 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVCACHE: A Stateful Tool-Value Cache for Post-Training LLM Agents
Feb 11, 2026In RL post-training of LLM agents, calls to external tools take several seconds or even minutes, leaving allocated GPUs idle and inflating post-training time and cost. While many tool invocations repeat across parallel rollouts and could in principle be cached, naively caching their outputs for reuse is incorrect since tool outputs depend on the environment state induced by prior agent interactions. We present TVCACHE, a stateful tool-value cache for LLM agent post-training. TVCACHE maintains a tree of observed tool-call sequences and performs longest-prefix matching for cache lookups: a hit occurs only when the agent's full tool history matches a previously executed sequence, guaranteeing identical environment state. On three diverse workloads-terminal-based tasks, SQL generation, and video understanding. TVCACHE achieves cache hit rates of up to 70% and reduces median tool call execution time by up to 6.9X, with no degradation in post-training reward accumulation.
Expanding Knowledge Graphs with Humans in the Loop
Dec 10, 2022



Curated knowledge graphs encode domain expertise and improve the performance of recommendation, segmentation, ad targeting, and other machine learning systems in several domains. As new concepts emerge in a domain, knowledge graphs must be expanded to preserve machine learning performance. Manually expanding knowledge graphs, however, is infeasible at scale. In this work, we propose a method for knowledge graph expansion with humans-in-the-loop. Concretely, given a knowledge graph, our method predicts the "parents" of new concepts to be added to this graph for further verification by human experts. We show that our method is both accurate and provably "human-friendly". Specifically, we prove that our method predicts parents that are "near" concepts' true parents in the knowledge graph, even when the predictions are incorrect. We then show, with a controlled experiment, that satisfying this property increases both the speed and the accuracy of the human-algorithm collaboration. We further evaluate our method on a knowledge graph from Pinterest and show that it outperforms competing methods on both accuracy and human-friendliness. Upon deployment in production at Pinterest, our method reduced the time needed for knowledge graph expansion by ~400% (compared to manual expansion), and contributed to a subsequent increase in ad revenue of 20%.
Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
Sep 02, 2021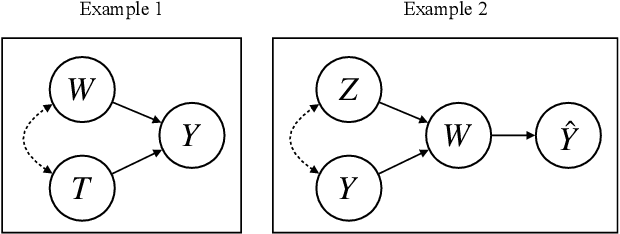
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the remaining challenges. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects, encompassing settings where text is used as an outcome, treatment, or as a means to address confounding. In addition, we explore potential uses of causal inference to improve the performance, robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the computational linguistics community.
Uncovering Latent Biases in Text: Method and Application to Peer Review
Oct 29, 2020
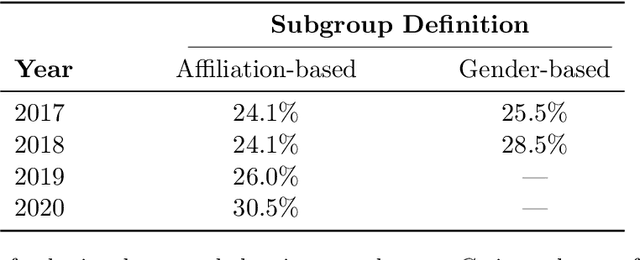
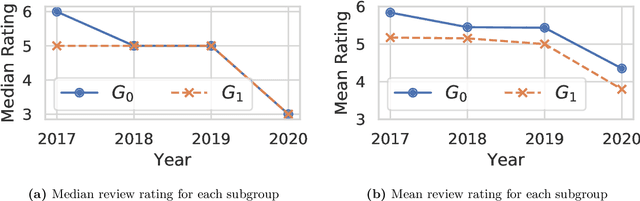

Quantifying systematic disparities in numerical quantities such as employment rates and wages between population subgroups provides compelling evidence for the existence of societal biases. However, biases in the text written for members of different subgroups (such as in recommendation letters for male and non-male candidates), though widely reported anecdotally, remain challenging to quantify. In this work, we introduce a novel framework to quantify bias in text caused by the visibility of subgroup membership indicators. We develop a nonparametric estimation and inference procedure to estimate this bias. We then formalize an identification strategy to causally link the estimated bias to the visibility of subgroup membership indicators, provided observations from time periods both before and after an identity-hiding policy change. We identify an application wherein "ground truth" bias can be inferred to evaluate our framework, instead of relying on synthetic or secondary data. Specifically, we apply our framework to quantify biases in the text of peer reviews from a reputed machine learning conference before and after the conference adopted a double-blind reviewing policy. We show evidence of biases in the review ratings that serves as "ground truth", and show that our proposed framework accurately detects these biases from the review text without having access to the review ratings.
Detecting Attackable Sentences in Arguments
Oct 06, 2020
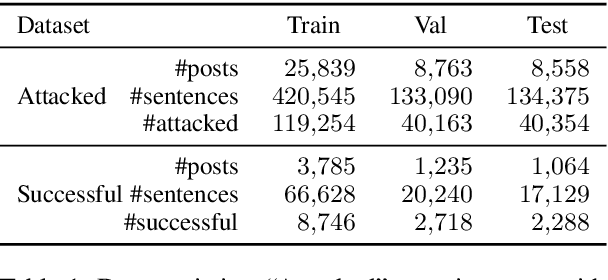


Finding attackable sentences in an argument is the first step toward successful refutation in argumentation. We present a first large-scale analysis of sentence attackability in online arguments. We analyze driving reasons for attacks in argumentation and identify relevant characteristics of sentences. We demonstrate that a sentence's attackability is associated with many of these characteristics regarding the sentence's content, proposition types, and tone, and that an external knowledge source can provide useful information about attackability. Building on these findings, we demonstrate that machine learning models can automatically detect attackable sentences in arguments, significantly better than several baselines and comparably well to laypeople.
Influence via Ethos: On the Persuasive Power of Reputation in Deliberation Online
Jun 01, 2020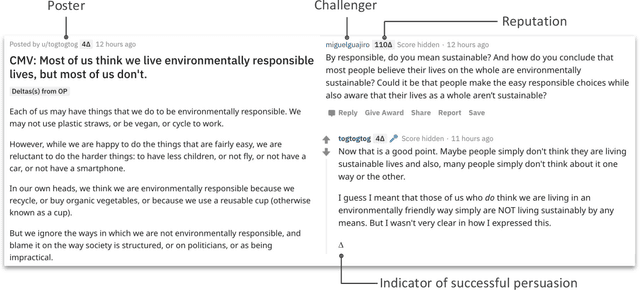
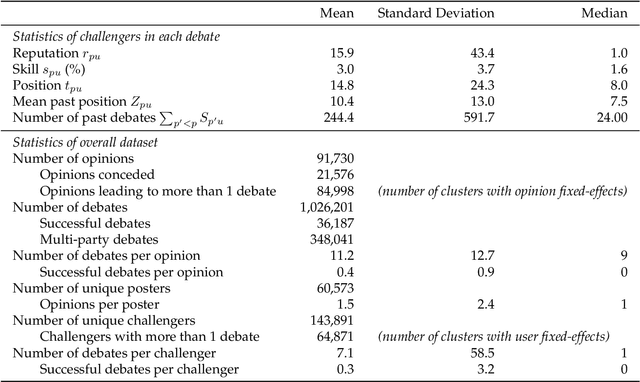
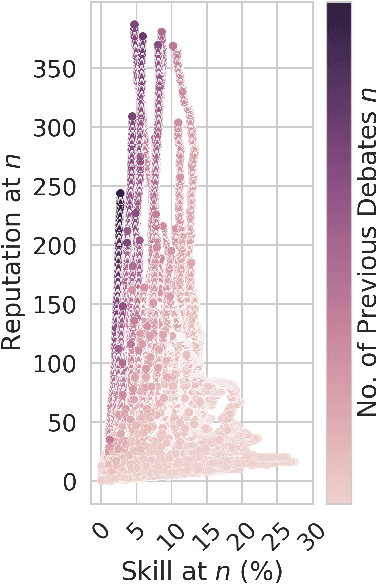
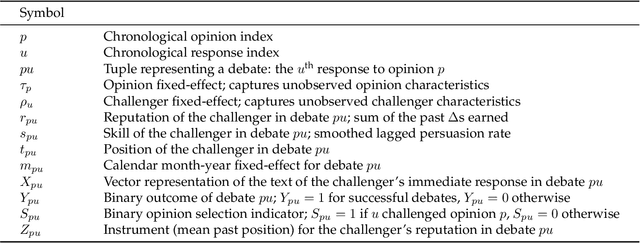
Deliberation among individuals online plays a key role in shaping the opinions that drive votes, purchases, donations and other critical offline behavior. Yet, the determinants of opinion-change via persuasion in deliberation online remain largely unexplored. Our research examines the persuasive power of $\textit{ethos}$ -- an individual's "reputation" -- using a 7-year panel of over a million debates from an argumentation platform containing explicit indicators of successful persuasion. We identify the causal effect of reputation on persuasion by constructing an instrument for reputation from a measure of past debate competition, and by controlling for unstructured argument text using neural models of language in the double machine-learning framework. We find that an individual's reputation significantly impacts their persuasion rate above and beyond the validity, strength and presentation of their arguments. In our setting, we find that having 10 additional reputation points causes a 31% increase in the probability of successful persuasion over the platform average. We also find that the impact of reputation is moderated by characteristics of the argument content, in a manner consistent with a theoretical model that attributes the persuasive power of reputation to heuristic information-processing under cognitive overload. We discuss managerial implications for platforms that facilitate deliberative decision-making for public and private organizations online.