 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Hierarchical Structure in Vision Models with Sparse Autoencoders
May 21, 2025The ImageNet hierarchy provides a structured taxonomy of object categories, offering a valuable lens through which to analyze the representations learned by deep vision models. In this work, we conduct a comprehensive analysis of how vision models encode the ImageNet hierarchy, leveraging Sparse Autoencoders (SAEs) to probe their internal representations. SAEs have been widely used as an explanation tool for large language models (LLMs), where they enable the discovery of semantically meaningful features. Here, we extend their use to vision models to investigate whether learned representations align with the ontological structure defined by the ImageNet taxonomy. Our results show that SAEs uncover hierarchical relationships in model activations, revealing an implicit encoding of taxonomic structure. We analyze the consistency of these representations across different layers of the popular vision foundation model DINOv2 and provide insights into how deep vision models internalize hierarchical category information by increasing information in the class token through each layer. Our study establishes a framework for systematic hierarchical analysis of vision model representations and highlights the potential of SAEs as a tool for probing semantic structure in deep networks.
IssueBench: Millions of Realistic Prompts for Measuring Issue Bias in LLM Writing Assistance
Feb 12, 2025Large language models (LLMs) are helping millions of users write texts about diverse issues, and in doing so expose users to different ideas and perspectives. This creates concerns about issue bias, where an LLM tends to present just one perspective on a given issue, which in turn may influence how users think about this issue. So far, it has not been possible to measure which issue biases LLMs actually manifest in real user interactions, making it difficult to address the risks from biased LLMs. Therefore, we create IssueBench: a set of 2.49m realistic prompts for measuring issue bias in LLM writing assistance, which we construct based on 3.9k templates (e.g. "write a blog about") and 212 political issues (e.g. "AI regulation") from real user interactions. Using IssueBench, we show that issue biases are common and persistent in state-of-the-art LLMs. We also show that biases are remarkably similar across models, and that all models align more with US Democrat than Republican voter opinion on a subset of issues. IssueBench can easily be adapted to include other issues, templates, or tasks. By enabling robust and realistic measurement, we hope that IssueBench can bring a new quality of evidence to ongoing discussions about LLM biases and how to address them.
Steering Large Language Models to Evaluate and Amplify Creativity
Dec 08, 2024Although capable of generating creative text, Large Language Models (LLMs) are poor judges of what constitutes "creativity". In this work, we show that we can leverage this knowledge of how to write creatively in order to better judge what is creative. We take a mechanistic approach that extracts differences in the internal states of an LLM when prompted to respond "boringly" or "creatively" to provide a robust measure of creativity that corresponds strongly with human judgment. We also show these internal state differences can be applied to enhance the creativity of generated text at inference time.
Debias your Large Multi-Modal Model at Test-Time with Non-Contrastive Visual Attribute Steering
Nov 15, 2024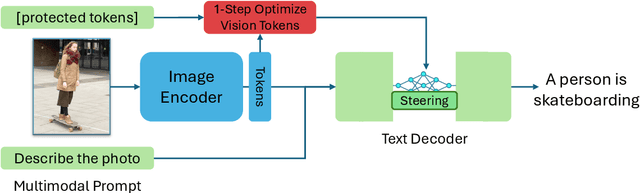
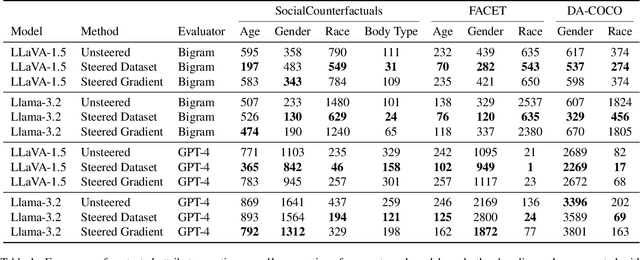
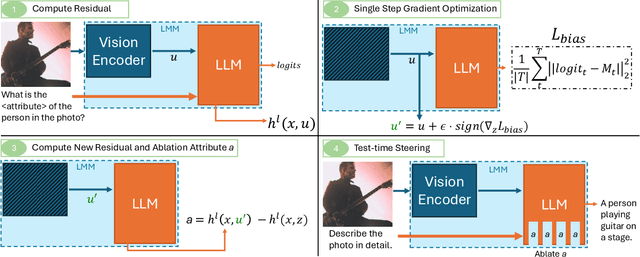
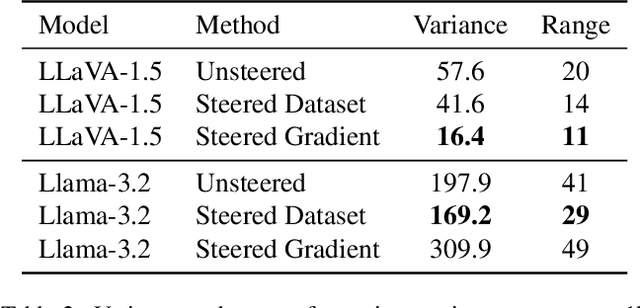
Large Multi-Modal Models (LMMs) have demonstrated impressive capabilities as general-purpose chatbots that can engage in conversations about a provided input, such as an image. However, their responses are influenced by societal biases present in their training datasets, leading to undesirable differences in how the model responds when presented with images depicting people of different demographics. In this work, we propose a novel debiasing framework for LMMs that directly removes biased representations during text generation to decrease outputs related to protected attributes, or even representing them internally. Our proposed method is training-free; given a single image and a list of target attributes, we can ablate the corresponding representations with just one step of gradient descent on the image itself. Our experiments show that not only can we can minimize the propensity of LMMs to generate text related to protected attributes, but we can improve sentiment and even simply use synthetic data to inform the ablation while retaining language modeling capabilities on real data such as COCO or FACET. Furthermore, we find the resulting generations from a debiased LMM exhibit similar accuracy as a baseline biased model, showing that debiasing effects can be achieved without sacrificing model performance.
Debiasing Large Vision-Language Models by Ablating Protected Attribute Representations
Oct 17, 2024



Large Vision Language Models (LVLMs) such as LLaVA have demonstrated impressive capabilities as general-purpose chatbots that can engage in conversations about a provided input image. However, their responses are influenced by societal biases present in their training datasets, leading to undesirable differences in how the model responds when presented with images depicting people of different demographics. In this work, we propose a novel debiasing framework for LVLMs by directly ablating biased attributes during text generation to avoid generating text related to protected attributes, or even representing them internally. Our method requires no training and a relatively small amount of representative biased outputs (~1000 samples). Our experiments show that not only can we can minimize the propensity of LVLMs to generate text related to protected attributes, but we can even use synthetic data to inform the ablation while retaining captioning performance on real data such as COCO. Furthermore, we find the resulting generations from a debiased LVLM exhibit similar accuracy as a baseline biased model, showing that debiasing effects can be achieved without sacrificing model performance.
AutoPersuade: A Framework for Evaluating and Explaining Persuasive Arguments
Oct 11, 2024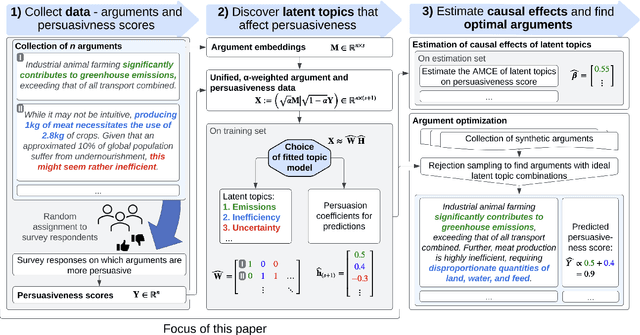

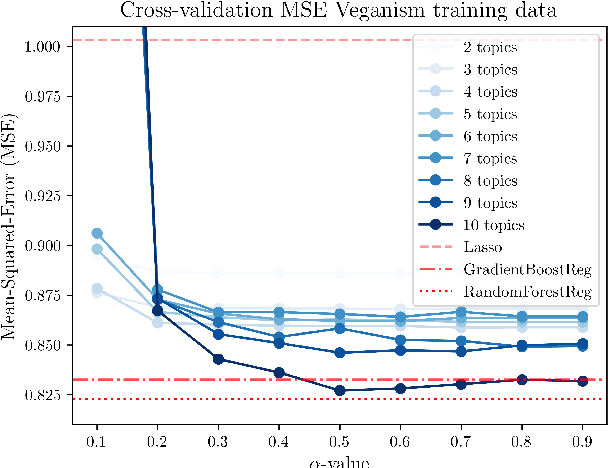
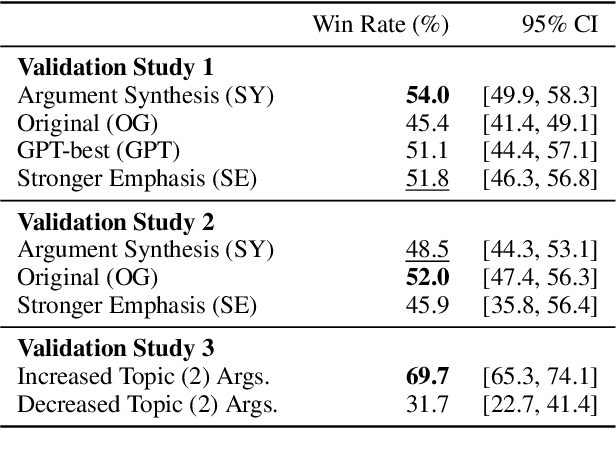
We introduce AutoPersuade, a three-part framework for constructing persuasive messages. First, we curate a large dataset of arguments with human evaluations. Next, we develop a novel topic model to identify argument features that influence persuasiveness. Finally, we use this model to predict the effectiveness of new arguments and assess the causal impact of different components to provide explanations. We validate AutoPersuade through an experimental study on arguments for veganism, demonstrating its effectiveness with human studies and out-of-sample predictions.
ClimDetect: A Benchmark Dataset for Climate Change Detection and Attribution
Aug 28, 2024
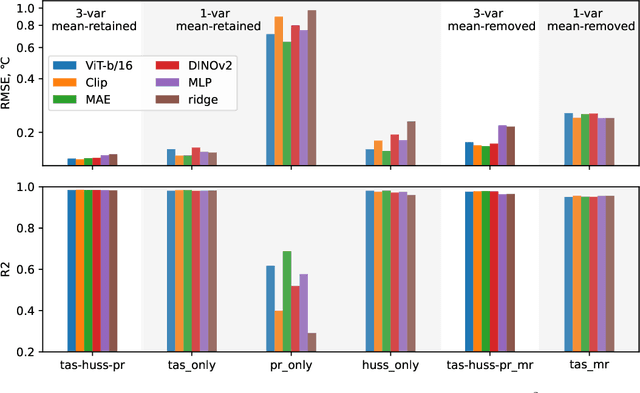
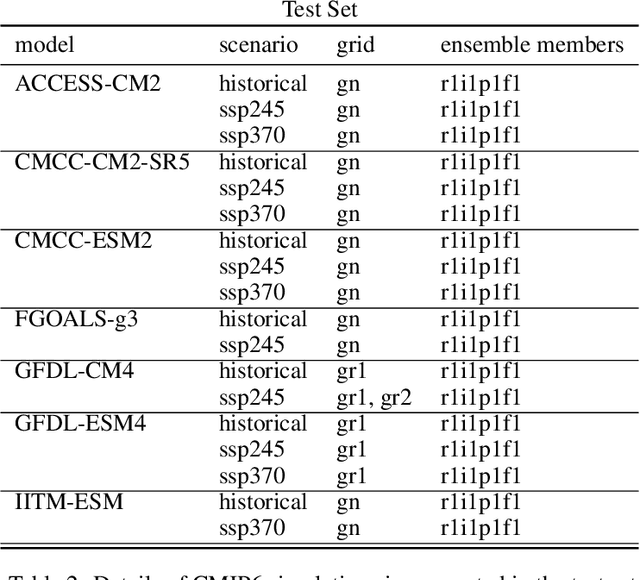
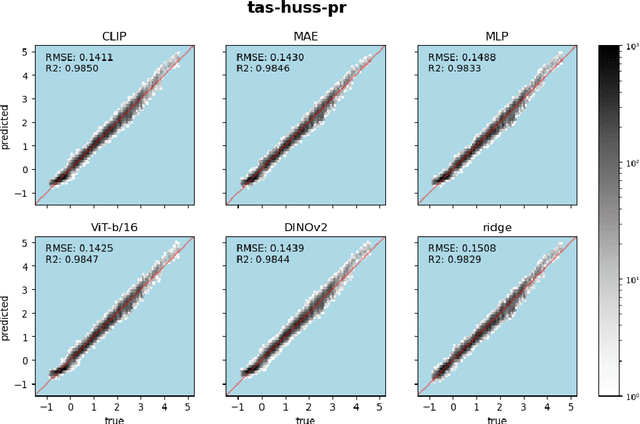
Detecting and attributing temperature increases due to climate change is crucial for understanding global warming and guiding adaptation strategies. The complexity of distinguishing human-induced climate signals from natural variability has challenged traditional detection and attribution (D&A) approaches, which seek to identify specific "fingerprints" in climate response variables. Deep learning offers potential for discerning these complex patterns in expansive spatial datasets. However, lack of standard protocols has hindered consistent comparisons across studies. We introduce ClimDetect, a standardized dataset of over 816k daily climate snapshots, designed to enhance model accuracy in identifying climate change signals. ClimDetect integrates various input and target variables used in past research, ensuring comparability and consistency. We also explore the application of vision transformers (ViT) to climate data, a novel and modernizing approach in this context. Our open-access data and code serve as a benchmark for advancing climate science through improved model evaluations. ClimDetect is publicly accessible via Huggingface dataet respository at: https://huggingface.co/datasets/ClimDetect/ClimDetect.
Why do LLaVA Vision-Language Models Reply to Images in English?
Jul 02, 2024
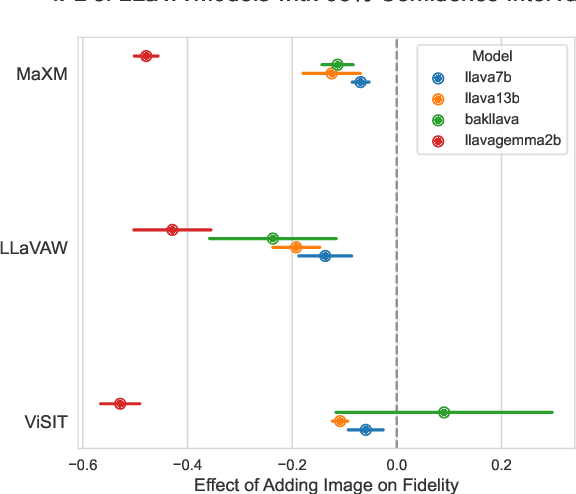
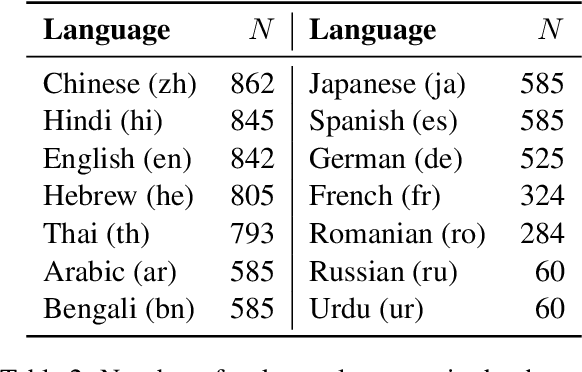
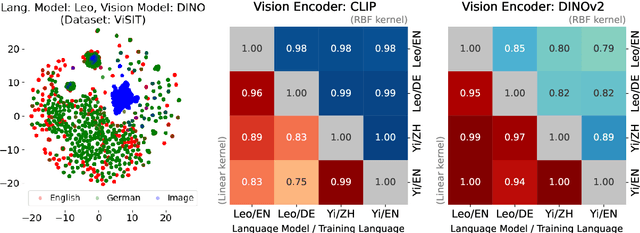
We uncover a surprising multilingual bias occurring in a popular class of multimodal vision-language models (VLMs). Including an image in the query to a LLaVA-style VLM significantly increases the likelihood of the model returning an English response, regardless of the language of the query. This paper investigates the causes of this loss with a two-pronged approach that combines extensive ablation of the design space with a mechanistic analysis of the models' internal representations of image and text inputs. Both approaches indicate that the issue stems in the language modelling component of the LLaVA model. Statistically, we find that switching the language backbone for a bilingual language model has the strongest effect on reducing this error. Mechanistically, we provide compelling evidence that visual inputs are not mapped to a similar space as text ones, and that intervening on intermediary attention layers can reduce this bias. Our findings provide important insights to researchers and engineers seeking to understand the crossover between multimodal and multilingual spaces, and contribute to the goal of developing capable and inclusive VLMs for non-English contexts.
LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model
Mar 29, 2024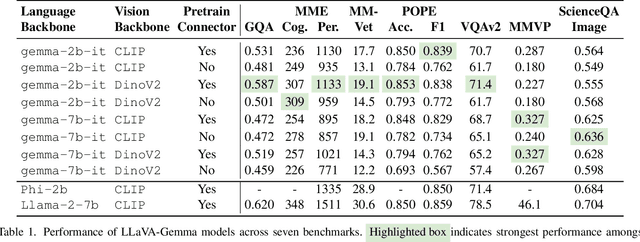
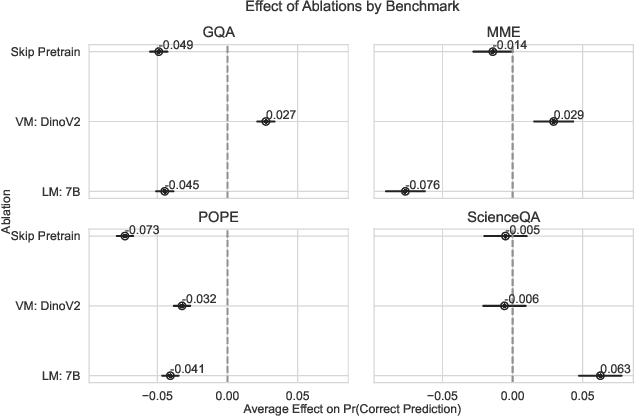

We train a suite of multimodal foundation models (MMFM) using the popular LLaVA framework with the recently released Gemma family of large language models (LLMs). Of particular interest is the 2B parameter Gemma model, which provides opportunities to construct capable small-scale MMFMs. In line with findings from other papers in this space, we test the effect of ablating three design features: pretraining the connector, utilizing a more powerful image backbone, and increasing the size of the language backbone. The resulting models, which we call LLaVA-Gemma, exhibit moderate performance on an array of evaluations, but fail to improve past the current comparably sized SOTA models. Closer analysis of performance shows mixed effects; skipping pretraining tends to reduce performance, larger vision models sometimes improve performance, and increasing language model size has inconsistent effects. We publicly release training recipes, code and weights for our models for the LLaVA-Gemma models.
Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models
Feb 26, 2024



Much recent work seeks to evaluate values and opinions in large language models (LLMs) using multiple-choice surveys and questionnaires. Most of this work is motivated by concerns around real-world LLM applications. For example, politically-biased LLMs may subtly influence society when they are used by millions of people. Such real-world concerns, however, stand in stark contrast to the artificiality of current evaluations: real users do not typically ask LLMs survey questions. Motivated by this discrepancy, we challenge the prevailing constrained evaluation paradigm for values and opinions in LLMs and explore more realistic unconstrained evaluations. As a case study, we focus on the popular Political Compass Test (PCT). In a systematic review, we find that most prior work using the PCT forces models to comply with the PCT's multiple-choice format. We show that models give substantively different answers when not forced; that answers change depending on how models are forced; and that answers lack paraphrase robustness. Then, we demonstrate that models give different answers yet again in a more realistic open-ended answer setting. We distill these findings into recommendations and open challenges in evaluating values and opinions in LLMs.