 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
Sep 02, 2021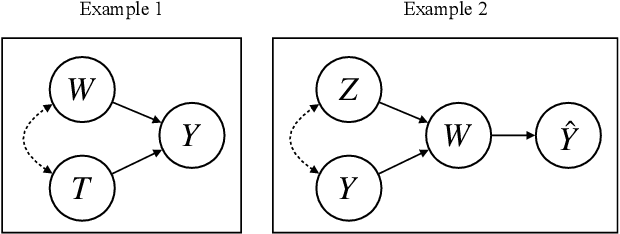
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the remaining challenges. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects, encompassing settings where text is used as an outcome, treatment, or as a means to address confounding. In addition, we explore potential uses of causal inference to improve the performance, robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the computational linguistics community.
Censorship of Online Encyclopedias: Implications for NLP Models
Jan 22, 2021



While artificial intelligence provides the backbone for many tools people use around the world, recent work has brought to attention that the algorithms powering AI are not free of politics, stereotypes, and bias. While most work in this area has focused on the ways in which AI can exacerbate existing inequalities and discrimination, very little work has studied how governments actively shape training data. We describe how censorship has affected the development of Wikipedia corpuses, text data which are regularly used for pre-trained inputs into NLP algorithms. We show that word embeddings trained on Baidu Baike, an online Chinese encyclopedia, have very different associations between adjectives and a range of concepts about democracy, freedom, collective action, equality, and people and historical events in China than its regularly blocked but uncensored counterpart - Chinese language Wikipedia. We examine the implications of these discrepancies by studying their use in downstream AI applications. Our paper shows how government repression, censorship, and self-censorship may impact training data and the applications that draw from them.
How to Make Causal Inferences Using Texts
Feb 06, 2018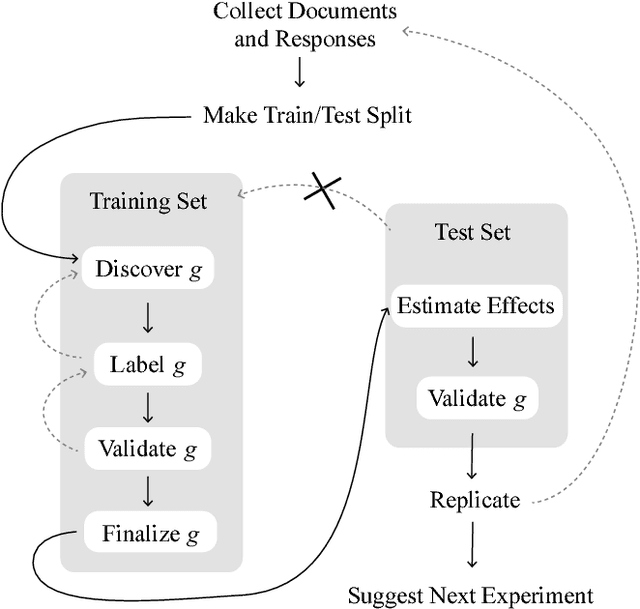
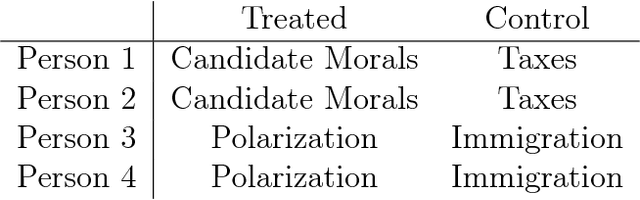

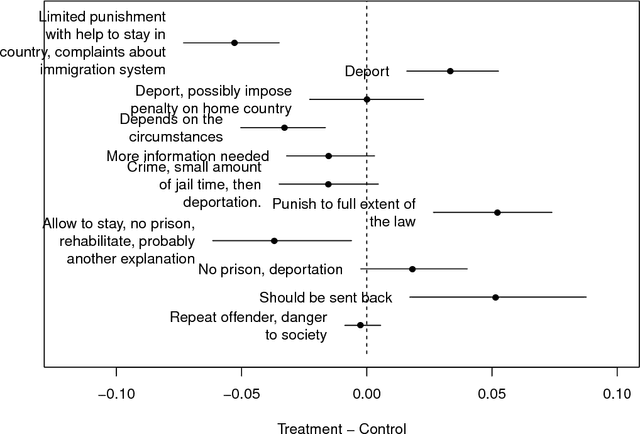
New text as data techniques offer a great promise: the ability to inductively discover measures that are useful for testing social science theories of interest from large collections of text. We introduce a conceptual framework for making causal inferences with discovered measures as a treatment or outcome. Our framework enables researchers to discover high-dimensional textual interventions and estimate the ways that observed treatments affect text-based outcomes. We argue that nearly all text-based causal inferences depend upon a latent representation of the text and we provide a framework to learn the latent representation. But estimating this latent representation, we show, creates new risks: we may introduce an identification problem or overfit. To address these risks we describe a split-sample framework and apply it to estimate causal effects from an experiment on immigration attitudes and a study on bureaucratic response. Our work provides a rigorous foundation for text-based causal inferences.