 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodebook LLMs: Adapting Political Science Codebooks for LLM Use and Adapting LLMs to Follow Codebooks
Jul 15, 2024


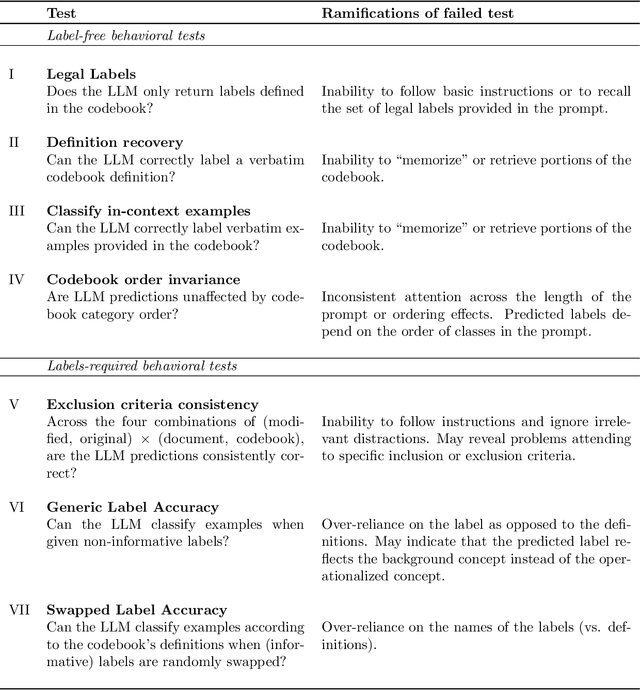
Codebooks -- documents that operationalize constructs and outline annotation procedures -- are used almost universally by social scientists when coding unstructured political texts. Recently, to reduce manual annotation costs, political scientists have looked to generative large language models (LLMs) to label and analyze text data. However, previous work using LLMs for classification has implicitly relied on the universal label assumption -- correct classification of documents is possible using only a class label or minimal definition and the information that the LLM inductively learns during its pre-training. In contrast, we argue that political scientists who care about valid measurement should instead make a codebook-construct label assumption -- an LLM should follow the definition and exclusion criteria of a construct/label provided in a codebook. In this work, we collect and curate three political science datasets and their original codebooks and conduct a set of experiments to understand whether LLMs comply with codebook instructions, whether rewriting codebooks improves performance, and whether instruction-tuning LLMs on codebook-document-label tuples improves performance over zero-shot classification. Using Mistral 7B Instruct as our LLM, we find re-structuring the original codebooks gives modest gains in zero-shot performance but the model still struggles to comply with the constraints of the codebooks. Optimistically, instruction-tuning Mistral on one of our datasets gives significant gains over zero-shot inference (0.76 versus 0.53 micro F1). We hope our conceptualization of the codebook-specific task, assumptions, and instruction-tuning pipeline as well our semi-structured LLM codebook format will help political scientists readily adapt to the LLM era.
Proximal Causal Inference With Text Data
Jan 12, 2024



Recent text-based causal methods attempt to mitigate confounding bias by including unstructured text data as proxies of confounding variables that are partially or imperfectly measured. These approaches assume analysts have supervised labels of the confounders given text for a subset of instances, a constraint that is not always feasible due to data privacy or cost. Here, we address settings in which an important confounding variable is completely unobserved. We propose a new causal inference method that splits pre-treatment text data, infers two proxies from two zero-shot models on the separate splits, and applies these proxies in the proximal g-formula. We prove that our text-based proxy method satisfies identification conditions required by the proximal g-formula while other seemingly reasonable proposals do not. We evaluate our method in synthetic and semi-synthetic settings and find that it produces estimates with low bias. This combination of proximal causal inference and zero-shot classifiers is novel (to our knowledge) and expands the set of text-specific causal methods available to practitioners.
RCT Rejection Sampling for Causal Estimation Evaluation
Jul 27, 2023



Confounding is a significant obstacle to unbiased estimation of causal effects from observational data. For settings with high-dimensional covariates -- such as text data, genomics, or the behavioral social sciences -- researchers have proposed methods to adjust for confounding by adapting machine learning methods to the goal of causal estimation. However, empirical evaluation of these adjustment methods has been challenging and limited. In this work, we build on a promising empirical evaluation strategy that simplifies evaluation design and uses real data: subsampling randomized controlled trials (RCTs) to create confounded observational datasets while using the average causal effects from the RCTs as ground-truth. We contribute a new sampling algorithm, which we call RCT rejection sampling, and provide theoretical guarantees that causal identification holds in the observational data to allow for valid comparisons to the ground-truth RCT. Using synthetic data, we show our algorithm indeed results in low bias when oracle estimators are evaluated on the confounded samples, which is not always the case for a previously proposed algorithm. In addition to this identification result, we highlight several finite data considerations for evaluation designers who plan to use RCT rejection sampling on their own datasets. As a proof of concept, we implement an example evaluation pipeline and walk through these finite data considerations with a novel, real-world RCT -- which we release publicly -- consisting of approximately 70k observations and text data as high-dimensional covariates. Together, these contributions build towards a broader agenda of improved empirical evaluation for causal estimation.
Words as Gatekeepers: Measuring Discipline-specific Terms and Meanings in Scholarly Publications
Dec 19, 2022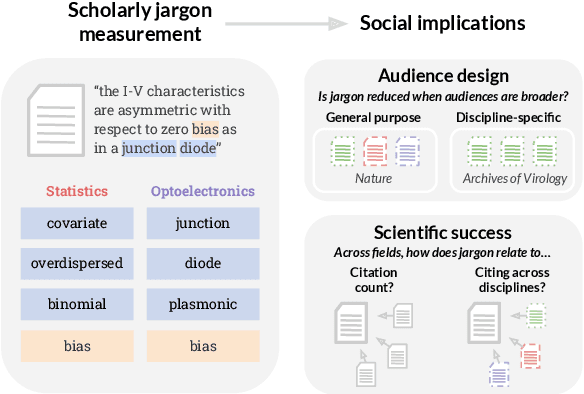
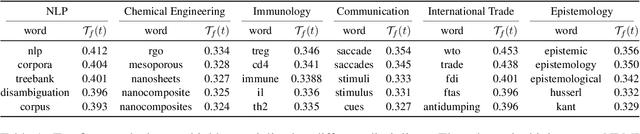


Scholarly text is often laden with jargon, or specialized language that divides disciplines. We extend past work that characterizes science at the level of word types, by using BERT-based word sense induction to find additional words that are widespread but overloaded with different uses across fields. We define scholarly jargon as discipline-specific word types and senses, and estimate its prevalence across hundreds of fields using interpretable, information-theoretic metrics. We demonstrate the utility of our approach for science of science and computational sociolinguistics by highlighting two key social implications. First, we measure audience design, and find that most fields reduce jargon when publishing in general-purpose journals, but some do so more than others. Second, though jargon has varying correlation with articles' citation rates within fields, it nearly always impedes interdisciplinary impact. Broadly, our measurements can inform ways in which language could be revised to serve as a bridge rather than a barrier in science.
Text as Causal Mediators: Research Design for Causal Estimates of Differential Treatment of Social Groups via Language Aspects
Sep 15, 2021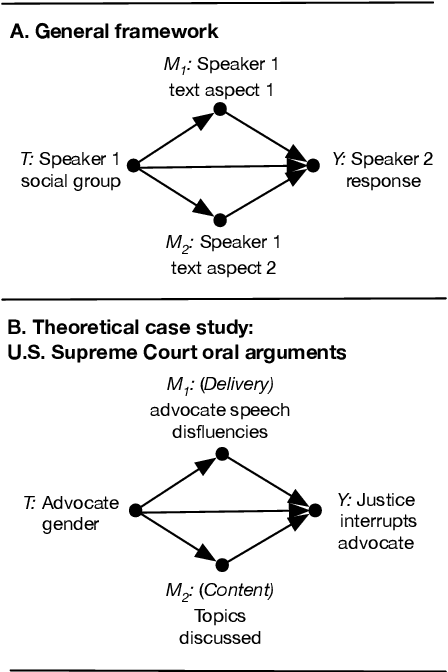


Using observed language to understand interpersonal interactions is important in high-stakes decision making. We propose a causal research design for observational (non-experimental) data to estimate the natural direct and indirect effects of social group signals (e.g. race or gender) on speakers' responses with separate aspects of language as causal mediators. We illustrate the promises and challenges of this framework via a theoretical case study of the effect of an advocate's gender on interruptions from justices during U.S. Supreme Court oral arguments. We also discuss challenges conceptualizing and operationalizing causal variables such as gender and language that comprise of many components, and we articulate technical open challenges such as temporal dependence between language mediators in conversational settings.
* Accepted to Causal Inference and NLP (CI+NLP) Workshop at EMNLP 2021
Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
Sep 02, 2021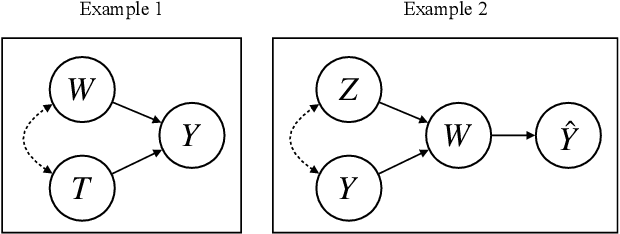
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the remaining challenges. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects, encompassing settings where text is used as an outcome, treatment, or as a means to address confounding. In addition, we explore potential uses of causal inference to improve the performance, robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the computational linguistics community.
Corpus-Level Evaluation for Event QA: The IndiaPoliceEvents Corpus Covering the 2002 Gujarat Violence
May 27, 2021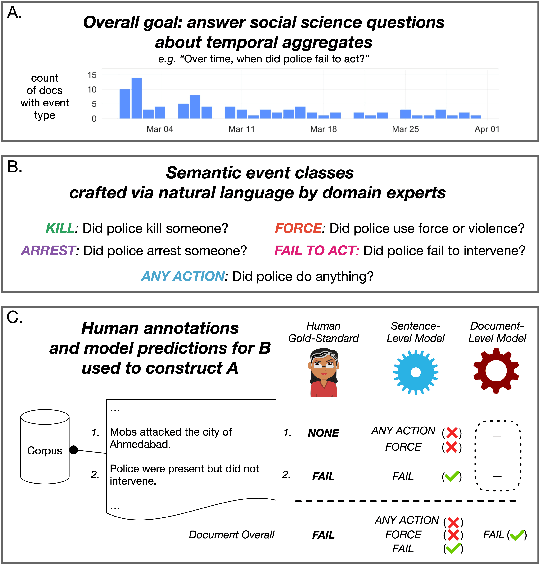
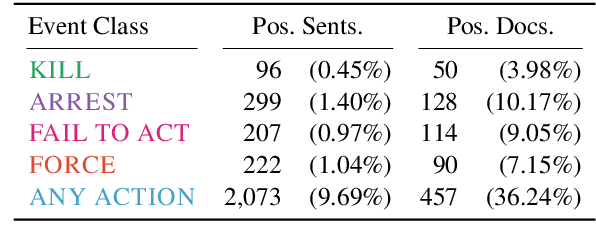

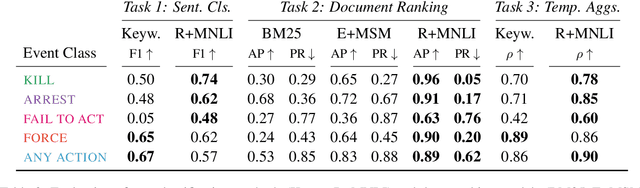
Automated event extraction in social science applications often requires corpus-level evaluations: for example, aggregating text predictions across metadata and unbiased estimates of recall. We combine corpus-level evaluation requirements with a real-world, social science setting and introduce the IndiaPoliceEvents corpus--all 21,391 sentences from 1,257 English-language Times of India articles about events in the state of Gujarat during March 2002. Our trained annotators read and label every document for mentions of police activity events, allowing for unbiased recall evaluations. In contrast to other datasets with structured event representations, we gather annotations by posing natural questions, and evaluate off-the-shelf models for three different tasks: sentence classification, document ranking, and temporal aggregation of target events. We present baseline results from zero-shot BERT-based models fine-tuned on natural language inference and passage retrieval tasks. Our novel corpus-level evaluations and annotation approach can guide creation of similar social-science-oriented resources in the future.
* To appear in Findings of ACL 2021
Uncertainty over Uncertainty: Investigating the Assumptions, Annotations, and Text Measurements of Economic Policy Uncertainty
Oct 09, 2020
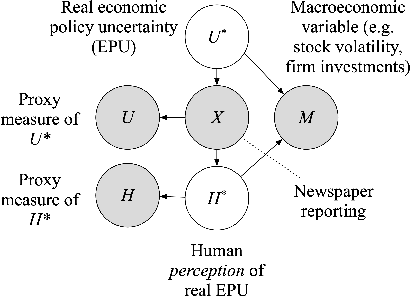

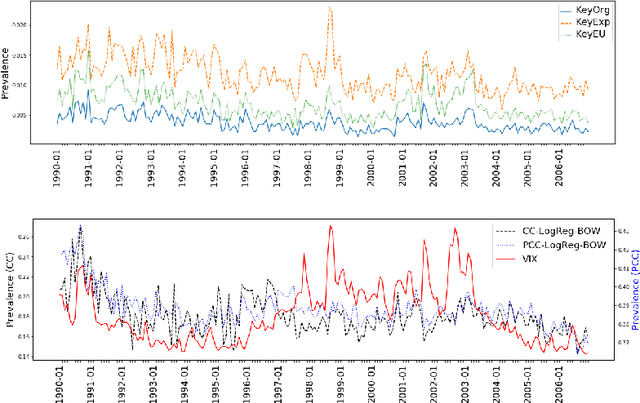
Methods and applications are inextricably linked in science, and in particular in the domain of text-as-data. In this paper, we examine one such text-as-data application, an established economic index that measures economic policy uncertainty from keyword occurrences in news. This index, which is shown to correlate with firm investment, employment, and excess market returns, has had substantive impact in both the private sector and academia. Yet, as we revisit and extend the original authors' annotations and text measurements we find interesting text-as-data methodological research questions: (1) Are annotator disagreements a reflection of ambiguity in language? (2) Do alternative text measurements correlate with one another and with measures of external predictive validity? We find for this application (1) some annotator disagreements of economic policy uncertainty can be attributed to ambiguity in language, and (2) switching measurements from keyword-matching to supervised machine learning classifiers results in low correlation, a concerning implication for the validity of the index.
* Accepted to the 2020 Natural Language Processing + Computational Social Science Workshop (NLP+CSS) at EMNLP
Text and Causal Inference: A Review of Using Text to Remove Confounding from Causal Estimates
May 01, 2020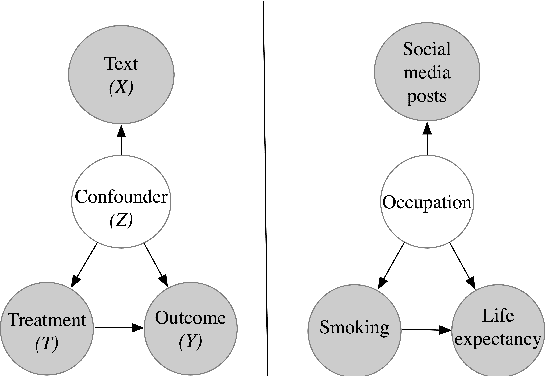
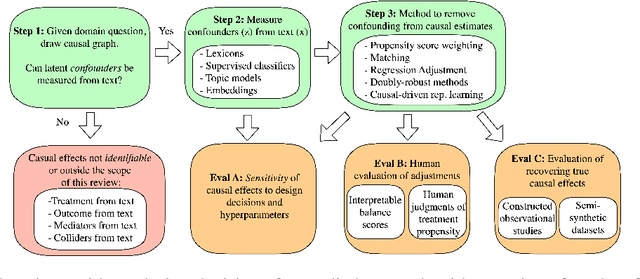

Many applications of computational social science aim to infer causal conclusions from non-experimental data. Such observational data often contains confounders, variables that influence both potential causes and potential effects. Unmeasured or latent confounders can bias causal estimates, and this has motivated interest in measuring potential confounders from observed text. For example, an individual's entire history of social media posts or the content of a news article could provide a rich measurement of multiple confounders. Yet, methods and applications for this problem are scattered across different communities and evaluation practices are inconsistent. This review is the first to gather and categorize these examples and provide a guide to data-processing and evaluation decisions. Despite increased attention on adjusting for confounding using text, there are still many open problems, which we highlight in this paper.
* Accepted to ACL 2020
Modeling financial analysts' decision making via the pragmatics and semantics of earnings calls
Jun 24, 2019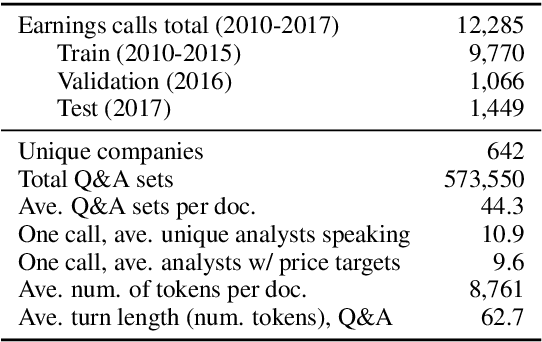
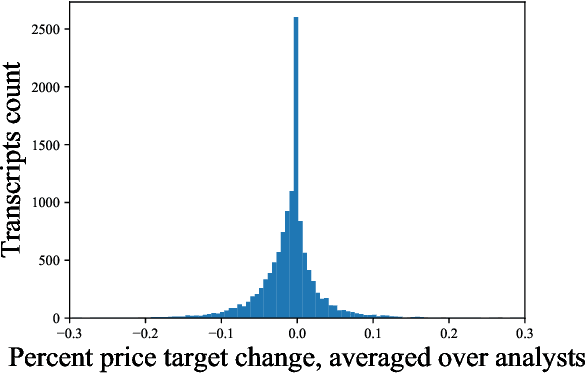

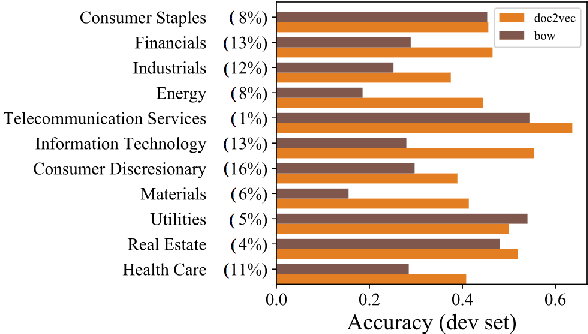
Every fiscal quarter, companies hold earnings calls in which company executives respond to questions from analysts. After these calls, analysts often change their price target recommendations, which are used in equity research reports to help investors make decisions. In this paper, we examine analysts' decision making behavior as it pertains to the language content of earnings calls. We identify a set of 20 pragmatic features of analysts' questions which we correlate with analysts' pre-call investor recommendations. We also analyze the degree to which semantic and pragmatic features from an earnings call complement market data in predicting analysts' post-call changes in price targets. Our results show that earnings calls are moderately predictive of analysts' decisions even though these decisions are influenced by a number of other factors including private communication with company executives and market conditions. A breakdown of model errors indicates disparate performance on calls from different market sectors.