 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPersuade: A Framework for Evaluating and Explaining Persuasive Arguments
Oct 11, 2024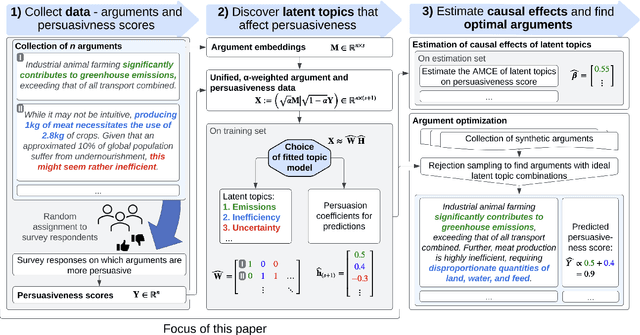

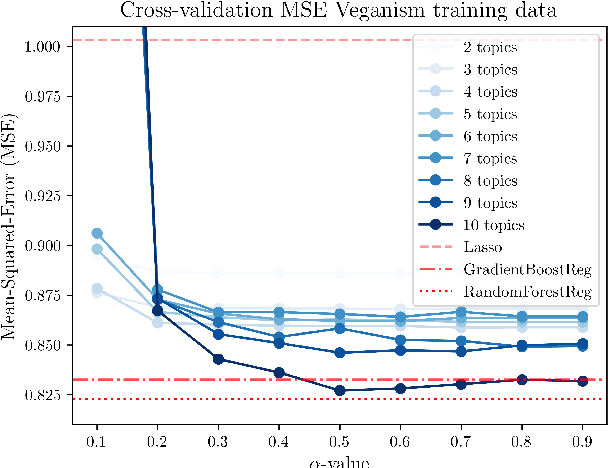
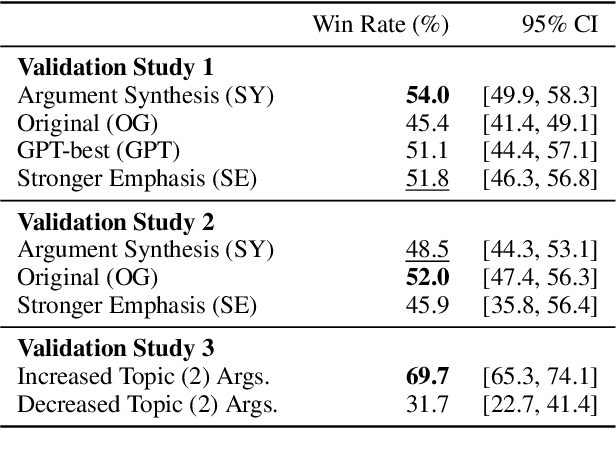
We introduce AutoPersuade, a three-part framework for constructing persuasive messages. First, we curate a large dataset of arguments with human evaluations. Next, we develop a novel topic model to identify argument features that influence persuasiveness. Finally, we use this model to predict the effectiveness of new arguments and assess the causal impact of different components to provide explanations. We validate AutoPersuade through an experimental study on arguments for veganism, demonstrating its effectiveness with human studies and out-of-sample predictions.
Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
Sep 02, 2021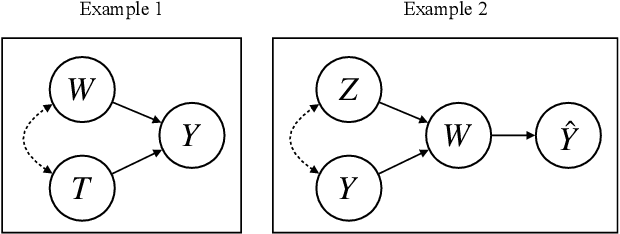
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the remaining challenges. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects, encompassing settings where text is used as an outcome, treatment, or as a means to address confounding. In addition, we explore potential uses of causal inference to improve the performance, robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the computational linguistics community.
Naïve regression requires weaker assumptions than factor models to adjust for multiple cause confounding
Jul 24, 2020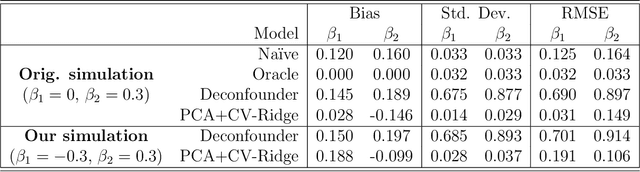
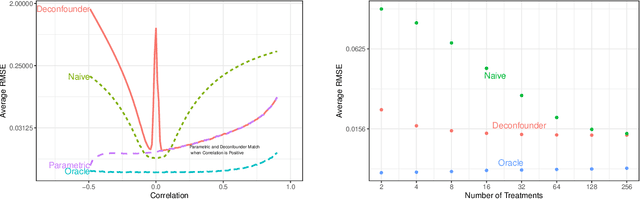
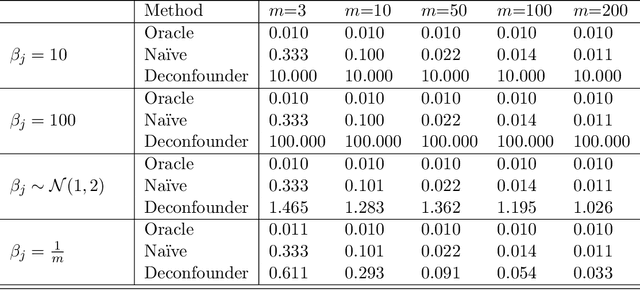

The empirical practice of using factor models to adjust for shared, unobserved confounders, $\mathbf{Z}$, in observational settings with multiple treatments, $\mathbf{A}$, is widespread in fields including genetics, networks, medicine, and politics. Wang and Blei (2019, WB) formalizes these procedures and develops the "deconfounder," a causal inference method using factor models of $\mathbf{A}$ to estimate "substitute confounders," $\hat{\mathbf{Z}}$, then estimating treatment effects by regressing the outcome, $\mathbf{Y}$, on part of $\mathbf{A}$ while adjusting for $\hat{\mathbf{Z}}$. WB claim the deconfounder is unbiased when there are no single-cause confounders and $\hat{\mathbf{Z}}$ is "pinpointed." We clarify pinpointing requires each confounder to affect infinitely many treatments. We prove under these assumptions, a na\"ive semiparametric regression of $\mathbf{Y}$ on $\mathbf{A}$ is asymptotically unbiased. Deconfounder variants nesting this regression are therefore also asymptotically unbiased, but variants using $\hat{\mathbf{Z}}$ and subsets of causes require further untestable assumptions. We replicate every deconfounder analysis with available data and find it fails to consistently outperform na\"ive regression. In practice, the deconfounder produces implausible estimates in WB's case study to movie earnings: estimates suggest comic author Stan Lee's cameo appearances causally contributed \$15.5 billion, most of Marvel movie revenue. We conclude neither approach is a viable substitute for careful research design in real-world applications.
How to Make Causal Inferences Using Texts
Feb 06, 2018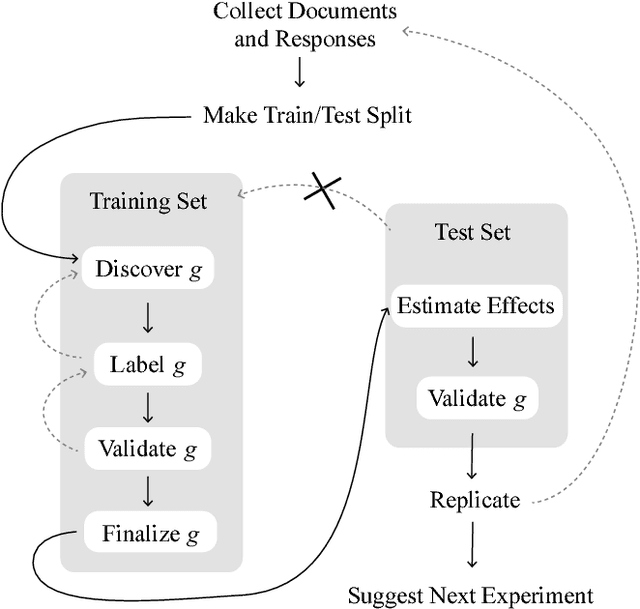
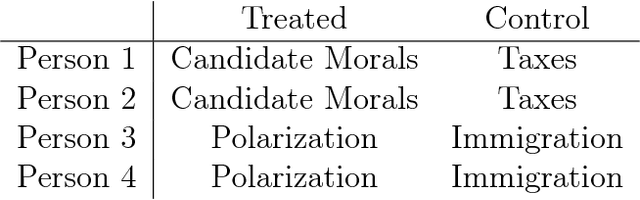

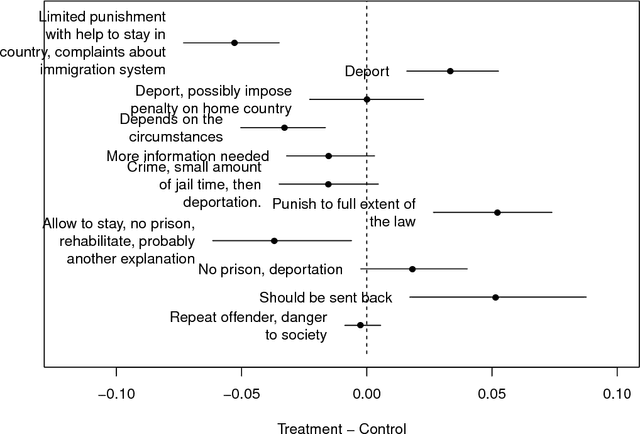
New text as data techniques offer a great promise: the ability to inductively discover measures that are useful for testing social science theories of interest from large collections of text. We introduce a conceptual framework for making causal inferences with discovered measures as a treatment or outcome. Our framework enables researchers to discover high-dimensional textual interventions and estimate the ways that observed treatments affect text-based outcomes. We argue that nearly all text-based causal inferences depend upon a latent representation of the text and we provide a framework to learn the latent representation. But estimating this latent representation, we show, creates new risks: we may introduce an identification problem or overfit. To address these risks we describe a split-sample framework and apply it to estimate causal effects from an experiment on immigration attitudes and a study on bureaucratic response. Our work provides a rigorous foundation for text-based causal inferences.