 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOCIALITE-LLAMA: An Instruction-Tuned Model for Social Scientific Tasks
Feb 03, 2024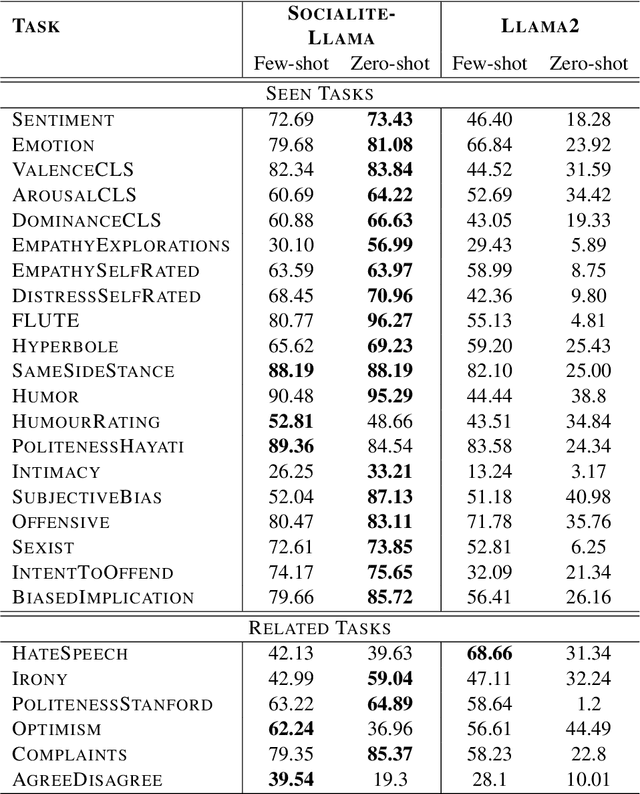



Social science NLP tasks, such as emotion or humor detection, are required to capture the semantics along with the implicit pragmatics from text, often with limited amounts of training data. Instruction tuning has been shown to improve the many capabilities of large language models (LLMs) such as commonsense reasoning, reading comprehension, and computer programming. However, little is known about the effectiveness of instruction tuning on the social domain where implicit pragmatic cues are often needed to be captured. We explore the use of instruction tuning for social science NLP tasks and introduce Socialite-Llama -- an open-source, instruction-tuned Llama. On a suite of 20 social science tasks, Socialite-Llama improves upon the performance of Llama as well as matches or improves upon the performance of a state-of-the-art, multi-task finetuned model on a majority of them. Further, Socialite-Llama also leads to improvement on 5 out of 6 related social tasks as compared to Llama, suggesting instruction tuning can lead to generalized social understanding. All resources including our code, model and dataset can be found through bit.ly/socialitellama.
SSSDET: Simple Short and Shallow Network for Resource Efficient Vehicle Detection in Aerial Scenes
Aug 31, 2019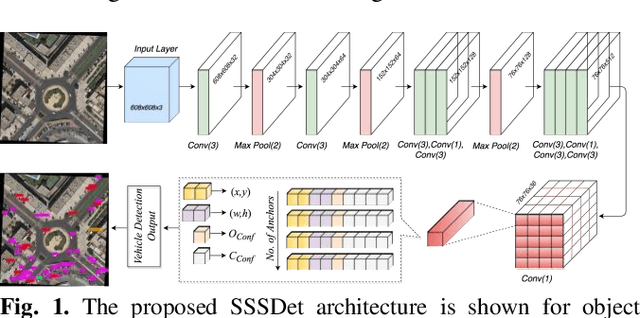
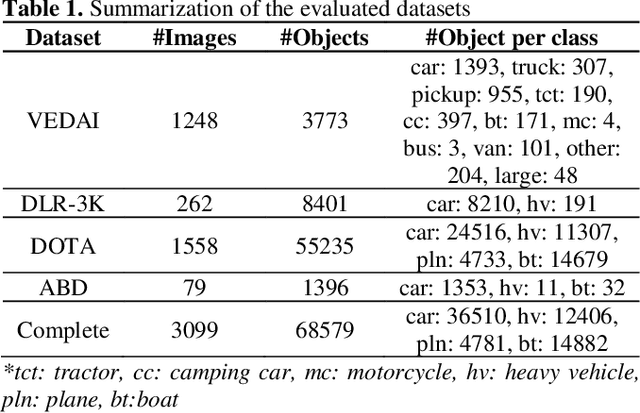
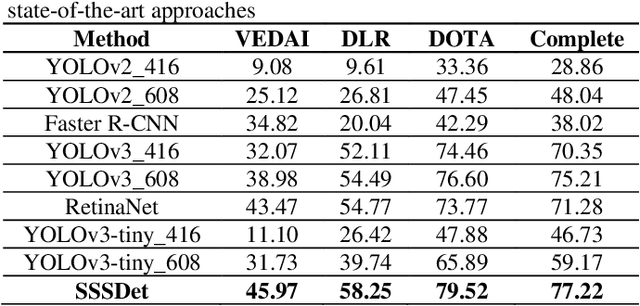

Detection of small-sized targets is of paramount importance in many aerial vision-based applications. The commonly deployed low cost unmanned aerial vehicles (UAVs) for aerial scene analysis are highly resource constrained in nature. In this paper we propose a simple short and shallow network (SSSDet) to robustly detect and classify small-sized vehicles in aerial scenes. The proposed SSSDet is up to 4x faster, requires 4.4x less FLOPs, has 30x less parameters, requires 31x less memory space and provides better accuracy in comparison to existing state-of-the-art detectors. Thus, it is more suitable for hardware implementation in real-time applications. We also created a new airborne image dataset (ABD) by annotating 1396 new objects in 79 aerial images for our experiments. The effectiveness of the proposed method is validated on the existing VEDAI, DLR-3K, DOTA and Combined dataset. The SSSDet outperforms state-of-the-art detectors in term of accuracy, speed, compute and memory efficiency.
AVDNet: A Small-Sized Vehicle Detection Network for Aerial Visual Data
Jul 17, 2019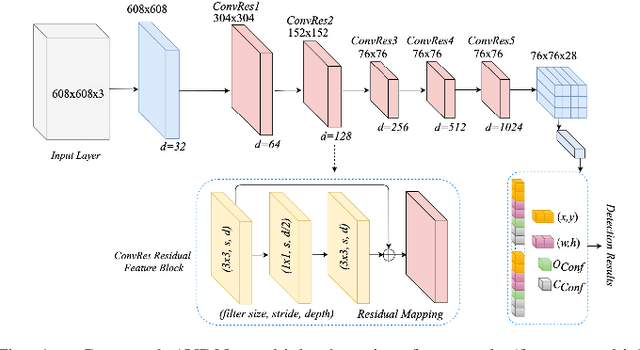
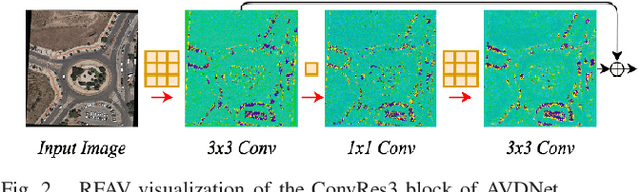
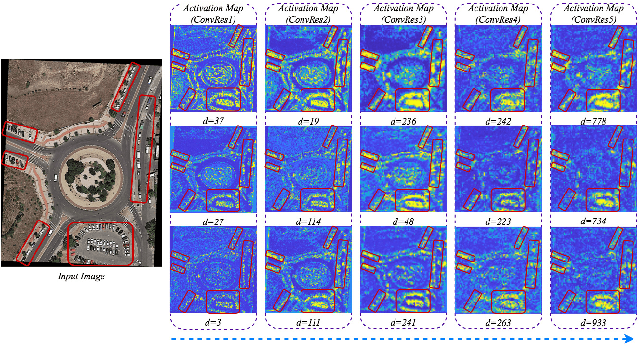
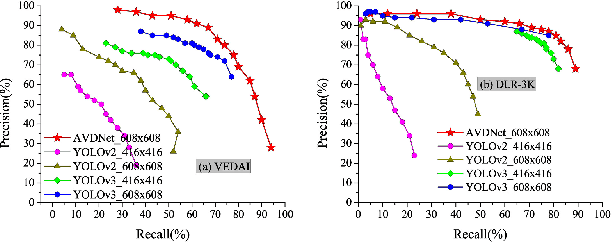
Detection of small-sized targets in aerial views is a challenging task due to the smallness of vehicle size, complex background, and monotonic object appearances. In this letter, we propose a one-stage vehicle detection network (AVDNet) to robustly detect small-sized vehicles in aerial scenes. In AVDNet, we introduced ConvRes residual blocks at multiple scales to alleviate the problem of vanishing features for smaller objects caused because of the inclusion of deeper convolutional layers. These residual blocks, along with enlarged output feature map, ensure the robust representation of the salient features for small sized objects. Furthermore, we proposed a recurrent-feature aware visualization (RFAV) technique to analyze the network behavior. We also created a new airborne image data set (ABD) by annotating 1396 new objects in 79 aerial images for our experiments. The effectiveness of AVDNet is validated on VEDAI, DLR- 3K, DOTA, and the combined (VEDAI, DLR-3K, DOTA, and ABD) data set. Experimental results demonstrate the significant performance improvement of the proposed method over state-of-the-art detection techniques in terms of mAP, computation, and space complexity.
* IEEE Geoscience and Remote Sensing Letters, doi: 10.1109/LGRS.2019.2923564