 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Illusion: Disagreement among LLMs and Its Scientific Consequences
Feb 12, 2026Benchmarks underpin how progress in large language models (LLMs) is measured and trusted. Yet our analyses reveal that apparent convergence in benchmark accuracy can conceal deep epistemic divergence. Using two major reasoning benchmarks - MMLU-Pro and GPQA - we show that LLMs achieving comparable accuracy still disagree on 16-66% of items, and 16-38% among top-performing frontier models. These discrepancies suggest distinct error profiles for different LLMs. When such models are used for scientific data annotation and inference, their hidden disagreements propagate into research results: in re-analyses of published studies in education and political science, switching the annotation model can change estimated treatment effects by more than 80%, and in some cases reverses their sign. Together, these findings illustrate a benchmark illusion, where equal accuracy may conceal disagreement, with model choice becoming a hidden yet consequential variable for scientific reproducibility.
Discovering influential text using convolutional neural networks
Jun 14, 2024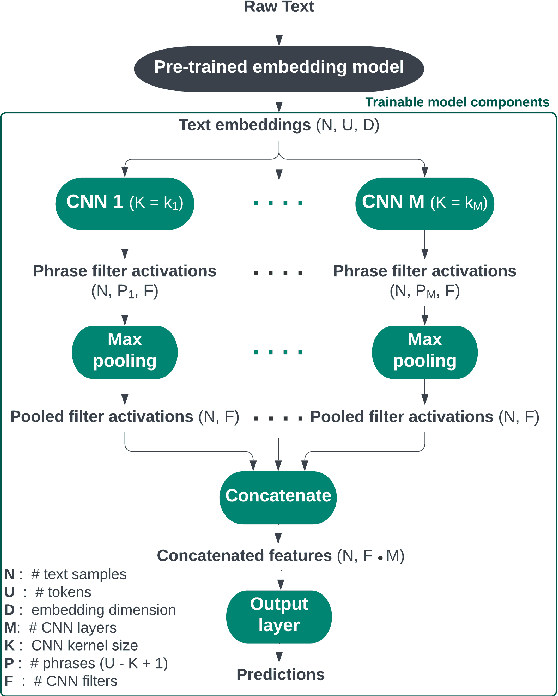

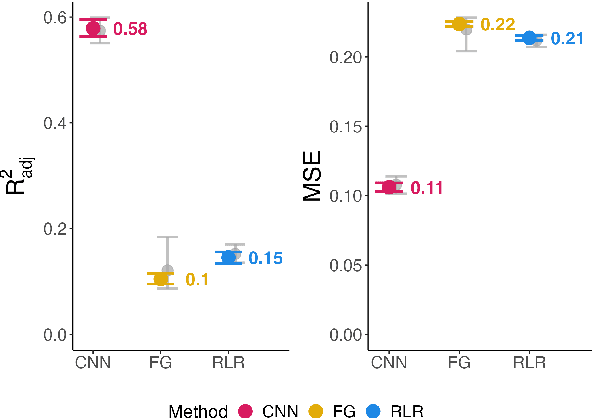
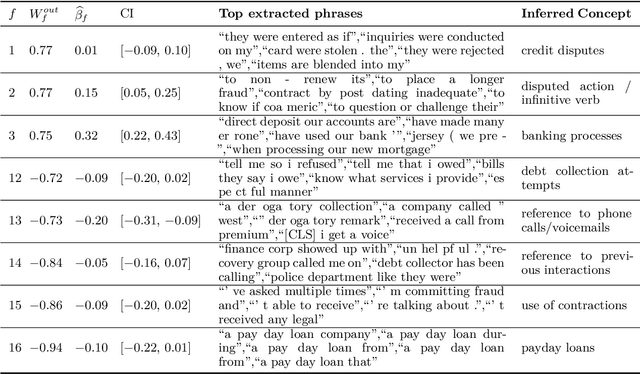
Experimental methods for estimating the impacts of text on human evaluation have been widely used in the social sciences. However, researchers in experimental settings are usually limited to testing a small number of pre-specified text treatments. While efforts to mine unstructured texts for features that causally affect outcomes have been ongoing in recent years, these models have primarily focused on the topics or specific words of text, which may not always be the mechanism of the effect. We connect these efforts with NLP interpretability techniques and present a method for flexibly discovering clusters of similar text phrases that are predictive of human reactions to texts using convolutional neural networks. When used in an experimental setting, this method can identify text treatments and their effects under certain assumptions. We apply the method to two datasets. The first enables direct validation of the model's ability to detect phrases known to cause the outcome. The second demonstrates its ability to flexibly discover text treatments with varying textual structures. In both cases, the model learns a greater variety of text treatments compared to benchmark methods, and these text features quantitatively meet or exceed the ability of benchmark methods to predict the outcome.
Censorship of Online Encyclopedias: Implications for NLP Models
Jan 22, 2021



While artificial intelligence provides the backbone for many tools people use around the world, recent work has brought to attention that the algorithms powering AI are not free of politics, stereotypes, and bias. While most work in this area has focused on the ways in which AI can exacerbate existing inequalities and discrimination, very little work has studied how governments actively shape training data. We describe how censorship has affected the development of Wikipedia corpuses, text data which are regularly used for pre-trained inputs into NLP algorithms. We show that word embeddings trained on Baidu Baike, an online Chinese encyclopedia, have very different associations between adjectives and a range of concepts about democracy, freedom, collective action, equality, and people and historical events in China than its regularly blocked but uncensored counterpart - Chinese language Wikipedia. We examine the implications of these discrepancies by studying their use in downstream AI applications. Our paper shows how government repression, censorship, and self-censorship may impact training data and the applications that draw from them.