 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSciClaims: Multimodal Scientific Claim Verification
Jun 05, 2025Assessing scientific claims requires identifying, extracting, and reasoning with multimodal data expressed in information-rich figures in scientific literature. Despite the large body of work in scientific QA, figure captioning, and other multimodal reasoning tasks over chart-based data, there are no readily usable multimodal benchmarks that directly test claim verification abilities. To remedy this gap, we introduce a new benchmark MuSciClaims accompanied by diagnostics tasks. We automatically extract supported claims from scientific articles, which we manually perturb to produce contradicted claims. The perturbations are designed to test for a specific set of claim verification capabilities. We also introduce a suite of diagnostic tasks that help understand model failures. Our results show most vision-language models are poor (~0.3-0.5 F1), with even the best model only achieving 0.77 F1. They are also biased towards judging claims as supported, likely misunderstanding nuanced perturbations within the claims. Our diagnostics show models are bad at localizing correct evidence within figures, struggle with aggregating information across modalities, and often fail to understand basic components of the figure.
$\texttt{DIAMONDs}$: A Dataset for $\mathbb{D}$ynamic $\mathbb{I}$nformation $\mathbb{A}$nd $\mathbb{M}$ental modeling $\mathbb{O}$f $\mathbb{N}$umeric $\mathbb{D}$iscussions
May 19, 2025Understanding multiparty conversations demands robust Theory of Mind (ToM) capabilities, including the ability to track dynamic information, manage knowledge asymmetries, and distinguish relevant information across extended exchanges. To advance ToM evaluation in such settings, we present a carefully designed scalable methodology for generating high-quality benchmark conversation-question pairs with these characteristics. Using this methodology, we create $\texttt{DIAMONDs}$, a new conversational QA dataset covering common business, financial or other group interactions. In these goal-oriented conversations, participants often have to track certain numerical quantities (say $\textit{expected profit}$) of interest that can be derived from other variable quantities (like $\textit{marketing expenses, expected sales, salary}$, etc.), whose values also change over the course of the conversation. $\texttt{DIAMONDs}$ questions pose simple numerical reasoning problems over such quantities of interest (e.g., $\textit{funds required for charity events, expected company profit next quarter}$, etc.) in the context of the information exchanged in conversations. This allows for precisely evaluating ToM capabilities for carefully tracking and reasoning over participants' knowledge states. Our evaluation of state-of-the-art language models reveals significant challenges in handling participant-centric reasoning, specifically in situations where participants have false beliefs. Models also struggle with conversations containing distractors and show limited ability to identify scenarios with insufficient information. These findings highlight current models' ToM limitations in handling real-world multi-party conversations.
Explaining GPT-4's Schema of Depression Using Machine Behavior Analysis
Nov 21, 2024



Use of large language models such as ChatGPT (GPT-4) for mental health support has grown rapidly, emerging as a promising route to assess and help people with mood disorders, like depression. However, we have a limited understanding of GPT-4's schema of mental disorders, that is, how it internally associates and interprets symptoms. In this work, we leveraged contemporary measurement theory to decode how GPT-4 interrelates depressive symptoms to inform both clinical utility and theoretical understanding. We found GPT-4's assessment of depression: (a) had high overall convergent validity (r = .71 with self-report on 955 samples, and r = .81 with experts judgments on 209 samples); (b) had moderately high internal consistency (symptom inter-correlates r = .23 to .78 ) that largely aligned with literature and self-report; except that GPT-4 (c) underemphasized suicidality's -- and overemphasized psychomotor's -- relationship with other symptoms, and (d) had symptom inference patterns that suggest nuanced hypotheses (e.g. sleep and fatigue are influenced by most other symptoms while feelings of worthlessness/guilt is mostly influenced by depressed mood).
Can Stories Help LLMs Reason? Curating Information Space Through Narrative
Oct 25, 2024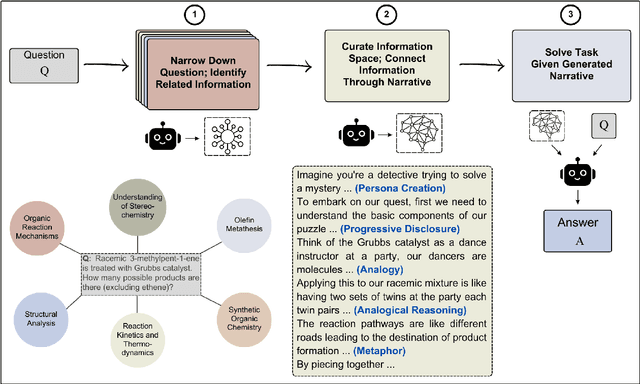
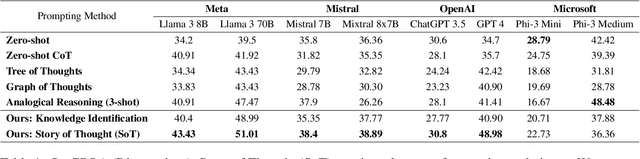
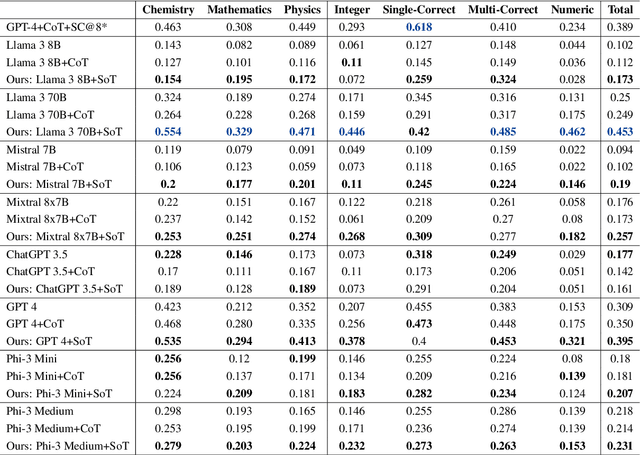
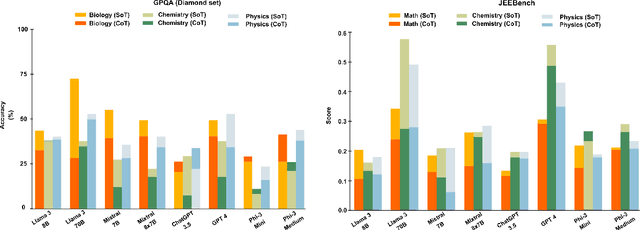
Narratives are widely recognized as a powerful tool for structuring information and facilitating comprehension of complex ideas in various domains such as science communication. This paper investigates whether incorporating narrative elements can assist Large Language Models (LLMs) in solving complex problems more effectively. We propose a novel approach, Story of Thought (SoT), integrating narrative structures into prompting techniques for problem-solving. This approach involves constructing narratives around problem statements and creating a framework to identify and organize relevant information. Our experiments show that using various LLMs with SoT consistently surpasses using them with other techniques on physics, chemistry, math, and biology questions in both the GPQA and JEEBench datasets. The narrative-based information curation process in SoT enhances problem comprehension by contextualizing critical in-domain information and highlighting causal relationships within the problem space.
Automated Adversarial Discovery for Safety Classifiers
Jun 24, 2024Safety classifiers are critical in mitigating toxicity on online forums such as social media and in chatbots. Still, they continue to be vulnerable to emergent, and often innumerable, adversarial attacks. Traditional automated adversarial data generation methods, however, tend to produce attacks that are not diverse, but variations of previously observed harm types. We formalize the task of automated adversarial discovery for safety classifiers - to find new attacks along previously unseen harm dimensions that expose new weaknesses in the classifier. We measure progress on this task along two key axes (1) adversarial success: does the attack fool the classifier? and (2) dimensional diversity: does the attack represent a previously unseen harm type? Our evaluation of existing attack generation methods on the CivilComments toxicity task reveals their limitations: Word perturbation attacks fail to fool classifiers, while prompt-based LLM attacks have more adversarial success, but lack dimensional diversity. Even our best-performing prompt-based method finds new successful attacks on unseen harm dimensions of attacks only 5\% of the time. Automatically finding new harmful dimensions of attack is crucial and there is substantial headroom for future research on our new task.
CaT-BENCH: Benchmarking Language Model Understanding of Causal and Temporal Dependencies in Plans
Jun 22, 2024



Understanding the abilities of LLMs to reason about natural language plans, such as instructional text and recipes, is critical to reliably using them in decision-making systems. A fundamental aspect of plans is the temporal order in which their steps needs to be executed, which reflects the underlying causal dependencies between them. We introduce CaT-Bench, a benchmark of Step Order Prediction questions, which test whether a step must necessarily occur before or after another in cooking recipe plans. We use this to evaluate how well frontier LLMs understand causal and temporal dependencies. We find that SOTA LLMs are underwhelming (best zero-shot is only 0.59 in F1), and are biased towards predicting dependence more often, perhaps relying on temporal order of steps as a heuristic. While prompting for explanations and using few-shot examples improve performance, the best F1 result is only 0.73. Further, human evaluation of explanations along with answer correctness show that, on average, humans do not agree with model reasoning. Surprisingly, we also find that explaining after answering leads to better performance than normal chain-of-thought prompting, and LLM answers are not consistent across questions about the same step pairs. Overall, results show that LLMs' ability to detect dependence between steps has significant room for improvement.
SOCIALITE-LLAMA: An Instruction-Tuned Model for Social Scientific Tasks
Feb 03, 2024Social science NLP tasks, such as emotion or humor detection, are required to capture the semantics along with the implicit pragmatics from text, often with limited amounts of training data. Instruction tuning has been shown to improve the many capabilities of large language models (LLMs) such as commonsense reasoning, reading comprehension, and computer programming. However, little is known about the effectiveness of instruction tuning on the social domain where implicit pragmatic cues are often needed to be captured. We explore the use of instruction tuning for social science NLP tasks and introduce Socialite-Llama -- an open-source, instruction-tuned Llama. On a suite of 20 social science tasks, Socialite-Llama improves upon the performance of Llama as well as matches or improves upon the performance of a state-of-the-art, multi-task finetuned model on a majority of them. Further, Socialite-Llama also leads to improvement on 5 out of 6 related social tasks as compared to Llama, suggesting instruction tuning can lead to generalized social understanding. All resources including our code, model and dataset can be found through bit.ly/socialitellama.
One Size Does Not Fit All: Customizing Open-Domain Procedures
Nov 16, 2023How-to procedures, such as how to plant a garden, are ubiquitous. But one size does not fit all - humans often need to customize these procedural plans according to their specific needs, e.g., planting a garden without pesticides. While LLMs can fluently generate generic procedures, we present the first study on how well LLMs can customize open-domain procedures. We introduce CustomPlans, a probe dataset of customization hints that encodes diverse user needs for open-domain How-to procedures. Using LLMs as CustomizationAgent and ExecutionAgent in different settings, we establish their abilities to perform open-domain procedure customization. Human evaluation shows that using these agents in a Sequential setting is the best, but they are good enough only ~51% of the time. Error analysis shows that LLMs do not sufficiently address user customization needs in their generated procedures.
Evaluating Paraphrastic Robustness in Textual Entailment Models
Jun 29, 2023We present PaRTE, a collection of 1,126 pairs of Recognizing Textual Entailment (RTE) examples to evaluate whether models are robust to paraphrasing. We posit that if RTE models understand language, their predictions should be consistent across inputs that share the same meaning. We use the evaluation set to determine if RTE models' predictions change when examples are paraphrased. In our experiments, contemporary models change their predictions on 8-16\% of paraphrased examples, indicating that there is still room for improvement.
Systematic Evaluation of GPT-3 for Zero-Shot Personality Estimation
Jun 01, 2023



Very large language models (LLMs) perform extremely well on a spectrum of NLP tasks in a zero-shot setting. However, little is known about their performance on human-level NLP problems which rely on understanding psychological concepts, such as assessing personality traits. In this work, we investigate the zero-shot ability of GPT-3 to estimate the Big 5 personality traits from users' social media posts. Through a set of systematic experiments, we find that zero-shot GPT-3 performance is somewhat close to an existing pre-trained SotA for broad classification upon injecting knowledge about the trait in the prompts. However, when prompted to provide fine-grained classification, its performance drops to close to a simple most frequent class (MFC) baseline. We further analyze where GPT-3 performs better, as well as worse, than a pretrained lexical model, illustrating systematic errors that suggest ways to improve LLMs on human-level NLP tasks.