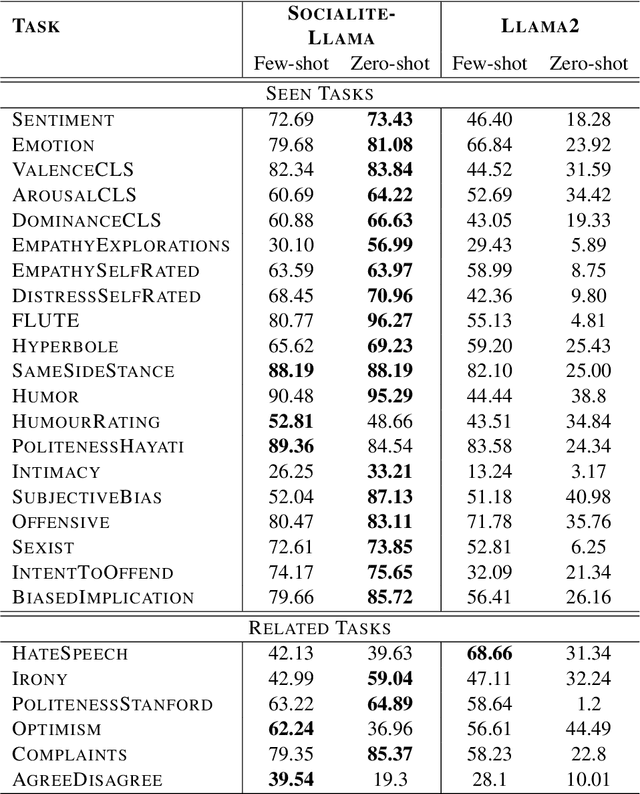



Social science NLP tasks, such as emotion or humor detection, are required to capture the semantics along with the implicit pragmatics from text, often with limited amounts of training data. Instruction tuning has been shown to improve the many capabilities of large language models (LLMs) such as commonsense reasoning, reading comprehension, and computer programming. However, little is known about the effectiveness of instruction tuning on the social domain where implicit pragmatic cues are often needed to be captured. We explore the use of instruction tuning for social science NLP tasks and introduce Socialite-Llama -- an open-source, instruction-tuned Llama. On a suite of 20 social science tasks, Socialite-Llama improves upon the performance of Llama as well as matches or improves upon the performance of a state-of-the-art, multi-task finetuned model on a majority of them. Further, Socialite-Llama also leads to improvement on 5 out of 6 related social tasks as compared to Llama, suggesting instruction tuning can lead to generalized social understanding. All resources including our code, model and dataset can be found through bit.ly/socialitellama.
Systematic Evaluation of GPT-3 for Zero-Shot Personality Estimation
Jun 01, 2023



Very large language models (LLMs) perform extremely well on a spectrum of NLP tasks in a zero-shot setting. However, little is known about their performance on human-level NLP problems which rely on understanding psychological concepts, such as assessing personality traits. In this work, we investigate the zero-shot ability of GPT-3 to estimate the Big 5 personality traits from users' social media posts. Through a set of systematic experiments, we find that zero-shot GPT-3 performance is somewhat close to an existing pre-trained SotA for broad classification upon injecting knowledge about the trait in the prompts. However, when prompted to provide fine-grained classification, its performance drops to close to a simple most frequent class (MFC) baseline. We further analyze where GPT-3 performs better, as well as worse, than a pretrained lexical model, illustrating systematic errors that suggest ways to improve LLMs on human-level NLP tasks.
Empirical Evaluation of Pre-trained Transformers for Human-Level NLP: The Role of Sample Size and Dimensionality
May 07, 2021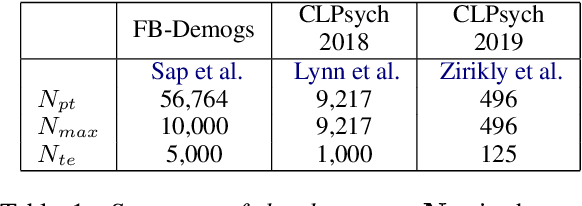
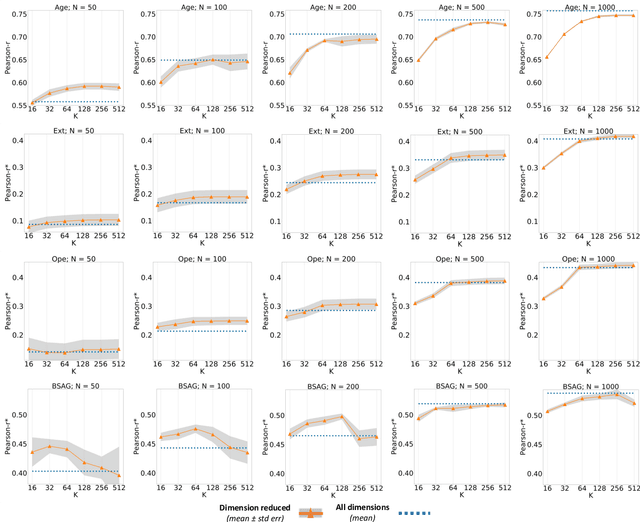
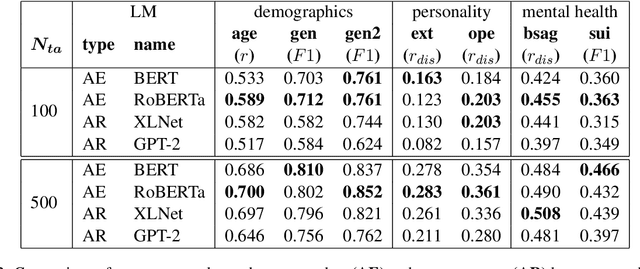
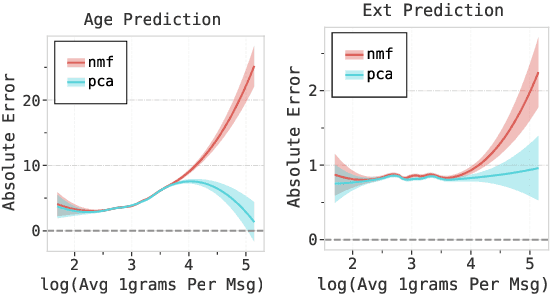
In human-level NLP tasks, such as predicting mental health, personality, or demographics, the number of observations is often smaller than the standard 768+ hidden state sizes of each layer within modern transformer-based language models, limiting the ability to effectively leverage transformers. Here, we provide a systematic study on the role of dimension reduction methods (principal components analysis, factorization techniques, or multi-layer auto-encoders) as well as the dimensionality of embedding vectors and sample sizes as a function of predictive performance. We first find that fine-tuning large models with a limited amount of data pose a significant difficulty which can be overcome with a pre-trained dimension reduction regime. RoBERTa consistently achieves top performance in human-level tasks, with PCA giving benefit over other reduction methods in better handling users that write longer texts. Finally, we observe that a majority of the tasks achieve results comparable to the best performance with just $\frac{1}{12}$ of the embedding dimensions.