 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
ParaPO: Aligning Language Models to Reduce Verbatim Reproduction of Pre-training Data
Apr 20, 2025Language models (LMs) can memorize and reproduce segments from their pretraining data verbatim even in non-adversarial settings, raising concerns about copyright, plagiarism, privacy, and creativity. We introduce Paraphrase Preference Optimization (ParaPO), a post-training method that fine-tunes LMs to reduce unintentional regurgitation while preserving their overall utility. ParaPO trains LMs to prefer paraphrased versions of memorized segments over the original verbatim content from the pretraining data. To maintain the ability to recall famous quotations when appropriate, we develop a variant of ParaPO that uses system prompts to control regurgitation behavior. In our evaluation on Llama3.1-8B, ParaPO consistently reduces regurgitation across all tested datasets (e.g., reducing the regurgitation metric from 17.3 to 12.9 in creative writing), whereas unlearning methods used in prior work to mitigate regurgitation are less effective outside their targeted unlearned domain (from 17.3 to 16.9). When applied to the instruction-tuned Tulu3-8B model, ParaPO with system prompting successfully preserves famous quotation recall while reducing unintentional regurgitation (from 8.7 to 6.3 in creative writing) when prompted not to regurgitate. In contrast, without ParaPO tuning, prompting the model not to regurgitate produces only a marginal reduction (8.7 to 8.4).
Large-Scale Data Selection for Instruction Tuning
Mar 03, 2025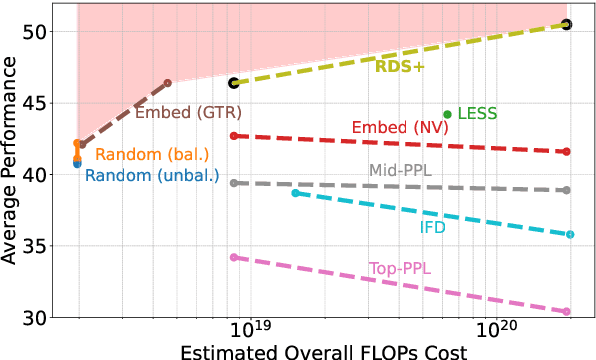


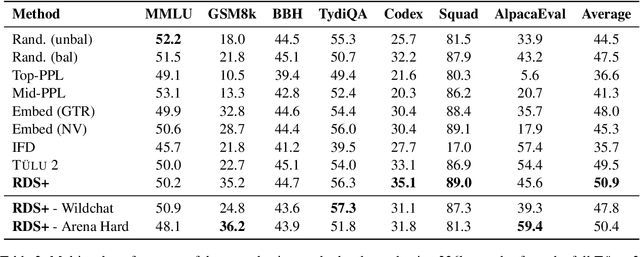
Selecting high-quality training data from a larger pool is a crucial step when instruction-tuning language models, as carefully curated datasets often produce models that outperform those trained on much larger, noisier datasets. Automated data selection approaches for instruction-tuning are typically tested by selecting small datasets (roughly 10k samples) from small pools (100-200k samples). However, popular deployed instruction-tuned models often train on hundreds of thousands to millions of samples, subsampled from even larger data pools. We present a systematic study of how well data selection methods scale to these settings, selecting up to 2.5M samples from pools of up to 5.8M samples and evaluating across 7 diverse tasks. We show that many recently proposed methods fall short of random selection in this setting (while using more compute), and even decline in performance when given access to larger pools of data to select over. However, we find that a variant of representation-based data selection (RDS+), which uses weighted mean pooling of pretrained LM hidden states, consistently outperforms more complex methods across all settings tested -- all whilst being more compute-efficient. Our findings highlight that the scaling properties of proposed automated selection methods should be more closely examined. We release our code, data, and models at https://github.com/hamishivi/automated-instruction-selection.
Aligning LLMs to Ask Good Questions A Case Study in Clinical Reasoning
Feb 20, 2025Large language models (LLMs) often fail to ask effective questions under uncertainty, making them unreliable in domains where proactive information-gathering is essential for decisionmaking. We present ALFA, a framework that improves LLM question-asking by (i) decomposing the notion of a "good" question into a set of theory-grounded attributes (e.g., clarity, relevance), (ii) controllably synthesizing attribute-specific question variations, and (iii) aligning models via preference-based optimization to explicitly learn to ask better questions along these fine-grained attributes. Focusing on clinical reasoning as a case study, we introduce the MediQ-AskDocs dataset, composed of 17k real-world clinical interactions augmented with 80k attribute-specific preference pairs of follow-up questions, as well as a novel expert-annotated interactive healthcare QA task to evaluate question-asking abilities. Models aligned with ALFA reduce diagnostic errors by 56.6% on MediQ-AskDocs compared to SOTA instruction-tuned LLMs, with a question-level win-rate of 64.4% and strong generalizability. Our findings suggest that explicitly guiding question-asking with structured, fine-grained attributes offers a scalable path to improve LLMs, especially in expert application domains.
IssueBench: Millions of Realistic Prompts for Measuring Issue Bias in LLM Writing Assistance
Feb 12, 2025Large language models (LLMs) are helping millions of users write texts about diverse issues, and in doing so expose users to different ideas and perspectives. This creates concerns about issue bias, where an LLM tends to present just one perspective on a given issue, which in turn may influence how users think about this issue. So far, it has not been possible to measure which issue biases LLMs actually manifest in real user interactions, making it difficult to address the risks from biased LLMs. Therefore, we create IssueBench: a set of 2.49m realistic prompts for measuring issue bias in LLM writing assistance, which we construct based on 3.9k templates (e.g. "write a blog about") and 212 political issues (e.g. "AI regulation") from real user interactions. Using IssueBench, we show that issue biases are common and persistent in state-of-the-art LLMs. We also show that biases are remarkably similar across models, and that all models align more with US Democrat than Republican voter opinion on a subset of issues. IssueBench can easily be adapted to include other issues, templates, or tasks. By enabling robust and realistic measurement, we hope that IssueBench can bring a new quality of evidence to ongoing discussions about LLM biases and how to address them.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
Multi-Attribute Constraint Satisfaction via Language Model Rewriting
Dec 26, 2024



Obeying precise constraints on top of multiple external attributes is a common computational problem underlying seemingly different domains, from controlled text generation to protein engineering. Existing language model (LM) controllability methods for multi-attribute constraint satisfaction often rely on specialized architectures or gradient-based classifiers, limiting their flexibility to work with arbitrary black-box evaluators and pretrained models. Current general-purpose large language models, while capable, cannot achieve fine-grained multi-attribute control over external attributes. Thus, we create Multi-Attribute Constraint Satisfaction (MACS), a generalized method capable of finetuning language models on any sequential domain to satisfy user-specified constraints on multiple external real-value attributes. Our method trains LMs as editors by sampling diverse multi-attribute edit pairs from an initial set of paraphrased outputs. During inference, LM iteratively improves upon its previous solution to satisfy constraints for all attributes by leveraging our designed constraint satisfaction reward. We additionally experiment with reward-weighted behavior cloning to further improve the constraint satisfaction rate of LMs. To evaluate our approach, we present a new Fine-grained Constraint Satisfaction (FineCS) benchmark, featuring two challenging tasks: (1) Text Style Transfer, where the goal is to simultaneously modify the sentiment and complexity of reviews, and (2) Protein Design, focusing on modulating fluorescence and stability of Green Fluorescent Proteins (GFP). Our empirical results show that MACS achieves the highest threshold satisfaction in both FineCS tasks, outperforming strong domain-specific baselines. Our work opens new avenues for generalized and real-value multi-attribute control, with implications for diverse applications spanning NLP and bioinformatics.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
RESTOR: Knowledge Recovery through Machine Unlearning
Oct 31, 2024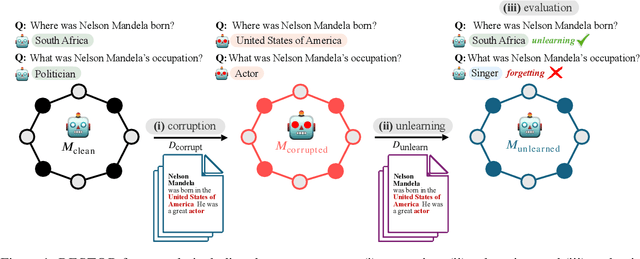

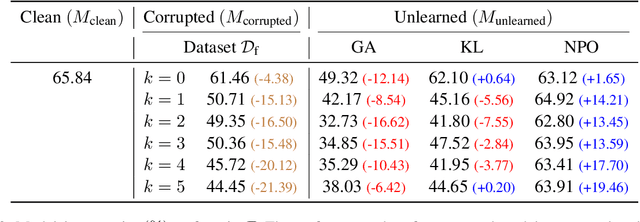
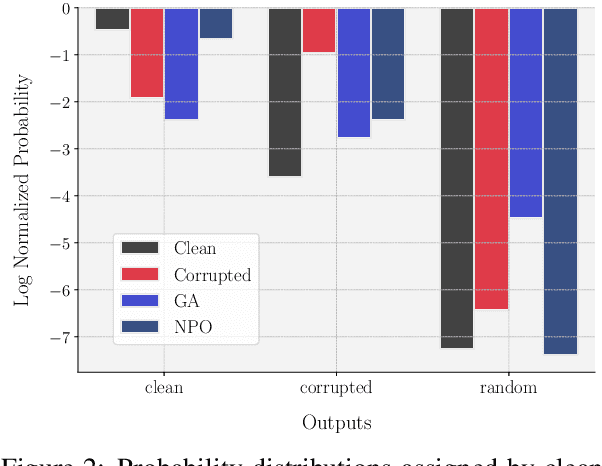
Large language models trained on web-scale corpora can memorize undesirable datapoints such as incorrect facts, copyrighted content or sensitive data. Recently, many machine unlearning methods have been proposed that aim to 'erase' these datapoints from trained models -- that is, revert model behavior to be similar to a model that had never been trained on these datapoints. However, evaluating the success of unlearning algorithms remains challenging. In this work, we propose the RESTOR framework for machine unlearning based on the following dimensions: (1) a task setting that focuses on real-world factual knowledge, (2) a variety of corruption scenarios that emulate different kinds of datapoints that might need to be unlearned, and (3) evaluation metrics that emphasize not just forgetting undesirable knowledge, but also recovering the model's original state before encountering these datapoints, or restorative unlearning. RESTOR helps uncover several novel insights about popular unlearning algorithms, and the mechanisms through which they operate -- for instance, identifying that some algorithms merely emphasize forgetting the knowledge to be unlearned, and that localizing unlearning targets can enhance unlearning performance. Code/data is available at github.com/k1rezaei/restor.
Hybrid Preferences: Learning to Route Instances for Human vs. AI Feedback
Oct 24, 2024



Learning from human feedback has enabled the alignment of language models (LMs) with human preferences. However, directly collecting human preferences can be expensive, time-consuming, and can have high variance. An appealing alternative is to distill preferences from LMs as a source of synthetic annotations as they are more consistent, cheaper, and scale better than human annotation; however, they are also prone to biases and errors. In this work, we introduce a routing framework that combines inputs from humans and LMs to achieve better annotation quality, while reducing the total cost of human annotation. The crux of our approach is to identify preference instances that will benefit from human annotations. We formulate this as an optimization problem: given a preference dataset and an evaluation metric, we train a performance prediction model to predict a reward model's performance on an arbitrary combination of human and LM annotations and employ a routing strategy that selects a combination that maximizes predicted performance. We train the performance prediction model on MultiPref, a new preference dataset with 10K instances paired with human and LM labels. We show that the selected hybrid mixture of LM and direct human preferences using our routing framework achieves better reward model performance compared to using either one exclusively. We simulate selective human preference collection on three other datasets and show that our method generalizes well to all three. We analyze features from the routing model to identify characteristics of instances that can benefit from human feedback, e.g., prompts with a moderate safety concern or moderate intent complexity. We release the dataset, annotation platform, and source code used in this study to foster more efficient and accurate preference collection in the future.