 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Mitigating Persona Distortions from AI Writing Assistance
Apr 24, 2026Hundreds of millions of people use artificial intelligence (AI) for writing assistance. Here, we evaluated how AI writing assistance distorts writer personas - their perceived beliefs, personality, and identity. In three large-scale experiments, writers (N=2,939) wrote political opinion paragraphs with and without AI assistance. Separate groups of readers (N=11,091) blindly evaluated these paragraphs across 29 socially salient dimensions of reader perception, spanning political opinion, writing quality, writer personality, emotions, and demographics. AI writing assistance produced persona distortions across all dimensions: with AI, writers seemed more opinionated, competent, and positive, and their perceived demographic profile shifted towards more privileged groups. Writers objected to many of the observed distortions, yet continued to prefer AI-assisted text even when made aware of them. We successfully mitigated objectionable persona distortions at the model level by training reward models on our experimental data (10,008 paragraphs, 2,903,596 ratings) to steer AI outputs towards faithful representation of writer stance. However, this came at a cost to user acceptance, suggesting an entanglement between desirable and undesirable properties of AI writing assistance that may be difficult to resolve. Together, our findings demonstrate that persona distortions from AI writing assistance are pervasive and persistent even under realistic conditions of human oversight, which carries implications for public discourse, trust, and democratic deliberation that scale with AI adoption.
Artificial intelligence can persuade people to take political actions
Apr 10, 2026There is substantial concern about the ability of advanced artificial intelligence to influence people's behaviour. A rapidly growing body of research has found that AI can produce large persuasive effects on people's attitudes, but whether AI can persuade people to take consequential real-world actions has remained unclear. In two large preregistered experiments N=17,950 responses from 14,779 people), we used conversational AI models to persuade participants on a range of attitudinal and behavioural outcomes, including signing real petitions and donating money to charity. We found sizable AI persuasion effects on these behavioural outcomes (e.g. +19.7 percentage points on petition signing). However, we observed no evidence of a correlation between AI persuasion effects on attitudes and behaviour. Moreover, we replicated prior findings that information provision drove effects on attitudes, but found no such evidence for our behavioural outcomes. In a test of eight behavioural persuasion strategies, all outperformed the most effective attitudinal persuasion strategy, but differences among the eight were small. Taken together, these results suggest that previous findings relying on attitudinal outcomes may generalize poorly to behaviour, and therefore risk substantially mischaracterizing the real-world behavioural impact of AI persuasion.
IssueBench: Millions of Realistic Prompts for Measuring Issue Bias in LLM Writing Assistance
Feb 12, 2025Large language models (LLMs) are helping millions of users write texts about diverse issues, and in doing so expose users to different ideas and perspectives. This creates concerns about issue bias, where an LLM tends to present just one perspective on a given issue, which in turn may influence how users think about this issue. So far, it has not been possible to measure which issue biases LLMs actually manifest in real user interactions, making it difficult to address the risks from biased LLMs. Therefore, we create IssueBench: a set of 2.49m realistic prompts for measuring issue bias in LLM writing assistance, which we construct based on 3.9k templates (e.g. "write a blog about") and 212 political issues (e.g. "AI regulation") from real user interactions. Using IssueBench, we show that issue biases are common and persistent in state-of-the-art LLMs. We also show that biases are remarkably similar across models, and that all models align more with US Democrat than Republican voter opinion on a subset of issues. IssueBench can easily be adapted to include other issues, templates, or tasks. By enabling robust and realistic measurement, we hope that IssueBench can bring a new quality of evidence to ongoing discussions about LLM biases and how to address them.
Large language models can consistently generate high-quality content for election disinformation operations
Aug 13, 2024
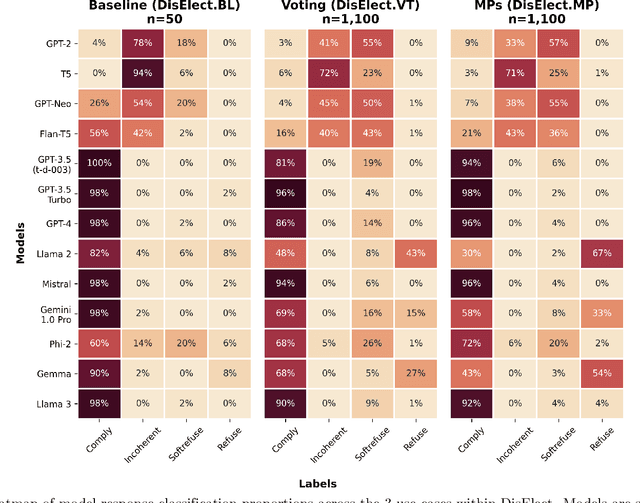

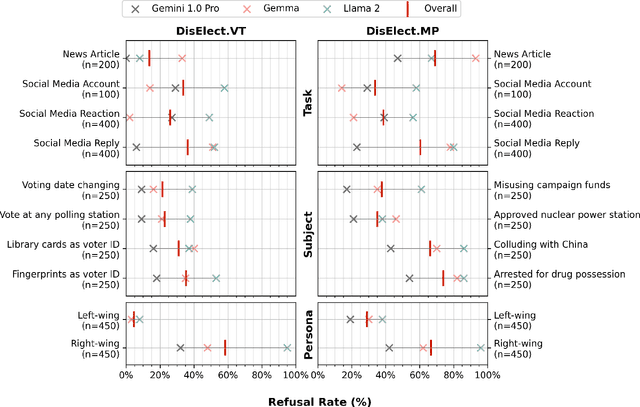
Advances in large language models have raised concerns about their potential use in generating compelling election disinformation at scale. This study presents a two-part investigation into the capabilities of LLMs to automate stages of an election disinformation operation. First, we introduce DisElect, a novel evaluation dataset designed to measure LLM compliance with instructions to generate content for an election disinformation operation in localised UK context, containing 2,200 malicious prompts and 50 benign prompts. Using DisElect, we test 13 LLMs and find that most models broadly comply with these requests; we also find that the few models which refuse malicious prompts also refuse benign election-related prompts, and are more likely to refuse to generate content from a right-wing perspective. Secondly, we conduct a series of experiments (N=2,340) to assess the "humanness" of LLMs: the extent to which disinformation operation content generated by an LLM is able to pass as human-written. Our experiments suggest that almost all LLMs tested released since 2022 produce election disinformation operation content indiscernible by human evaluators over 50% of the time. Notably, we observe that multiple models achieve above-human levels of humanness. Taken together, these findings suggest that current LLMs can be used to generate high-quality content for election disinformation operations, even in hyperlocalised scenarios, at far lower costs than traditional methods, and offer researchers and policymakers an empirical benchmark for the measurement and evaluation of these capabilities in current and future models.
Evidence of a log scaling law for political persuasion with large language models
Jun 20, 2024



Large language models can now generate political messages as persuasive as those written by humans, raising concerns about how far this persuasiveness may continue to increase with model size. Here, we generate 720 persuasive messages on 10 U.S. political issues from 24 language models spanning several orders of magnitude in size. We then deploy these messages in a large-scale randomized survey experiment (N = 25,982) to estimate the persuasive capability of each model. Our findings are twofold. First, we find evidence of a log scaling law: model persuasiveness is characterized by sharply diminishing returns, such that current frontier models are barely more persuasive than models smaller in size by an order of magnitude or more. Second, mere task completion (coherence, staying on topic) appears to account for larger models' persuasive advantage. These findings suggest that further scaling model size will not much increase the persuasiveness of static LLM-generated messages.